Serverless compute for notebooks
This article explains how to use serverless compute for notebooks. For information on using serverless compute for jobs, see Run your Lakeflow Jobs with serverless compute for workflows.
For pricing information about using serverless compute in notebooks, see Databricks pricing.
Requirements
- Your workspace must be enabled for Unity Catalog.
Attach a notebook to serverless compute
If your workspace is enabled for serverless interactive compute, all users in the workspace have access to serverless compute for notebooks. No additional permissions are required.
To attach to the serverless compute, click the compute drop-down menu in the notebook and select Serverless. For new notebooks, the attached compute automatically defaults to serverless upon code execution if no other resource has been selected.
View query insights
Serverless compute for notebooks and jobs uses query insights to assess Spark execution performance. After running a cell in a notebook, you can view insights related to SQL and Python queries by clicking the See performance link.
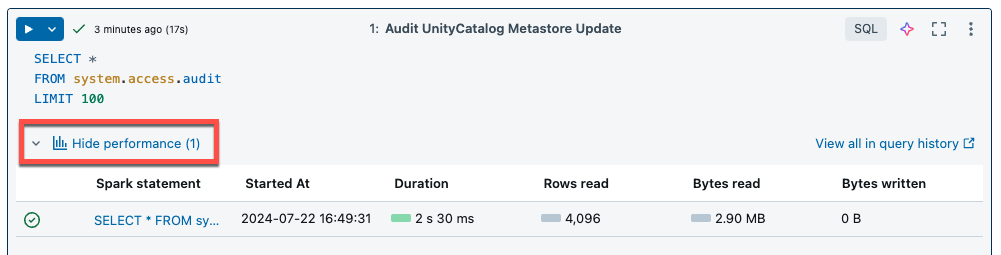
You can click on any of the Spark statements to view the query metrics. From there you can click See query profile to see a visualization of the query execution. For more information on query profiles, see Query profile.
To view performance insights for your job runs, see View job run query insights.
Query history
All queries that are run on serverless compute will also be recorded on your workspace's query history page. For information on query history, see Query history.
Query insight limitations
- Metrics are updated live during query execution, but the complete query profile is only available after the query terminates.
- Only the following query statuses are covered: RUNNING, CANCELED, FAILED, FINISHED.
- Running queries cannot be canceled from the query history page. They can be canceled in notebooks or jobs.
- Verbose metrics are not available.
- Query Profile download is not available.
- Access to the Spark UI is not available.
- The statement text only contains the last line that was run. However, there might be several lines preceding this line that were run as part of the same statement.
Serverless overspend protection
To control long-running queries, serverless notebooks have a default execution timeout of 2.5 hours (9,000 seconds). Queries that exceed the timeout are canceled.
Configure the timeout for all notebooks in the workspace
Workspace admins can change the default execution timeout for serverless notebooks. In the workspace admin settings, go to Settings > Compute and, under Serverless interactive, configure the Serverless interactive execution timeout setting. Changes take approximately 5 minutes to propagate.
Override the timeout for a single notebook
To override the workspace default for an individual notebook, set spark.databricks.execution.timeout in the notebook. The per-notebook value takes precedence over the workspace setting. See Configure Spark properties for serverless notebooks and jobs.