Identifying an expensive read in Spark's DAG
Getting to the DAG
Assuming you're looking at an expensive job, first we need the ID of the stage that's doing the read. Here we can see the Stage ID is 194:

Now we need to get to the SQL DAG. Scroll up to the top of the job's page and click on the Associated SQL Query:
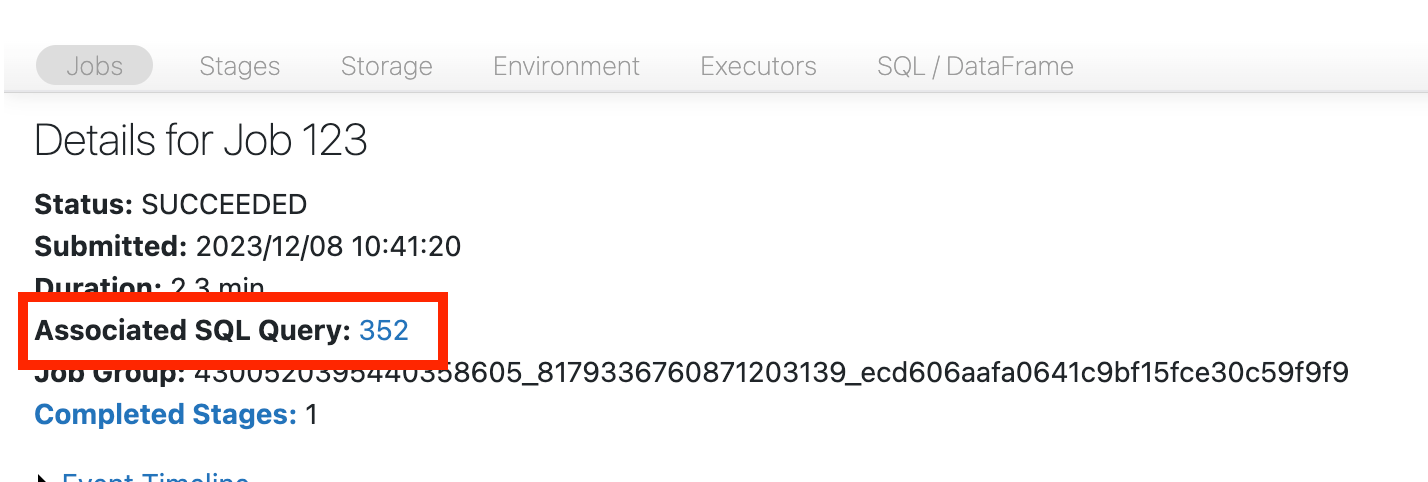
You should now see the DAG. If not, scroll around a bit and you should see it:
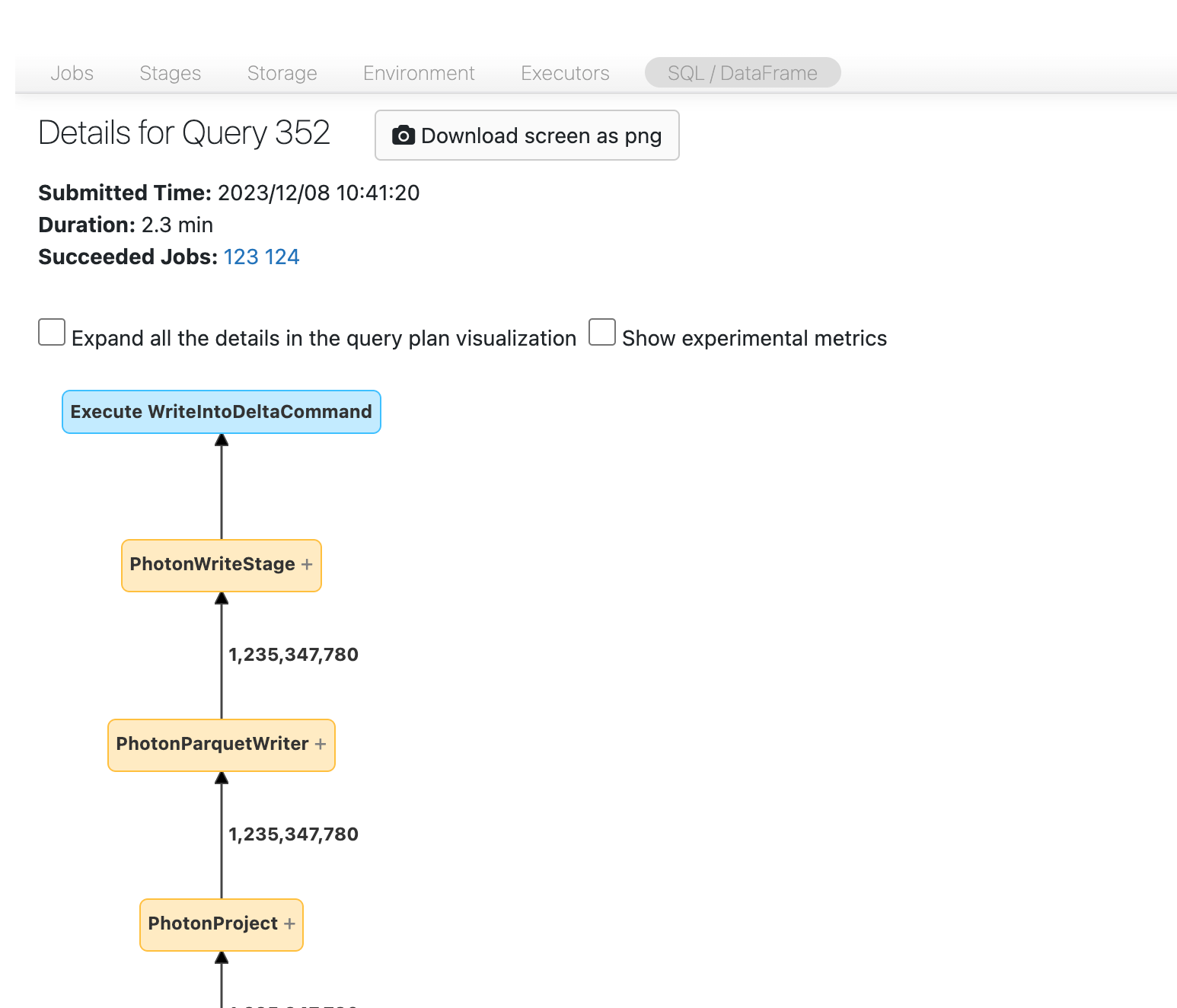
In some cases, you can follow the DAG and see where the data is coming from. In other cases, look for the Stage ID you noted:
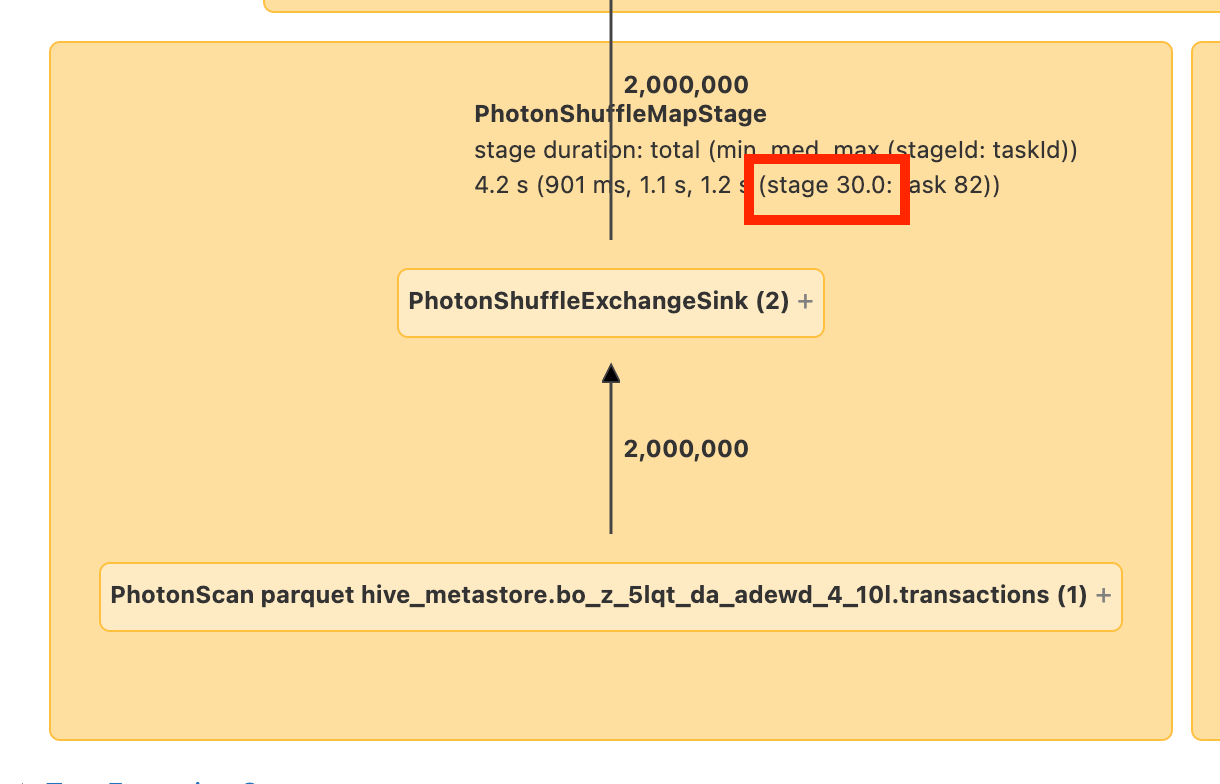
Then you need to look for the “Scan” node. In this case it's pretty simple to tell that we're reading a table named transactions:

In some cases you may need to click on or roll over the node to get the location of the data you're reading.