Troubleshoot evaluation (MLflow 2)
This article describes issues you might encounter when evaluating generative AI applications using Mosaic AI Agent Evaluation, and how to fix them.
Model errors
mlflow.evaluate(..., model=<model>, model_type="databricks-agent") invokes the provided model on each row of the evaluation set. Model invocation might fail, for example, if the generative model is temporarily unavailable. If this occurs, the output includes the following lines, where n is the total number of rows evaluated and k is the number of rows with an error:
**Evaluation completed**
- k/n contain model errors
This error appears in the MLFlow UI when you view the details of a particular row of the evaluation set.
You can also view the error in the evaluation results DataFrame. In this case, you see rows in the evaluation results containing model_error_message. To view these errors, using the following code snippet:
result = mlflow.evaluate(..., model=<your model>, model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
display(eval_results_df[eval_results_df['model_error_message'].notna()][['request', 'model_error_message']])

If the error is recoverable, you can re-run evaluation on just the failed rows:
result = mlflow.evaluate(..., model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
# Filter rows where 'model_error_message' is not null and select columns required for evaluation.
input_cols = ['request_id', 'request', 'expected_retrieved_context', 'expected_response']
retry_df = eval_results_df.loc[
eval_results_df['model_error_message'].notna(),
[col for col in input_cols if col in eval_results_df.columns]
]
retry_result = mlflow.evaluate(
data=retry_df,
model=<your model>,
model_type="databricks-agent"
)
retry_result_df = retry_result.tables['eval_results']
merged_results_df = eval_results_df.set_index('request_id').combine_first(
retry_result.tables['eval_results'].set_index('request_id')
).reset_index()
# Reorder the columns to match the original eval_results_df column order
merged_results_df = merged_results_df[eval_results_df.columns]
display(merged_results_df)
The re-run of mlflow.evaluate logs results and aggregates metrics to a new MLflow run. The merged DataFrame generated above can be viewed in the notebook.
Judge errors
mlflow.evaluate(..., model_type="databricks-agent") evaluates model outputs using built-in judges and, optionally, your custom judges. Judges might fail to evaluate a row of input data, for example, due to TOKEN_RATE_LIMIT_EXCEEDED or MISSING_INPUT_FIELDS.
If a judge fails to evaluate a row, the output includes the following lines, where n is the total number of rows evaluated and k is the number of rows with an error:
**Evaluation completed**
- k/n contain judge errors
This error will be displayed in the MLFlow UI. Upon clicking into a particular evaluation, judge errors will be displayed under their corresponding assessment names.

In this case, you see rows in the evaluation results containing <judge_name>/error_message, for example, response/llm_judged/faithfulness/error_message. You can view these errors using the following code snippet:
result = mlflow.evaluate(..., model=<your model>, model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
llm_judges_error_columns = [col for col in eval_results_df.columns if 'llm_judged' in col and 'error_message' in col]
columns_to_display = ['request_id', 'request'] + llm_judges_error_columns
# Display the filtered DataFrame
display(eval_results_df[eval_results_df[llm_judges_error_columns].notna().any(axis=1)][columns_to_display])
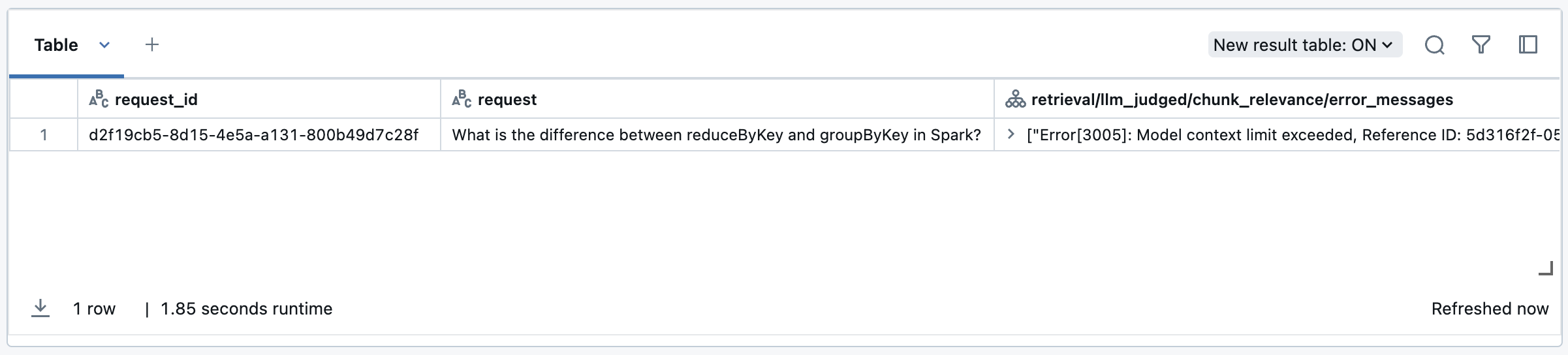
After the error is resolved, or if it is recoverable, you can re-run evaluation on just the rows with failures by following this example:
result = mlflow.evaluate(..., model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
llm_judges_error_columns = [col for col in eval_results_df.columns if 'llm_judges' in col and 'error_message' in col]
input_cols = ['request_id', 'request', 'expected_retrieved_context', 'expected_response']
retry_df = eval_results_df.loc[
eval_results_df[llm_judges_error_columns].notna().any(axis=1),
[col for col in input_cols if col in eval_results_df.columns]
]
retry_result = mlflow.evaluate(
data=retry_df,
model=<your model>,
model_type="databricks-agent"
)
retry_result_df = retry_result.tables['eval_results']
merged_results_df = eval_results_df.set_index('request_id').combine_first(
retry_result_df.set_index('request_id')
).reset_index()
merged_results_df = merged_results_df[eval_results_df.columns]
display(merged_results_df)
The re-run of mlflow.evaluate logs results and aggregates metrics to a new MLflow run. The merged DataFrame generated above can be viewed in the notebook.
Common errors
If you continue to encounter these error codes, reach out to your Databricks account team. The following lists common error code definitions and how to resolve them
Error code | What it means | Resolution |
|---|---|---|
1001 | Missing input fields | Review and update required input fields. |
1002 | Missing fields in few shot prompts | Review and update required input fields of the provided few-shot examples. See Create few-shot examples. |
1005 | Invalid fields in few shot prompts | Review and update required input fields of the provided few-shot examples. See Create few-shot examples. |
3001 | Dependency timeout | Review logs and try re-running your agent. Reach out to your Databricks account team if the timeout persists. |
3003 | Dependency rate limit exceeded | Reach out to your Databricks account team. |
3004 | Token rate limit exceeded | Reach out to your Databricks account team. |
3006 | Partner-powered AI features are disabled. | Enable partner-powered AI features. See Information about the models powering LLM judges. |