Log, load, and register MLflow models
An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools—for example, batch inference on Apache Spark or real-time serving through a REST API. The format defines a convention that lets you save a model in different flavors (python-function, pytorch, sklearn, and so on), that can be understood by different model serving and inference platforms.
To learn how to log and score a streaming model, see How to save and load a streaming model.
MLflow 3 introduces significant enhancements to MLflow models by introducing a new, dedicated LoggedModel object with its own metadata such as metrics and parameters. For more details, see Track and compare models using MLflow Logged Models.
Log and load models
When you log a model, MLflow automatically logs requirements.txt and conda.yaml files. You can use these files to recreate the model development environment and reinstall dependencies using virtualenv (recommended) or conda.
Anaconda Inc. updated their terms of service for anaconda.org channels. Based on the new terms of service you may require a commercial license if you rely on Anaconda's packaging and distribution. See Anaconda Commercial Edition FAQ for more information. Your use of any Anaconda channels is governed by their terms of service.
MLflow models logged before v1.18 (Databricks Runtime 8.3 ML or earlier) were by default logged with the conda defaults channel (https://repo.anaconda.com/pkgs/) as a dependency. Because of this license change, Databricks has stopped the use of the defaults channel for models logged using MLflow v1.18 and above. The default channel logged is now conda-forge, which points at the community managed https://conda-forge.org/.
If you logged a model before MLflow v1.18 without excluding the defaults channel from the conda environment for the model, that model may have a dependency on the defaults channel that you may not have intended.
To manually confirm whether a model has this dependency, you can examine channel value in the conda.yaml file that is packaged with the logged model. For example, a model's conda.yaml with a defaults channel dependency may look like this:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Because Databricks can not determine whether your use of the Anaconda repository to interact with your models is permitted under your relationship with Anaconda, Databricks is not forcing its customers to make any changes. If your use of the Anaconda.com repo through the use of Databricks is permitted under Anaconda's terms, you do not need to take any action.
If you would like to change the channel used in a model's environment, you can re-register the model to the model registry with a new conda.yaml. You can do this by specifying the channel in the conda_env parameter of log_model().
For more information on the log_model() API, see the MLflow documentation for the model flavor you are working with, for example, log_model for scikit-learn.
For more information on conda.yaml files, see the MLflow documentation.
API commands
To log a model to the MLflow tracking server, use mlflow.<model-type>.log_model(model, ...).
To load a previously logged model for inference or further development, use mlflow.<model-type>.load_model(modelpath), where modelpath is one of the following:
- a model path (such as
models:/{model_id}) (MLflow 3 only) - a run-relative path (such as
runs:/{run_id}/{model-path}) - a Unity Catalog volumes path (such as
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - an MLflow-managed artifact storage path beginning with
dbfs:/databricks/mlflow-tracking/ - a registered model path (such as
models:/{model_name}/{model_stage}).
For Python MLflow models, an additional option is to use mlflow.pyfunc.load_model() to load the model as a generic Python function.
You can use the following code snippet to load the model and score data points.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
As an alternative, you can export the model as an Apache Spark UDF to use for scoring on a Spark cluster, either as a batch job or as a real-time Spark Streaming job.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Log model dependencies
To accurately load a model, you should make sure the model dependencies are loaded with the correct versions into the notebook environment. In Databricks Runtime 10.5 ML and above, MLflow warns you if a mismatch is detected between the current environment and the model's dependencies.
Additional functionality to simplify restoring model dependencies is included in Databricks Runtime 11.0 ML and above. In Databricks Runtime 11.0 ML and above, for pyfunc flavor models, you can call mlflow.pyfunc.get_model_dependencies to retrieve and download the model dependencies. This function returns a path to the dependencies file which you can then install by using %pip install <file-path>. When you load a model as a PySpark UDF, specify env_manager="virtualenv" in the mlflow.pyfunc.spark_udf call. This restores model dependencies in the context of the PySpark UDF and does not affect the outside environment.
You can also use this functionality in Databricks Runtime 10.5 or below by manually installing MLflow version 1.25.0 or above:
%pip install "mlflow>=1.25.0"
For additional information on how to log model dependencies (Python and non-Python) and artifacts, see Log model dependencies.
Learn how to log model dependencies and custom artifacts for model serving:
- Deploy models with dependencies
- Use custom Python libraries with Model Serving
- Package custom artifacts for Model Serving
Automatically generated code snippets in the MLflow UI
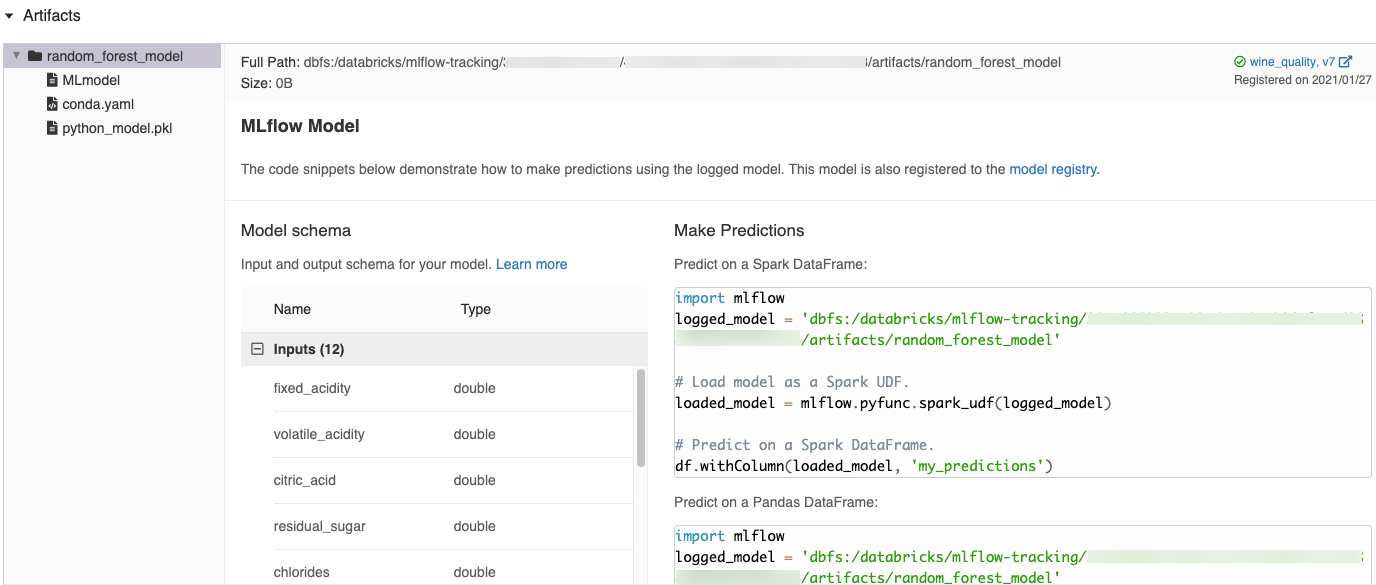
When you log a model in a Databricks notebook, Databricks automatically generates code snippets that you can copy and use to load and run the model. To view these code snippets:
- Navigate to the Runs screen for the run that generated the model. (See View notebook experiment for how to display the Runs screen.)
- Scroll to the Artifacts section.
- Click the name of the logged model. A panel opens to the right showing code you can use to load the logged model and make predictions on Spark or pandas DataFrames.
Examples
For examples of logging models, see the examples in Track machine learning training runs examples.
Register models in the Model Registry
You can register models in the MLflow Model Registry, a centralized model store that provides a UI and set of APIs to manage the full lifecycle of MLflow Models. For instructions on how to use the Model Registry to manage models in Databricks Unity Catalog, see Manage model lifecycle in Unity Catalog. To use the Workspace Model Registry, see Manage model lifecycle using the Workspace Model Registry (legacy).
When models created with MLflow 3 are registered to the Unity Catalog model registry, you can view data such as parameters and metrics in one central location, across all experiments and workspaces. For information, see Model Registry improvements with MLflow 3.
To register a model using the API, use the following command:
- MLflow 3
- MLflow 2.x
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Save models to Unity Catalog volumes
To save a model locally, use mlflow.<model-type>.save_model(model, modelpath). modelpath must be a Unity Catalog volumes path. For example, if you use a Unity Catalog volumes location /Volumes/catalog_name/schema_name/volume_name/my_project_models to store your project work, you must use the model path /Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
For MLlib models, use ML Pipelines.
Download model artifacts
You can download the logged model artifacts (such as model files, plots, and metrics) for a registered model with various APIs.
Python API example:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Java API example:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI command example:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Deploy models for online serving
Prior to deploying your model, it is beneficial to verify that the model is capable of being served. See the MLflow documentation for how you can use mlflow.models.predict to validate models before deployment.
Use Model Serving to host machine learning models registered in Unity Catalog model registry as REST endpoints. These endpoints are updated automatically based on the availability of model versions.