Query caching
Caching is an essential technique for improving the performance of data warehouse systems by avoiding the need to recompute or fetch the same data multiple times. In Databricks SQL, caching can significantly speed up query execution and minimize warehouse usage, resulting in lower costs and more efficient resource utilization. Each caching layer improves query performance, minimizes cluster usage, and optimizes resource utilization for a seamless data warehouse experience.
Caching provides numerous advantages in data warehouses, including:
- Speed: By storing query results or frequently accessed data in memory or other fast storage mediums, caching can dramatically reduce query execution times. This storage is particularly beneficial for repetitive queries, as the system can quickly retrieve the cached results instead of recomputing them.
- Reduced cluster usage: Caching minimizes the need for additional compute resources by reusing previously computed results. This reduces the overall warehouse uptime and the demand for additional compute clusters, leading to cost savings and better resource allocation.
Types of query caches in Databricks SQL
Databricks SQL performs several types of query caching.
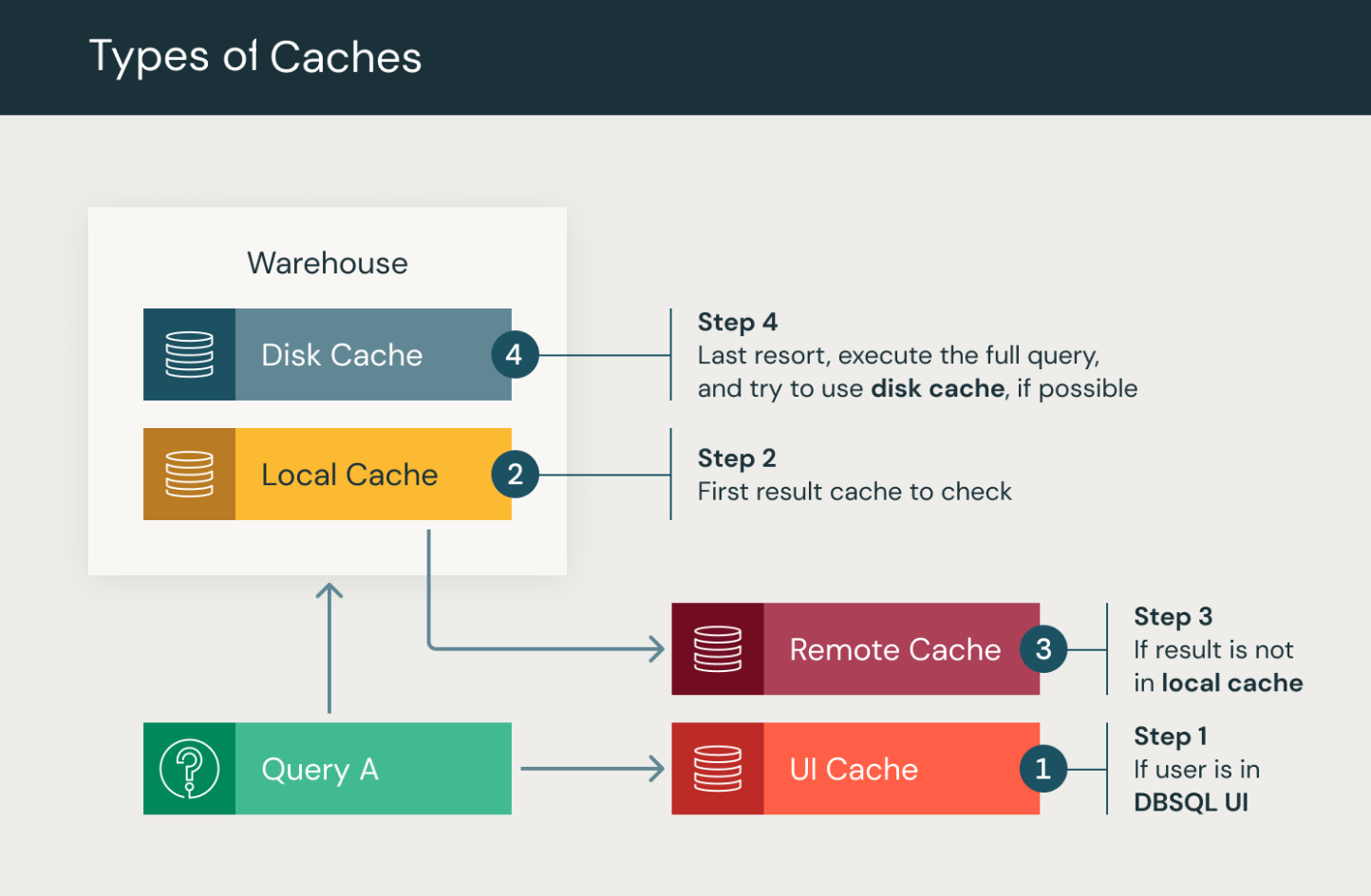
-
Databricks SQL UI cache: Per-user caching of query results and SQL editor visualizations in the Databricks SQL UI. When a user first opens a SQL query or a legacy SQL dashboard, the Databricks SQL UI cache displays the most recent query result, including the results from scheduled executions.
noteThe Databricks SQL UI cache does not apply to AI/BI dashboards (formerly Lakeview dashboards). AI/BI dashboards have their own caching behavior. See Dataset optimization and caching.
The Databricks SQL UI cache has at most a 7-day life cycle. The cache is located within your Databricks filesystem in your account. You can delete query results by re-running the query that you no longer want to be stored. Once re-run, the old query results are removed from cache. Additionally, the cache is invalidated once the underlying tables have been updated.
-
Result cache: Per cluster caching of query results for all queries through SQL warehouses. Result caching includes both local and remote result caches, which work together to improve query performance by storing query results in memory or remote storage mediums.
- Local cache: The local cache is an in-memory cache that stores query results for the cluster's lifetime or until the cache is full, whichever comes first. This cache is useful for speeding up repetitive queries, eliminating the need to recompute the same results. However, once the cluster is stopped or restarted, the cache is cleaned and all query results are removed.
- Remote result cache: The remote result cache is a serverless-only cache system that retains query results by persisting them as workspace system data. As a result, this cache is not invalidated by the stopping or restarting of a SQL warehouse. Remote result cache addresses a common pain point in caching query results in-memory, which only remains available as long as the compute resources are running. The remote cache is a persistent shared cache across all warehouses in a Databricks workspace.
Accessing the remote result cache requires a running warehouse. When processing a query, a cluster first looks in its local cache and then looks in the remote result cache if necessary. Only if the query result isn't cached in either cache is the query executed. Both the local and the remote caches have a life cycle of 24 hours, which starts at cache entry. The remote result cache persists through the stopping or restarting of a SQL warehouse. Both caches are invalidated when the underlying tables are updated.
Remote result cache is available for queries using ODBC / JDBC clients and SQL Statement API.
To disable query result caching, you can run
SET use_cached_result = falsein the SQL editor.importantYou should use this option only in testing or benchmarking.
-
Disk cache: Local SSD caching for data read from data storage for queries through SQL warehouses. The disk cache is designed to enhance query performance by storing data on disk, allowing for accelerated data reads. Data is automatically cached when files are fetched, utilizing a fast intermediate format. By storing copies of the files on the local storage attached to compute nodes, the disk cache ensures the data is located closer to the workers, resulting in improved query performance. See Optimize performance with caching on Databricks.
In addition to its primary function, the disk cache automatically detects changes to the underlying data files. When it detects changes, the cache is invalidated. The disk cache shares the same lifecycle characteristics as the local result cache. This means that when the cluster is stopped or restarted, the cache is cleaned and needs to be repopulated.
The query results caching and disk cache affect queries in the Databricks SQL UI and BI and other external clients.