Connect to Google Cloud Storage
This article describes a legacy pattern for accessing Google Cloud Storage (GCS) from an AWS-hosted Databricks workspace which bypasses Unity Catalog governance. Use it only if Unity Catalog governance is not required for the data in this bucket.
To read or write from a GCS bucket, you must create an attached service account and you must associate the bucket with the service account. You connect to the bucket directly with a key that you generate for the service account.
Access a GCS bucket directly with a Google Cloud service account key
To read and write directly to a bucket, you configure a key defined in your Spark configuration.
Step 1: Set up Google Cloud service account using Google Cloud Console
You must create a service account for the Databricks cluster. Databricks recommends giving this service account the least privileges needed to perform its tasks.
-
Click IAM and Admin in the left navigation pane.
-
Click Service Accounts.
-
Click + CREATE SERVICE ACCOUNT.
-
Enter the service account name and description.
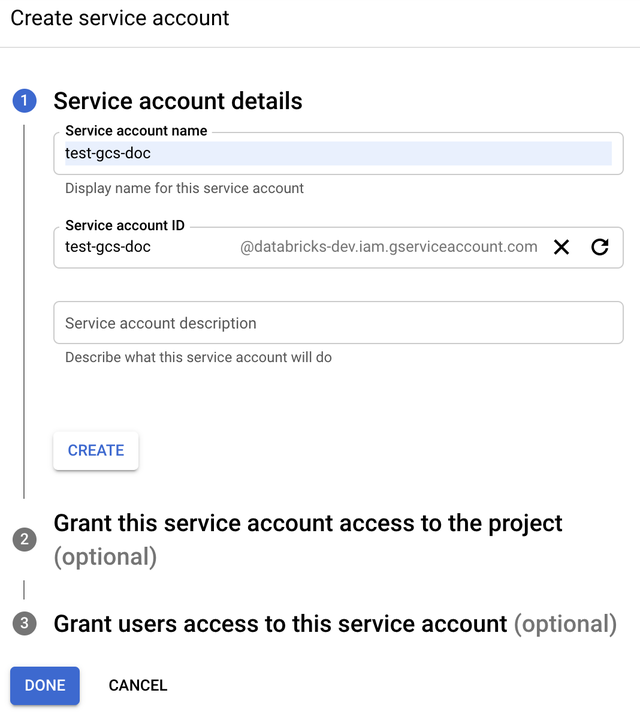
-
Click CREATE.
-
Click CONTINUE.
-
Click DONE.
Step 2: Create a key to access GCS bucket directly
The JSON key you generate for the service account is a private key that should only be shared with authorized users as it controls access to datasets and resources in your Google Cloud account.
- In the Google Cloud console, in the service accounts list, click the newly created account.
- In the Keys section, click ADD KEY > Create new key.
- Accept the JSON key type.
- Click CREATE. The key file is downloaded to your computer.
Step 3: Configure the GCS bucket
Create a bucket
If you do not already have a bucket, create one:
-
Click Storage in the left navigation pane.
-
Click CREATE BUCKET.
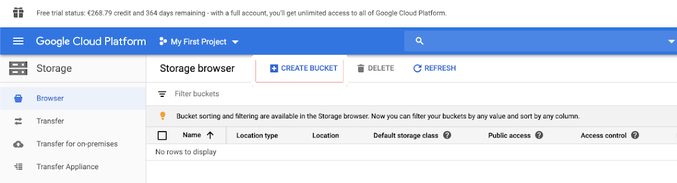
-
Click CREATE.
Configure the bucket
-
Configure the bucket details.
-
Click the Permissions tab.
-
Next to the Permissions label, click ADD.
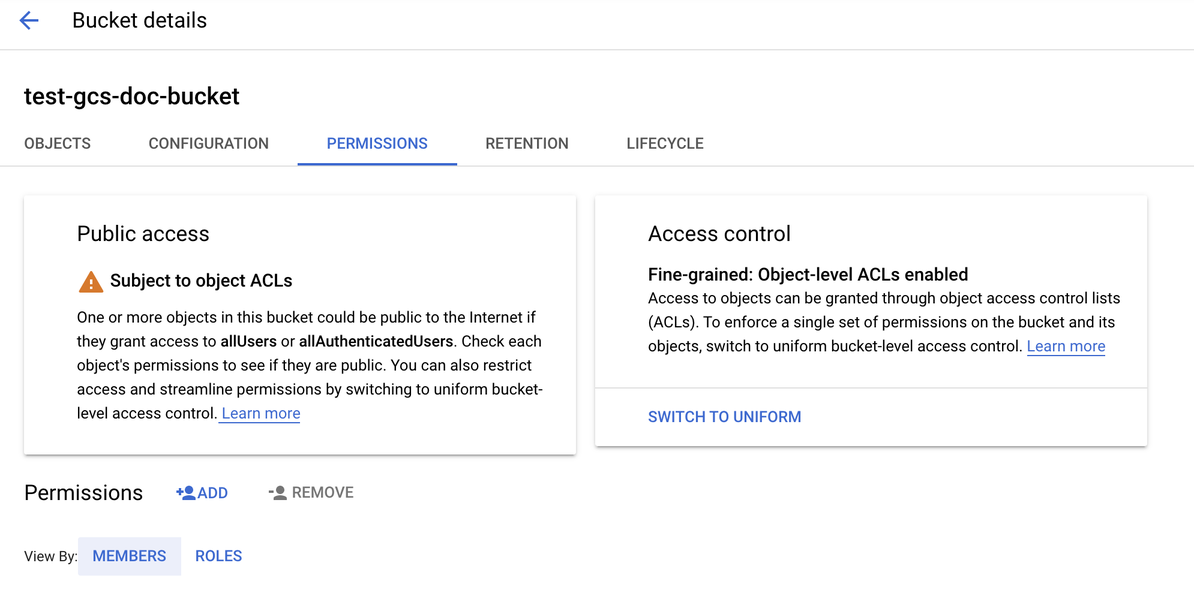
-
Provide the Storage Admin permission to the service account on the bucket from the Cloud Storage roles.
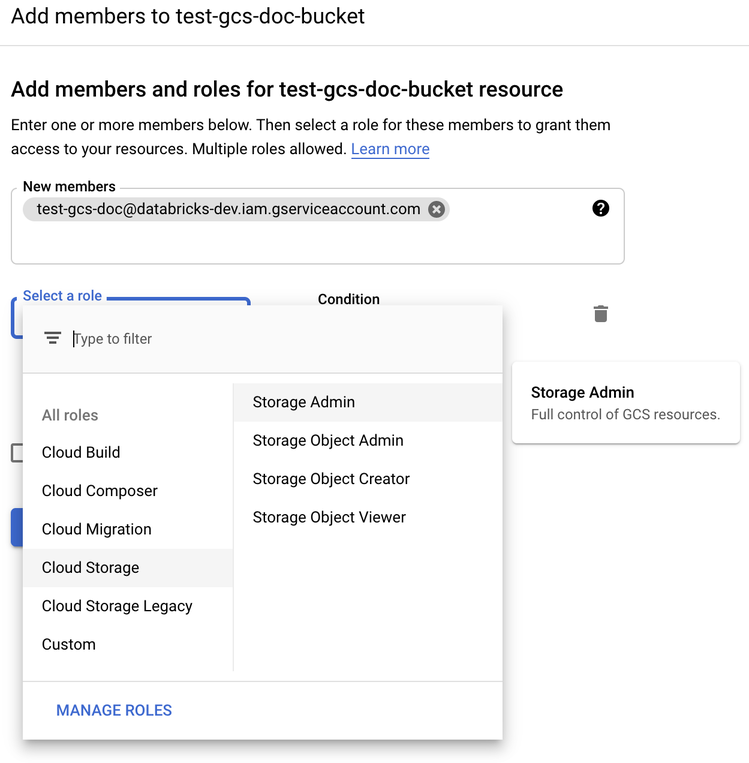
-
Click SAVE.
Step 4: Put the service account key in Databricks secrets
Databricks recommends using secret scopes for storing all credentials. You can put the private key and private key ID from your key JSON file into Databricks secret scopes. You can grant users, service principals, and groups in your workspace access to read the secret scopes. This protects the service account key while allowing users to access GCS. To create a secret scope, see Manage secrets.
Step 5: Configure a Databricks cluster
In the Spark Config tab, configure either a global configuration or a per-bucket configuration. The following examples set the keys using values stored as Databricks secrets.
Use cluster access control and notebook access control together to protect access to the service account and data in the GCS bucket. See Compute permissions and Collaborate using Databricks notebooks.
Global configuration
Use this configuration if the provided credentials should be used to access all buckets.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Replace <client-email>, <project-id> with the values of those exact field names from your key JSON file.
Per-bucket configuration
Use this configuration if the you must configure credentials for specific buckets. The syntax for per-bucket configuration appends the bucket name to the end of each configuration, as in the following example.
Per-bucket configurations can be used in addition to global configurations. When specified, per-bucket configurations supercede global configurations.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Replace <client-email>, <project-id> with the values of those exact field names from your key JSON file.
Step 6: Read from GCS
To read from the GCS bucket, use a Spark read command in any supported format, for example:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
To write to the GCS bucket, use a Spark write command in any supported format, for example:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Replace <bucket-name> with the name of the bucket you created in Step 3: Configure the GCS bucket.