Asynchronous progress tracking
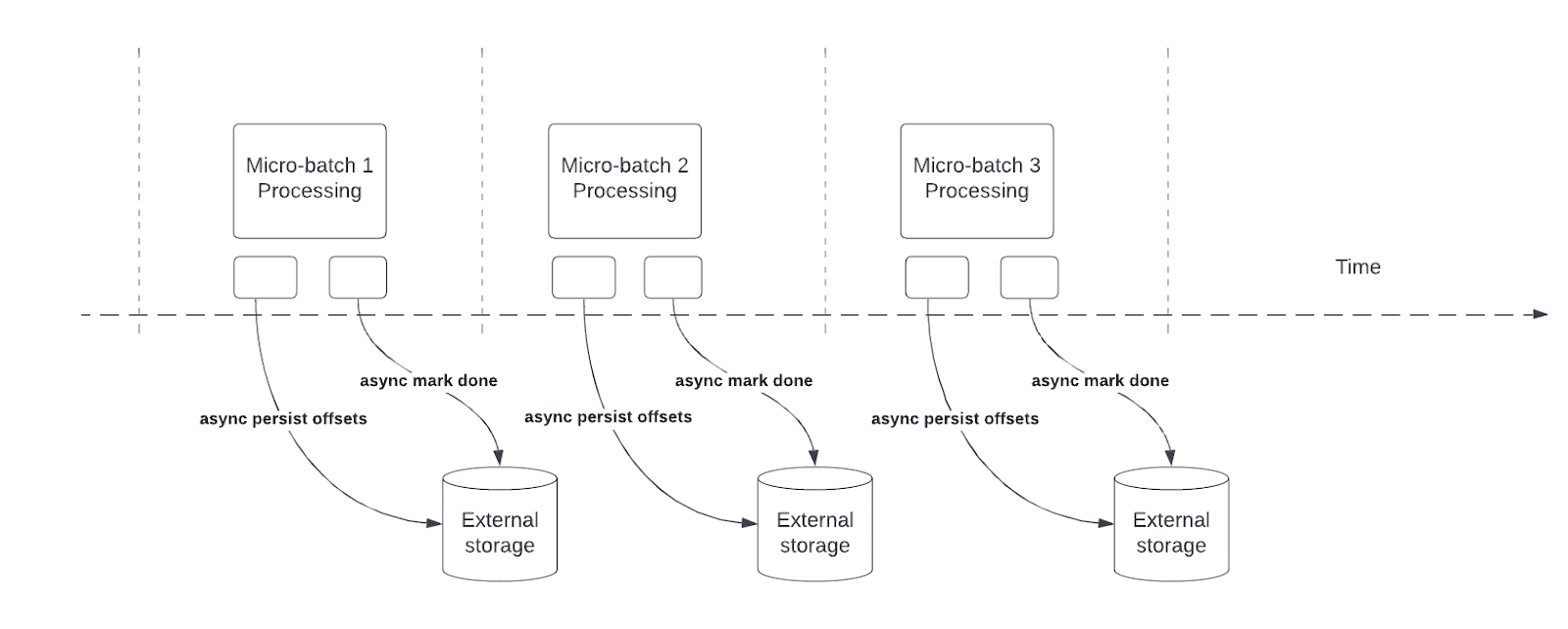
Asynchronous progress tracking reduces latency for Structured Streaming pipelines by enabling queries to asynchronously update checkpoint progress and process data in each micro-batch.
During query processing, Structured Streaming persists and manages offsets to measure query progress in the offsetLog and commitLog in each micro-batch. Without asynchronous progress tracking, offset management operations directly affect processing latency because data processing can't continue until they complete.
Asynchronous progress tracking is not compatible with Trigger.once or Trigger.availableNow triggers. If enabled, Structured Streaming queries with Trigger.once or Trigger.availableNow fail.
Configuration options
Option | Default | Description |
|---|---|---|
|
| Whether to enable asynchronous progress tracking. |
|
| The interval in milliseconds between writes for offsets and completion commits. |
Enable asynchronous progress tracking
To enable asynchronous progress tracking, set asyncProgressTrackingEnabled to true:
- Python
- Scala
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Improve throughput with checkpoint frequency
The default checkpoint frequency of 1000 milliseconds has good throughput for most queries. When offset management operations occur faster than asynchronous progress tracking can process them, a backlog of offset management operations builds. To prevent the backlog from growing further, asynchronous progress tracking can block or slow data processing, potentially eroding the expected latency benefits.
In this scenario, Databricks recommends that you increase the checkpoint interval:
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Failure recovery time increases with the checkpoint interval time. In case of failure, a pipeline must reprocess all data since the previous successful checkpoint. Before you make this change in production, consider the trade-off between lower latency during regular processing compared to recovery time in case of failure.
Turn off asynchronous progress tracking
When asynchronous progress tracking is enabled, the stream does not guarantee checkpoint progress for every batch. You must checkpoint progress before you can turn off this feature.
To turn off, follow these steps:
-
Process at least two micro-batches with
asyncProgressTrackingEnabledset totrueandasyncProgressTrackingCheckpointIntervalMsset to0:- Python
- Scala
Pythonquery = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "0")
.start()
)Scalaval query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "0")
.start() -
Stop the query:
- Python
- Scala
Pythonquery.stop()Scalaquery.stop() -
Turn off asynchronous progress tracking and restart the query:
- Python
- Scala
Pythonquery = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "false")
.start()
)Scalaval query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "false")
.start()
If you turn off asynchronous progress tracking without following the steps above, you might encounter the following error:
java.lang.IllegalStateException: batch x doesn't exist
In the driver logs, you might see the following error:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitations
- For Kafka sinks, asynchronous progress tracking only supports stateless pipelines.
- Asynchronous progress tracking does not guarantee exactly-once end-to-end processing because offset ranges for a batch can change on failure. Some sinks, such as Kafka, never provide exactly-once guarantees.