HorovodRunner: distributed deep learning with Horovod
Horovod and HorovodRunner are now deprecated. Releases after 15.4 LTS ML will not have this package pre-installed. For distributed deep learning, Databricks recommends using TorchDistributor for distributed training with PyTorch or the tf.distribute.Strategy API for distributed training with TensorFlow.
Learn how to perform distributed training of machine learning models using HorovodRunner to launch Horovod training jobs as Spark jobs on Databricks.
What is HorovodRunner?
HorovodRunner is a general API to run distributed deep learning workloads on Databricks using the Horovod framework. By integrating Horovod with Spark's barrier mode, Databricks is able to provide higher stability for long-running deep learning training jobs on Spark. HorovodRunner takes a Python method that contains deep learning training code with Horovod hooks. HorovodRunner pickles the method on the driver and distributes it to Spark workers. A Horovod MPI job is embedded as a Spark job using the barrier execution mode. The first executor collects the IP addresses of all task executors using BarrierTaskContext and triggers a Horovod job using mpirun. Each Python MPI process loads the pickled user program, deserializes it, and runs it.
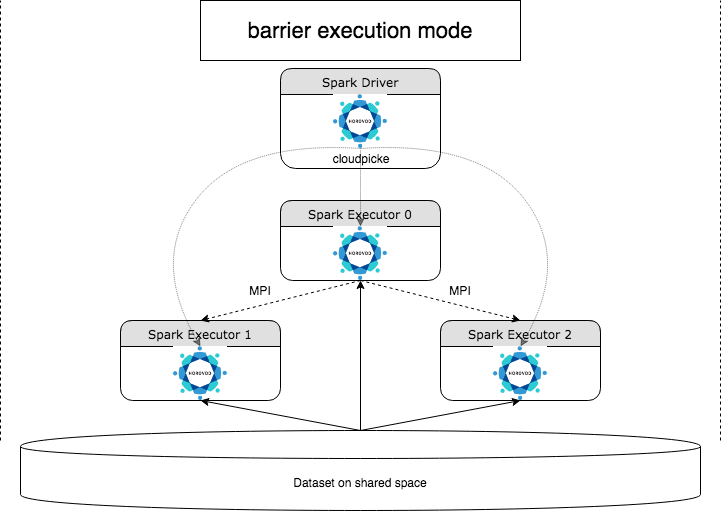
Distributed training with HorovodRunner
HorovodRunner lets you launch Horovod training jobs as Spark jobs. The HorovodRunner API supports the methods shown in the table. For details, see the HorovodRunner API documentation.
Method and signature | Description |
|---|---|
| Create an instance of HorovodRunner. |
** | Run a Horovod training job invoking |
The general approach to developing a distributed training program using HorovodRunner is:
- Create a
HorovodRunnerinstance initialized with the number of nodes. - Define a Horovod training method according to the methods described in Horovod usage, making sure to add any import statements inside the method.
- Pass the training method to the
HorovodRunnerinstance.
For example:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
To run HorovodRunner on the driver only with n subprocesses, use hr = HorovodRunner(np=-n). For example, if there are 4 GPUs on the driver node, you can choose n up to 4. For details about the parameter np, see the HorovodRunner API documentation. For details about how to pin one GPU per subprocess, see the Horovod usage guide.
A common error is that TensorFlow objects cannot be found or pickled. This happens when the library import statements are not distributed to other executors. To avoid this issue, include all import statements (for example, import tensorflow as tf) both at the top of the Horovod training method and inside any other user-defined functions called in the Horovod training method.
Record Horovod training with Horovod Timeline
Horovod has the ability to record the timeline of its activity, called Horovod Timeline.
Horovod Timeline has a significant impact on performance. Inception3 throughput can decrease by ~40% when Horovod Timeline is enabled. To speed up HorovodRunner jobs, do not use Horovod Timeline.
You cannot view the Horovod Timeline while training is in progress.
To record a Horovod Timeline, set the HOROVOD_TIMELINE environment variable to the location where you want to save the timeline file. Databricks recommends using a location on shared storage so that the timeline file can be easily retrieved. For example, you can use DBFS local file APIs as shown:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Then, add timeline specific code to the beginning and end of the training function. The following example notebook includes example code that you can use as a workaround to view training progress.
Horovod timeline example notebook
To download the timeline file, use the Databricks CLI, and then use the Chrome browser's chrome://tracing facility to view it. For example:
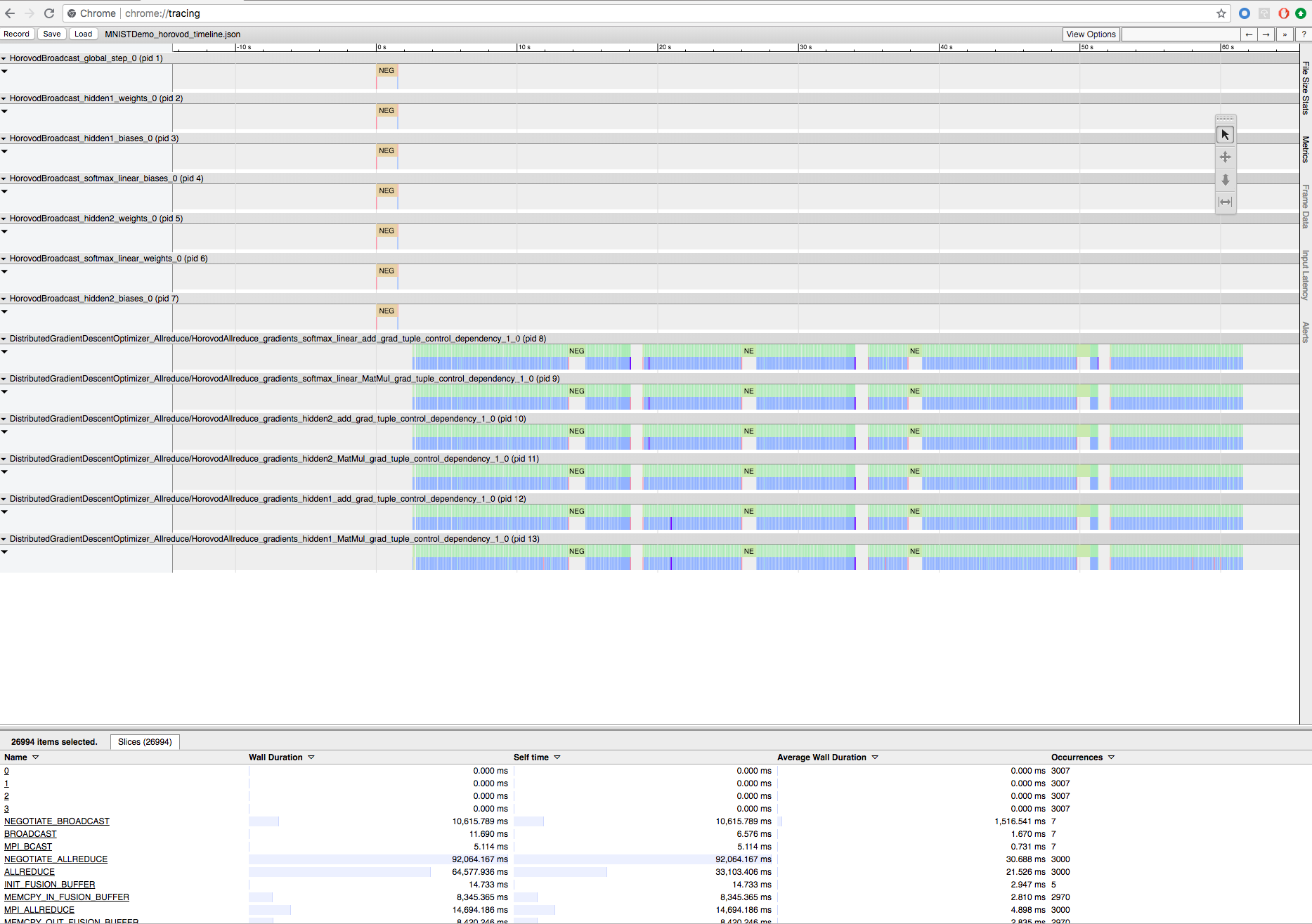
Development workflow
These are the general steps in migrating single node deep learning code to distributed training. The Examples: Migrate to distributed deep learning with HorovodRunner in this section illustrate these steps.
- Prepare single node code: Prepare and test the single node code with TensorFlow, Keras, or PyTorch.
- Migrate to Horovod: Follow the instructions from Horovod usage to migrate the code with Horovod and test it on the driver:
- Add
hvd.init()to initialize Horovod. - Pin a server GPU to be used by this process using
config.gpu_options.visible_device_list. With the typical setup of one GPU per process, this can be set to local rank. In that case, the first process on the server will be allocated the first GPU, second process will be allocated the second GPU and so forth. - Include a shard of the dataset. This dataset operator is very useful when running distributed training, as it allows each worker to read a unique subset.
- Scale the learning rate by number of workers. The effective batch size in synchronous distributed training is scaled by the number of workers. Increasing the learning rate compensates for the increased batch size.
- Wrap the optimizer in
hvd.DistributedOptimizer. The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies the averaged gradients. - Add
hvd.BroadcastGlobalVariablesHook(0)to broadcast initial variable states from rank 0 to all other processes. This is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint. Alternatively, if you're not usingMonitoredTrainingSession, you can execute thehvd.broadcast_global_variablesoperation after global variables have been initialized. - Modify your code to save checkpoints only on worker 0 to prevent other workers from corrupting them.
- Add
- Migrate to HorovodRunner: HorovodRunner runs the Horovod training job by invoking a Python function. You must wrap the main training procedure into a single Python function. Then you can test HorovodRunner in local mode and distributed mode.
Update the deep learning libraries
If you upgrade or downgrade TensorFlow, Keras, or PyTorch, you must reinstall Horovod so that it is compiled against the newly installed library. For example, if you want to upgrade TensorFlow, Databricks recommends using the init script from the TensorFlow installation instructions and appending the following TensorFlow specific Horovod installation code to the end of it. See Horovod installation instructions to work with different combinations, such as upgrading or downgrading PyTorch and other libraries.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Examples: Migrate to distributed deep learning with HorovodRunner
The following examples, based on the MNIST dataset, demonstrate how to migrate a single-node deep learning program to distributed deep learning with HorovodRunner.
- Deep learning using TensorFlow with HorovodRunner for MNIST
- Adapt single node PyTorch to distributed deep learning
Limitations
- When working with workspace files, HorovodRunner will not work if
npis set to greater than 1 and the notebook imports from other relative files. Consider using horovod.spark instead ofHorovodRunner. - If you come across errors like
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer, this indicates a problem with network communication among nodes in your cluster. To resolve this error, add the following snippet in your training code to use the primary network interface.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"