Share code between Databricks notebooks
This article describes how to use files to modularize your code, including how to create and import Python files.
Databricks also supports multi-task jobs which allow you to combine notebooks into workflows with complex dependencies. For more information, see Lakeflow Jobs.
Modularize your code using files
With Databricks Runtime 11.3 LTS and above, you can create and manage source code files in the Databricks workspace, and then import these files into your notebooks as needed. You can also use a Databricks repo to sync your files with a Git repository. For details, see Work with Python and R modules and Databricks Git folders.
Create a Python file
To create a file:
- In the left sidebar, click Workspace.
- Click Create > File. The file will open in an editor window and changes are saved automatically.
- Enter a name for the file ending in
.py.
Import a file into a notebook
You can import a file into a notebook using standard Python import commands:
Suppose you have the following file:
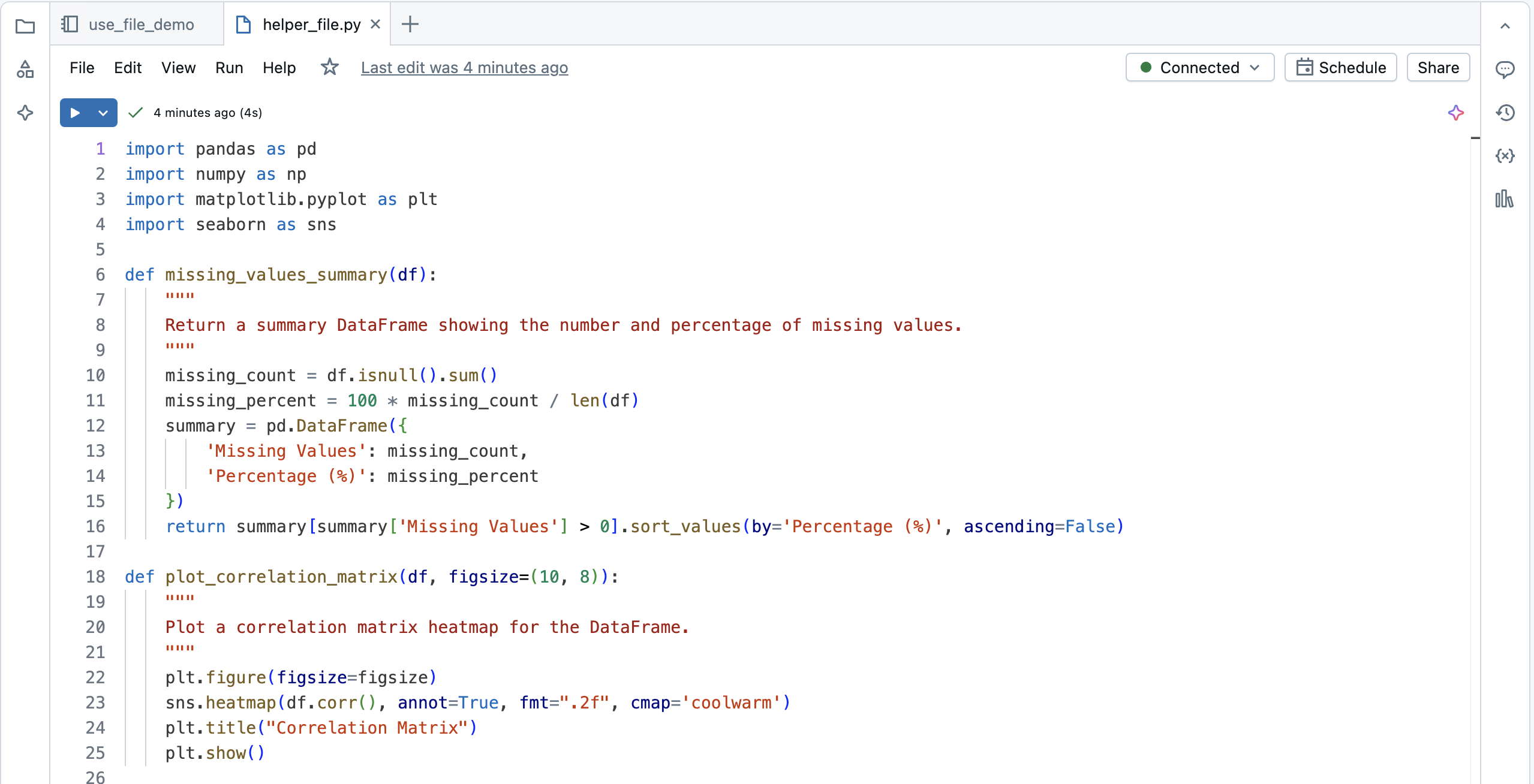
You can import that file into a notebook and call the functions defined in the file:
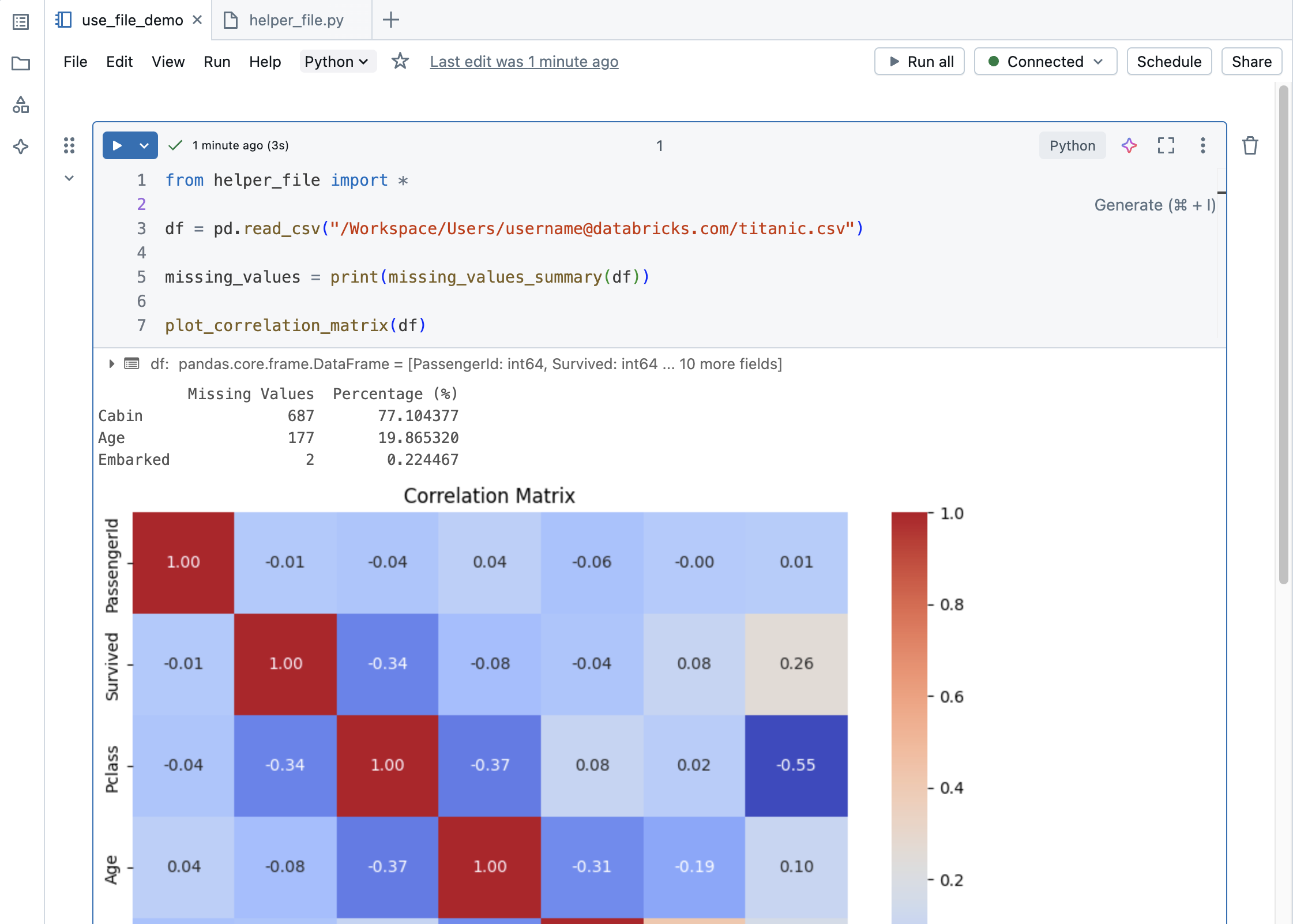
Import a file from another folder into a notebook
If a helper file is in another folder, you need to use the full file path. To copy the full path, navigate to the file in your workspace and in the kebab menu, click Copy URL/path > Full path.
You can import a file from a different folder into a notebook as follows:
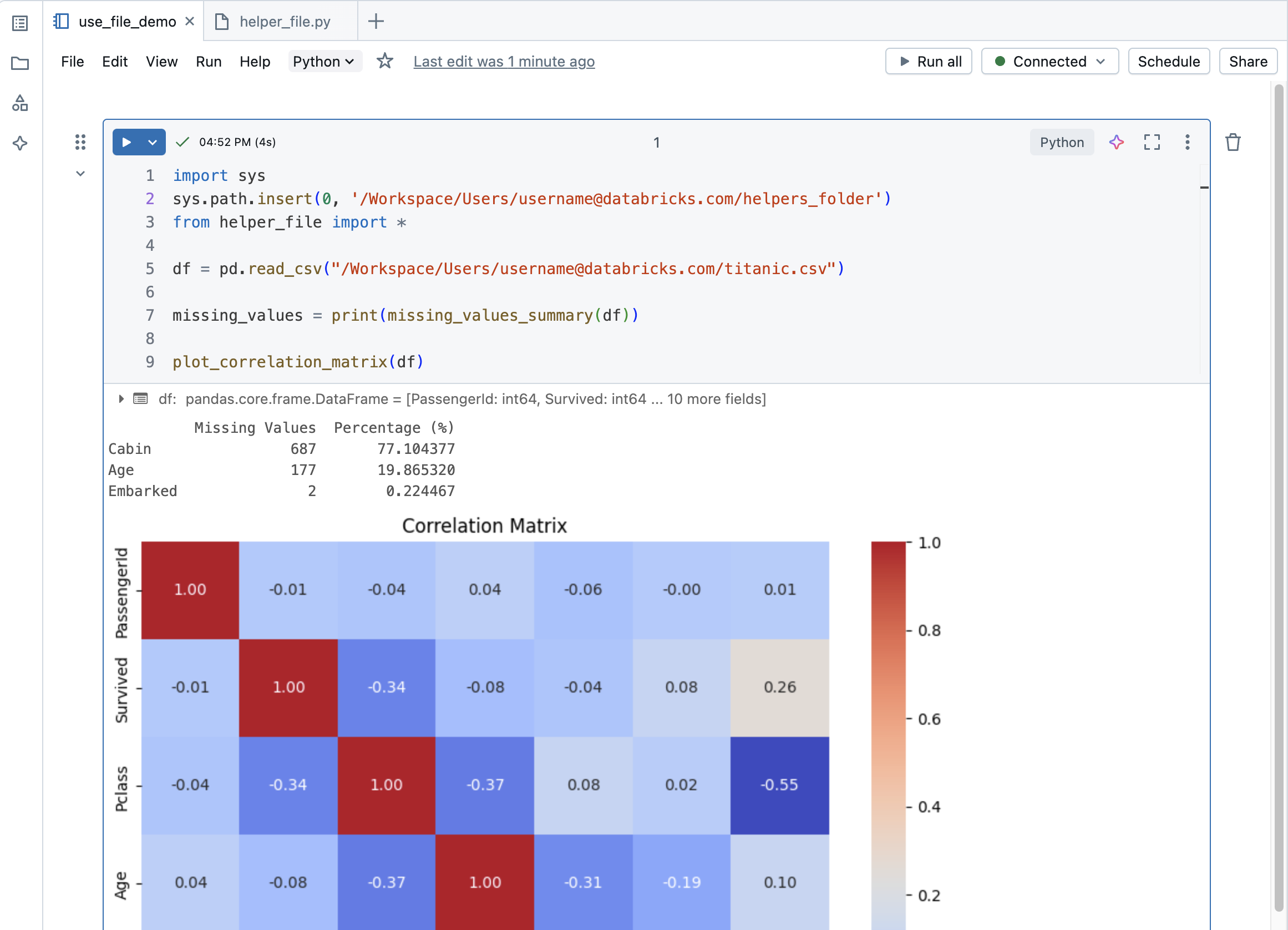
Run a file
You can run a file from the editor. This is useful for testing. To run a file, place your cursor in the code area and select Shift + Enter to run the cell, or highlight code in the cell and press Shift + Ctrl + Enter to run only the selected code.
Delete a file
See Work with folders and folder objects and Manage workspace objects for information about how to access the workspace menu and delete files or other items in the workspace.
Rename a file
To change the title of an open file, click the title and edit inline or click File > Rename.
Control access to a file
If your Databricks account has the Premium plan or above, you can use Workspace access control to control who has access to a file.