What are Declarative Automation Bundles?
Declarative Automation Bundles (formerly known as Databricks Asset Bundles) are a tool to facilitate the adoption of software engineering best practices, including source control, code review, testing, and continuous integration and delivery (CI/CD), for your data and AI projects. Bundles provide a way to include metadata alongside your project's source files and make it possible to describe Databricks resources such as jobs and pipelines as source files. Ultimately a bundle is an end-to-end definition of a project, including how the project should be structured, tested, and deployed. This makes it easier to collaborate on projects during active development.
Your bundle project's collection of source files and metadata is deployed as a single bundle to your target environment. A bundle includes the following parts:
- Required cloud infrastructure and workspace configurations
- Source files, such as notebooks and Python files, that include the business logic
- Definitions and settings for Databricks resources, such as Lakeflow Jobs, Lakeflow pipelines, Dashboards, Model Serving endpoints, MLflow Experiments, and MLflow registered models
- Unit tests and integration tests
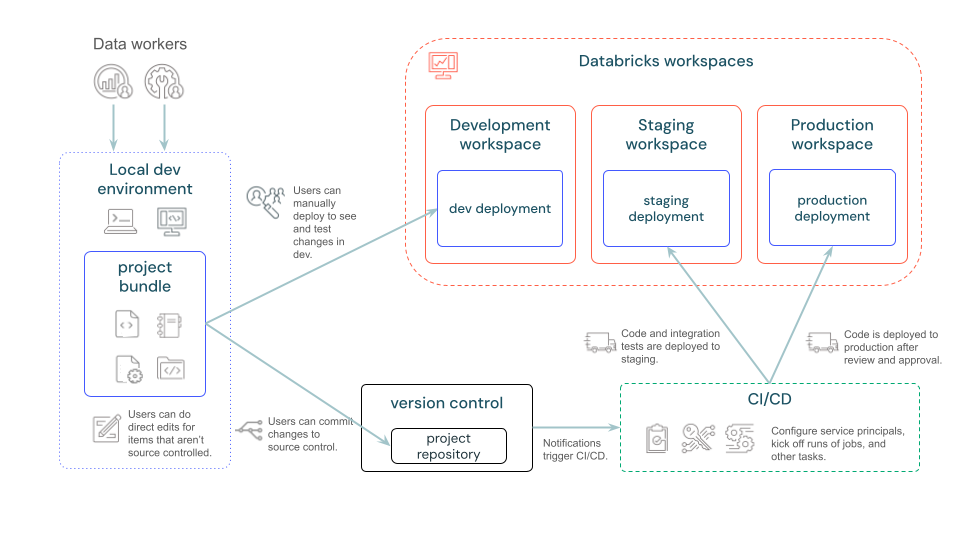
The following diagram provides a high-level view of a development and CI/CD pipeline with bundles:
Video walkthrough
This video demonstrates how to work with Declarative Automation Bundles (5 minutes).
When should I use bundles?
Declarative Automation Bundles are an infrastructure-as-code (IaC) approach to managing your Databricks projects. Use them when you want to manage complex projects where multiple contributors and automation are essential, and continuous integration and deployment (CI/CD) are a requirement. Since bundles are defined and managed through YAML templates and files you create and maintain alongside source code, they map well to scenarios where IaC is an appropriate approach.
Some ideal scenarios for bundles include:
- Develop data, analytics, and ML projects in a team-based environment. Bundles can help you organize and manage various source files efficiently. This ensures smooth collaboration and streamlined processes.
- Iterate on ML problems faster. Manage ML pipeline resources (such as training and batch inference jobs) by using ML projects that follow production best practices from the beginning.
- Set organizational standards for new projects by authoring custom bundle templates that include default permissions, service principals, and CI/CD configurations.
- Regulatory compliance: In industries where regulatory compliance is a significant concern, bundles can help maintain a versioned history of code and infrastructure work. This assists in governance and ensures that necessary compliance standards are met.
How do bundles work?
Bundle metadata is defined using YAML files that specify the artifacts, resources, and configuration of a Databricks project. The Databricks CLI can then be used to validate, deploy, and run bundles using these bundle YAML files. You can run bundle projects from IDEs, terminals, or within Databricks directly.
Bundles can be created manually or based on a template. The Databricks CLI provides default templates for simple use cases, but for more specific or complex jobs, you can create custom bundle templates to implement your team's best practices and keep common configurations consistent.
For more details on the configuration YAML used to express Declarative Automation Bundles, see Declarative Automation Bundles configuration.
What do I need to install to use bundles?
Declarative Automation Bundles are a feature of the Databricks CLI. You build bundles locally, then use the Databricks CLI to deploy your bundles to target remote Databricks workspaces and run bundle workflows in those workspaces from the command line.
If you just want to use bundles in the workspace, you do not need to install the Databricks CLI . See Collaborate on bundles in the workspace.
To build, deploy, and run bundles in your Databricks workspaces:
-
Your remote Databricks workspaces must have workspace files enabled. If you're using Databricks Runtime version 11.3 LTS or above, this feature is enabled by default.
-
You must install the Databricks CLI, version v0.218.0 or above. To install or update the Databricks CLI, see Install or update the Databricks CLI.
Databricks recommends that you regularly update to the latest version of the CLI to take advantage of new bundle features. To find the version of the Databricks CLI that is installed, run the following command:
shdatabricks --version -
You have configured the Databricks CLI to access your Databricks workspaces. Databricks recommends configuring access using OAuth user-to-machine (U2M) authentication, which is described in Configure access to your workspace. Other authentication methods are described in Authentication for Declarative Automation Bundles.
How do I get started with bundles?
The fastest way to start local bundle development is using a bundle project template. Create your first bundle project using the Databricks CLI bundle init command. This command presents a choice of Databricks-provided default bundle templates and asks a series of questions to initialize project variables.
databricks bundle init
Creating your bundle is the first step in the lifecycle of a bundle. Next, develop your bundle by defining bundle settings and resources in the databricks.yml and resource configuration files. Finally, validate and deploy your bundle, then run your workflows.
Bundle configuration examples can be found in Bundle configuration examples and the Bundle examples repository in GitHub.
Next steps
- Create a bundle that deploys a notebook to a Databricks workspace and then runs that deployed notebook in a Databricks job or pipeline. See Develop a job with Declarative Automation Bundles and Develop pipelines with Declarative Automation Bundles.
- Create a bundle that deploys and runs an MLOps Stack. See Declarative Automation Bundles for MLOps Stacks.
- Kick off a bundle deployment as part of a CI/CD (continuous integration/continuous deployment) workflow in GitHub. See Run a CI/CD workflow with a bundle that runs a pipeline update.
- Create a bundle that builds, deploys, and calls a Python wheel file. See Build a Python wheel file using Declarative Automation Bundles.
- Generate configuration in your bundle for a job or other resource in your workspace, then bind it to the resource in the workspace so that configuration stays in sync. See databricks bundle generate and databricks bundle deployment bind.
- Create and deploy a bundle in the workspace. See Collaborate on bundles in the workspace.
- Create a custom template that you and others can use to create a bundle. A custom template might include default permissions, service principals, and custom CI/CD configuration. See Declarative Automation Bundles project templates.
- Migrate from dbx to Declarative Automation Bundles. See Migrate from dbx to bundles.
- Discover the latest major new features released for Declarative Automation Bundles. See Declarative Automation Bundles feature release notes.