Dedicated compute group access
This article explains how to create a compute resource assigned to a group using the Dedicated access mode.
Dedicated group access mode allows users to get the operational efficiency of a standard access mode cluster while also securely supporting languages and workloads that are not supported by standard access mode, such as Databricks Runtime for ML, RDD APIs, and R.
Requirements
To use the dedicated group access mode:
- The workspace must be enabled for Unity Catalog.
- You must use Databricks Runtime 15.4 or above.
- The assigned group must have
CAN MANAGEpermissions on a workspace folder where they can keep notebooks, ML experiments, and other workspace artifacts used by the group cluster.
What is dedicated access mode?
Dedicated access mode is the latest version of single-user access mode. With dedicated access, a compute resource can be assigned to a single user or group, only allowing the assigned user(s) access to use the compute resource.
When a user is connected to a compute resource dedicated to a group (a group cluster), the user's permissions automatically down-scopes to the group's permissions, allowing the user to securely share the resource with the other members of the group.
Create a compute resource dedicated to a group
- In your Databricks workspace, go to Compute and click Create compute.
- Expand the Advanced section.
- Under Access mode, click Manual and then select Dedicated (formerly: Single-user) from the dropdown menu.
- In the Single user or group field, select the group you want assigned to this resource.
- Configure the other desired compute settings, then click Create.
Best practices for managing group clusters
Because user permissions are scoped down to the group when using group clusters, Databricks recommends creating a /Workspace/Groups/<groupName> folder for each group you plan to use with a group cluster. Then, assign CAN MANAGE permissions on the folder to the group. This allows groups to avoid permission errors. All of the group's notebooks and workspace assets should be managed in the group folder.
You must also modify the following workloads to run on group clusters:
- MLflow: Ensure you run the notebook from the group folder or run
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>"). - AutoML: Set the optional
experiment_dirparameter to“/Workspace/Groups/<groupName>”for your AutoML runs. dbutils.notebook.run: Ensure the group hasREADpermission on the notebook being executed.
Permissioning behavior on group clusters
All commands, queries, and other actions performed on a group cluster use the permissions assigned to the group, not the individual user.
Individual user permissions cannot be enforced because all group members have full access to the Spark APIs and shared compute environment. If user-based permissions were applied, one member could query restricted data, and another member without access could still retrieve the results through the shared environment. Therefore, the group itself, not the user who is a member of the group, must have the necessary permissions to successfully perform the action.
For example, the group needs explicit permission to query a table, access a secret scope or secret, use a Unity Catalog connection credential, access a Git folder, or create a workspace object.
Example group permissions
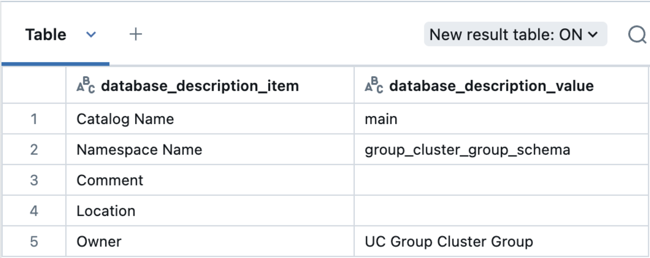
When you create a data object using the group cluster, the group is assigned as the object's owner.
For example, if you have a notebook attached to a group cluster and run the following command:
use catalog main;
create schema group_cluster_group_schema;
Then run this query to check the owner of the schema:
describe schema group_cluster_group_schema;
Auditing group dedicated compute activity
There are two key identities involved when a group cluster runs a workload:
- The user who is running the workload on the group cluster
- The group whose permissions are used to perform the actual workload actions
The audit log system table records these identities under the following parameters:
identity_metadata.run_by: The authenticating user who performs the actionidentity_metadata.run_as: The authorizing group whose permissions are used for the action.
The following example query pulls up the identity metadata for an action taken with the group cluster:
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
View the audit log system table reference for more example queries. See Audit log system table reference.
Known limitations
Dedicated group access has the following limitations:
- Jobs created using the API and SDK cannot be assigned group access. This is because the job's
run_asparameter only supports a single user or service principal. - Jobs that use Git will fail because the temporary directory the job uses to check out the Git repo is not writable. Use Git folders instead.
- Lineage system tables do not record the
identity_metadata.run_as(the authorizing group) oridentity_metadata.run_by(the authenticating user) for workloads that run on a group cluster. - Audit logs delivered to customer storage do not record the
identity_metadata.run_as(the authorizing group) oridentity_metadata.run_by(the authenticating user) for workloads that run on a group cluster. You must use thesystem.access.audittable to view the identity metadata. - When attached to a group cluster, Catalog Explorer does not filter by assets only accessible to the group.
- Group managers who are not group members cannot create, edit, or delete group clusters. Only workspace admins and group members can do so.
- If a group is renamed, you must manually update any compute policies that reference the group name.
- Group clusters are not supported for workspaces with ACLs disabled (isWorkspaceAclsEnabled == false) due to the inherent lack of security and data access controls when workspace ACLs are disabled.
- The
%runcommand and other actions executed in the notebook context always use the user's permissions rather than the group's permissions. This is because these actions are handled by the notebook environment, not the cluster's environment. Alternative commands such asdbutils.notebook.run()are run on the cluster and therefore use the group's permissions. - The
is_member(<group>)function returnsfalsewhen invoked on a group cluster because the group is not a member of itself. To correctly check membership across both group clusters and other access modes, useis_member(<group>) OR current_user() == <group>. - Creating and accessing model serving endpoints is not supported.
- Creating and accessing AI Search endpoints or indexes is not supported.
- File and folder deletion is not supported in group clusters.
- The file upload UI does not support group clusters.