Troubleshoot SQL Server ingestion
This page describes common issues with the Microsoft SQL Server connector in Databricks Lakeflow Connect and how to resolve them.
General pipeline troubleshooting
The troubleshooting steps in this section apply to all ingestion pipelines in Lakeflow Connect.
If a pipeline fails while executing, click on the step that failed and confirm whether the error message provides sufficient information about the nature of the error.

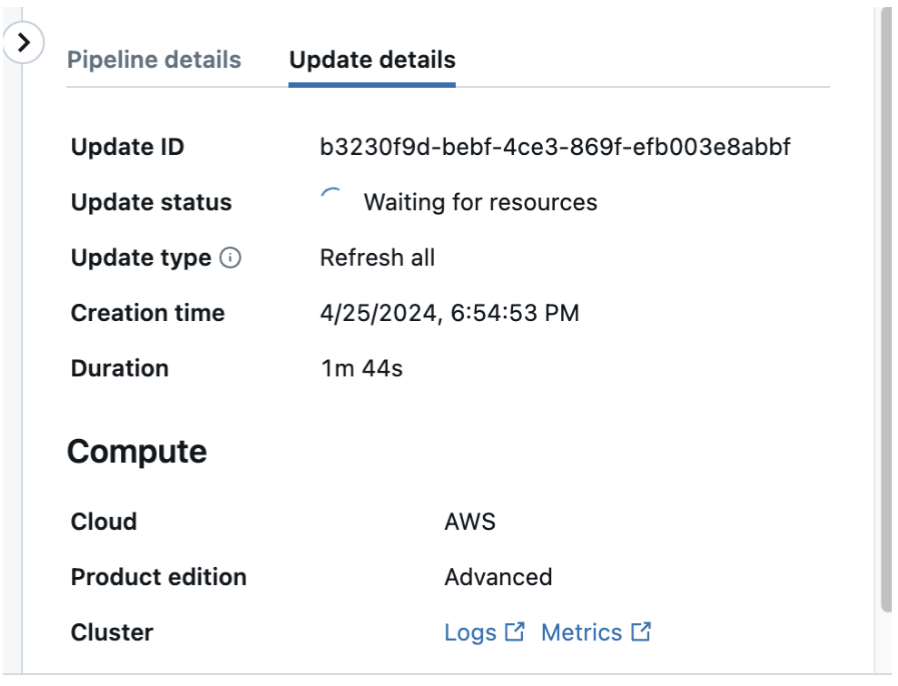
You can also check and download the cluster logs from the pipeline details page by clicking Update details in the right-hand panel, then Logs. Scan the logs for errors or exceptions.
Check if CDC is enabled for a database or a table
To check if CDC is enabled for database <database-name>:
select is_cdc_enabled from sys.databases where name='<database-name>';
To check if CDC is enabled for table <schema-name>.<table-name>:
select t.is_tracked_by_cdc
from sys.tables t join sys.schemas s on t.schema_id = s.schema_id
where s.name='<schema-name>' and t.name='<table-name>';
Check if change tracking is enabled for a database or a table
To check if change tracking is enabled for database\<database-name\>:
select ctdb.*
from sys.change_tracking_databases ctdb join sys.databases db
on db.database_id = ctdb.database_id
where db.name = '<MyDatabaseName>'
To check if change tracking is enabled for table <schema-name>.<table-name>:
select s.name schema_name, t.name table_name, ct.*
from sys.change_tracking_tables ct join sys.tables t
on ct.object_id = t.object_id
join sys.schemas s on t.schema_id = s.schema_id
where s.name = '<MySchemaName>' and t.name = '<MyTableName>'
Time out on waiting for table token
The ingestion pipeline might time out while waiting for information to be provided by the gateway. This might be because:
- You are running an older version of the gateway.
- There was an error generating the necessary information. Check the gateway driver logs for errors.
The full refresh flow significantly reduces the occurrence of timeout errors during full refresh operations. See Full refresh behavior (CDC).
default auth: cannot configure default credentials
If you receive this error, there is an issue with discovering the current user credentials. Try replacing the following:
w = WorkspaceClient()
with:
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
See Authentication in the Databricks SDK for Python documentation.
tech.replicant.common.ExtractorException: com.microsoft.sqlserver.jdbc.SQLServerException: Invalid column name 'SERIAL_NUMBER'.
You might receive this error if you're using an older version of an internal table. Run the following on the connected database:
drop table dbo.replicate_io_audit_ddl_trigger_1;
PERMISSION_DENIED: You are not authorized to create clusters. Please contact your administrator.
Contact a Databricks account admin to grant you Unrestricted cluster creation permissions.
DLT ERROR CODE: INGESTION_GATEWAY_INTERNAL_ERROR
Check the stdout file(s) in the driver logs.
Source table naming conflict
Ingestion pipeline error: “org.apache.spark.sql.catalyst.ExtendedAnalysisException: Cannot have multiple queries named `XYZ_snapshot_load` for `XYZ`. Additional queries on that table must be named. Note that unnamed queries default to the same name as the table.
This indicates that there is a name conflict due to multiple source tables named XYZ in different source schemas that are being ingested by the same ingestion pipeline to the same destination schema.
Create multiple gateway-pipeline pairs writing these conflicting tables to different destination schemas.
Incompatible schema changes
An incompatible schema change causes the ingestion pipeline to fail with an INCOMPATIBLE_SCHEMA_CHANGE error. To continue replication, trigger a full refresh of the affected tables.
Databricks can not guarantee that at time the ingestion pipeline fails for an incompatible schema change, all rows prior to the schema change have been ingested.