What are Unity Catalog volumes?
Volumes are Unity Catalog objects that enable governance over non-tabular datasets. Volumes represent a logical volume of storage in a cloud object storage location. Volumes provide capabilities for accessing, storing, governing, and organizing files.
While tables govern tabular data, volumes govern non-tabular data of any format, including structured, semi-structured, or unstructured.
Databricks recommends using volumes to govern access to all non-tabular data. Volumes are available in two types:
- Managed volumes: For simple Databricks-managed storage.
- External volumes: For adding governance to existing cloud object storage locations.
To store your own files for personal or exploratory work without first creating a catalog, schema, and volume, you can use My Files, a per-user volume. My Files is in Beta. See Store files in My Files.
Video walkthrough
This video demonstrates how to work with Unity Catalog volumes (3 minutes).
Use cases for volumes
Use cases for volumes include:
- Register landing areas for raw data produced by external systems to support their processing in the early stages of ETL pipelines and other data engineering activities.
- Register staging locations for ingestion. For example, using Auto Loader,
COPY INTO, or CTAS (CREATE TABLE AS) statements. - Provide file storage locations for data scientists, data analysts, and machine learning engineers to use as part of their exploratory data analysis and other data science tasks.
- Give Databricks users access to arbitrary files produced and deposited in cloud storage by other systems. For example, large collections of unstructured data (such as image, audio, video, and PDF files) captured by surveillance systems or IoT devices, or library files (JARs and Python wheel files) exported from local dependency management systems or CI/CD pipelines.
- Store operational data, such as logging or checkpointing files.
For a demo of working with volumes, see Simplify File, Image, and Data Retrieval with Unity Catalog Volumes.
You can't register files in volumes as tables in Unity Catalog. Volumes are intended for path-based data access only. Use tables when you want to work with tabular data in Unity Catalog.
Managed versus external volumes
Managed and external volumes provide nearly identical experiences when using Databricks tools, UIs, and APIs. The main differences relate to storage location, lifecycle, and control:
Feature | Managed volumes | External volumes |
|---|---|---|
Storage location | Created inside the UC-managed storage for the schema | Registered against an existing cloud object storage path |
Data lifecycle | UC manages layout and deletion (7-day retention on delete) | Data remains in cloud storage when you drop the volume |
Access control | All access goes through UC | UC governs access, but external tools can use direct URIs |
Migration needed? | No | No—use existing storage paths as-is |
Typical use case | Simplest option for Databricks-only workloads | Mixed Databricks and external system access |
Why use managed volumes?
Managed volumes have the following benefits:
- Default choice for Databricks workloads.
- No need to manage cloud credentials or storage paths manually.
- Simplest option for creating governed storage locations quickly.
Why use external volumes?
External volumes allow you to add Unity Catalog data governance to existing cloud object storage directories. Some use cases for external volumes include the following:
- Adding governance where data already resides, without requiring a data copy.
- Governing files produced by other systems that must be ingested or accessed by Databricks.
- Governing data produced by Databricks that must be accessed directly from cloud object storage by other systems.
Databricks recommends using external volumes to store non-tabular data files that are read or written by external systems in addition to Databricks. Unity Catalog doesn't govern reads and writes performed directly against cloud object storage from external systems, so you must apply additional governance outside Databricks using one of the following approaches:
- Vend short-lived credentials from Unity Catalog: Configure external engines to request short-lived credentials from Unity Catalog. The vended credentials inherit the Unity Catalog privileges of the requesting principal, which keeps Unity Catalog as the source of truth for authorization. See Unity Catalog credential vending for external system access.
- Configure cloud-native access controls: Use your cloud provider's IAM policies, bucket policies, or access control lists on the underlying storage location to restrict direct access. Align these controls with the Unity Catalog privileges you have granted on the volume so that external system access matches Unity Catalog access. For background on how Unity Catalog connects to cloud storage, see Connect to cloud object storage using Unity Catalog.
Path for accessing files in a volume
Volumes sit at the third level of the Unity Catalog three-level namespace (catalog.schema.volume):
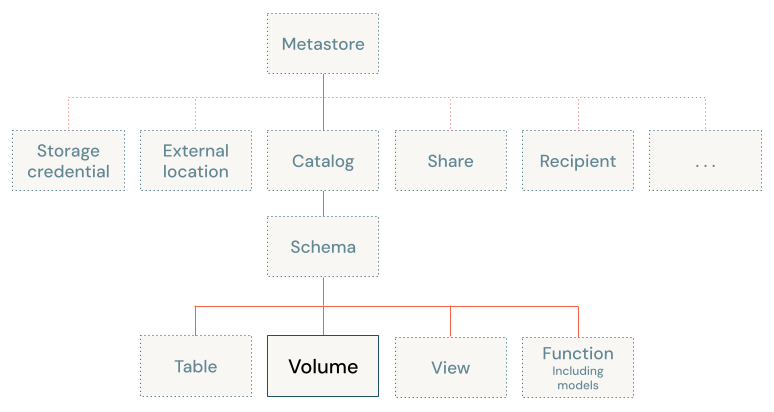
The path to access volumes is the same whether you use Apache Spark, SQL, Python, or other languages and libraries. This differs from legacy access patterns for files in object storage bound to a Databricks workspace.
The path to access files in volumes uses the following format:
/Volumes/<catalog>/<schema>/<volume>/<path>/<file-name>
Databricks also supports an optional dbfs:/ scheme when working with Apache Spark, so the following path also works:
dbfs:/Volumes/<catalog>/<schema>/<volume>/<path>/<file-name>
The /<catalog>/<schema>/<volume> portion of the path maps to the three Unity Catalog object names for the file. These directories are read-only and managed automatically by Unity Catalog. You can't create or delete them with filesystem commands.
You can also access data in external volumes using cloud storage URIs.
Reserved paths for volumes
Volumes introduces the following reserved paths used for accessing volumes:
dbfs:/Volumes/Volumes
Paths are also reserved for potential typos for these paths from Apache Spark APIs and dbutils, including /volumes, /Volume, /volume, whether or not they are preceded by dbfs:/. The path /dbfs/Volumes is also reserved, but can't be used to access volumes.
Volumes are only supported on Databricks Runtime 13.3 LTS and above. In Databricks Runtime 12.2 LTS and below, operations against /Volumes paths might succeed, but they can only write data to ephemeral storage disks attached to compute clusters rather than persisting data to Unity Catalog volumes as expected.
If you have pre-existing data stored in a reserved path on the DBFS root, file a support ticket to gain temporary access to this data to move it to another location.
Compute requirements
When you work with volumes, you must use a SQL warehouse or a cluster running Databricks Runtime 13.3 LTS or above, unless you're using Databricks UIs such as Catalog Explorer.
For information about storing DataFrame checkpoints in volumes, see DataFrame checkpoints in volumes.
Limitations
You must use Unity Catalog-enabled compute to interact with Unity Catalog volumes.
The following table outlines Unity Catalog volume limitations based on the version of Databricks Runtime:
Databricks Runtime version | Limitations |
|---|---|
All supported Databricks Runtime versions |
|
14.3 LTS and above |
|
14.2 and below |
|
Additional resources
The following articles provide more information about working with volumes: