Bundle configuration in Python
Python support for Declarative Automation Bundles extends Declarative Automation Bundles with additional capabilities that apply during bundle deployment so that you can:
-
Define resources in Python code. These definitions can coexist with resources defined in YAML.
-
Dynamically create resources during bundle deployment using metadata. See Create resources using metadata.
-
Modify resources defined in YAML or Python during bundle deployment. See Modify resources defined in YAML or Python.
tipYou can also modify bundle resources at runtime using features such as the if/else condition_task or for_each_task for jobs.
Reference documentation for the Python support for Declarative Automation Bundles databricks-bundles package is available at https://databricks.github.io/cli/python/.
Requirements
To use Python support for Declarative Automation Bundles, you must first:
-
Install the Databricks CLI, version 0.275.0 or above. See Install or update the Databricks CLI.
-
Authenticate to your Databricks workspace if you have not done so already:
Bashdatabricks configure -
Install uv. See Installing uv. Python for Declarative Automation Bundles uses uv to create a virtual environment and install the required dependencies. Alternatively, you can configure your Python environment using other tools such as venv.
Create a project from the template
To create a new Python support for Declarative Automation Bundles project, initialize a bundle using the pydabs template:
databricks bundle init pydabs
When prompted, give your project a name, such as my_pydabs_project, and accept the inclusion of a notebook and Python package.
Now create a new virtual environment in your new project folder:
cd my_pydabs_project
uv sync
By default, the template includes an example of a job defined as Python in the resources/my_pydabs_project_job.py file:
from databricks.bundles.jobs import Job
my_pydabs_project_job = Job.from_dict(
{
"name": "my_pydabs_project_job",
"tasks": [
{
"task_key": "notebook_task",
"notebook_task": {
"notebook_path": "src/notebook.ipynb",
},
},
],
},
)
The Job.from_dict function accepts a Python dictionary using the same format as YAML. Resources can be also constructed using dataclass syntax:
from databricks.bundles.jobs import Job, Task, NotebookTask
my_pydabs_project_job = Job(
name="my_pydabs_project_job",
tasks=[
Task(
task_key="notebook_task",
notebook_task=NotebookTask(
notebook_path="src/notebook.ipynb",
),
),
],
)
Python files are loaded through an entry point specified in the python section in databricks.yml:
python:
# Activate the virtual environment before loading resources defined in
# Python. If disabled, it defaults to using the Python interpreter
# available in the current shell.
venv_path: .venv
# Functions called to load resources defined in Python.
# See resources/__init__.py
resources:
- 'resources:load_resources'
By default, resources/__init__.py contains a function that loads all Python files in the resources package.
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
def load_resources(bundle: Bundle) -> Resources:
"""
'load_resources' function is referenced in databricks.yml and is responsible for loading
bundle resources defined in Python code. This function is called by Databricks CLI during
bundle deployment. After deployment, this function is not used.
"""
# the default implementation loads all Python files in 'resources' directory
return load_resources_from_current_package_module()
Deploy and run jobs or pipelines
To deploy the bundle to the development target, use the bundle deploy command from the bundle project root:
databricks bundle deploy --target dev
This command deploys everything defined for the bundle project. For example, a project created using the default template deploys a job called [dev yourname] my_pydabs_project_job to your workspace. You can find that job by navigating to Jobs & Pipelines in your Databricks workspace.
After the bundle is deployed, you can use the bundle summary command to review everything that is deployed:
databricks bundle summary --target dev
Finally, to run a job or pipeline, use the bundle run command:
databricks bundle run my_pydabs_project_job
Update existing bundles
To update existing bundles, model the project template structure as described in Create a project from a template. Existing bundles with YAML can be updated to include resources defined as Python code by adding a python section in databricks.yml:
python:
# Activate the virtual environment before loading resources defined in
# Python. If disabled, it defaults to using the Python interpreter
# available in the current shell.
venv_path: .venv
# Functions called to load resources defined in Python.
# See resources/__init__.py
resources:
- 'resources:load_resources'
The specified virtual environment must contain the installed databricks-bundles PyPi package.
pip install databricks-bundles==0.275.0
The resources folder must contain __init__.py file:
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
def load_resources(bundle: Bundle) -> Resources:
"""
'load_resources' function is referenced in databricks.yml and
is responsible for loading bundle resources defined in Python code.
This function is called by Databricks CLI during bundle deployment.
After deployment, this function is not used.
"""
# default implementation loads all Python files in 'resources' folder
return load_resources_from_current_package_module()
Convert existing jobs into Python
To convert existing jobs into Python, you can use the View as code feature. See View jobs as code.
-
Open the page for the existing job in the Databricks workspace.
-
Click the
 kebab to the left of the Run now button, then click View as code:
kebab to the left of the Run now button, then click View as code: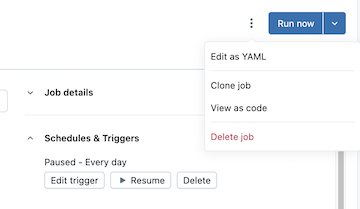
-
Select Python, then Declarative Automation Bundles
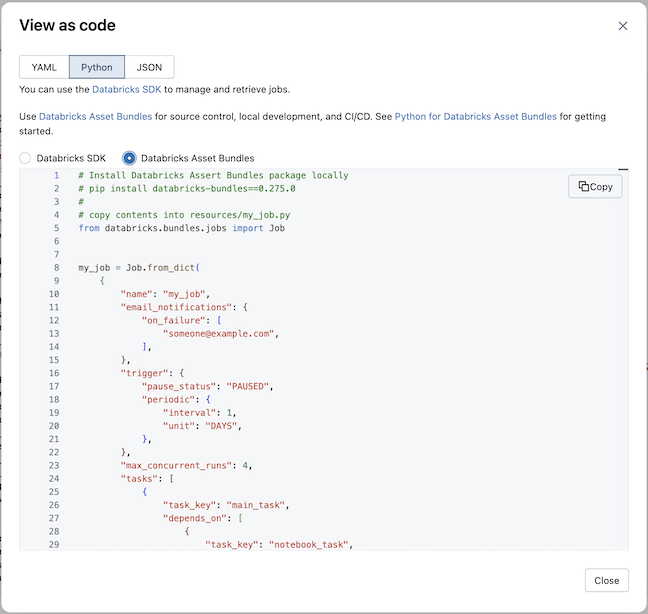
-
Click Copy and save the generated Python as a Python file in the resources folder of the bundle project.
tipYou can also view and copy YAML for existing jobs and pipelines that you can paste directly into your bundle configuration YAML files.
Create resources using metadata
The default implementation of the load_resources function loads Python files in the resources package. You can use Python to create resources programmatically. For example, you can load configuration files and create jobs in a loop:
from databricks.bundles.core import (
Bundle,
Resources,
load_resources_from_current_package_module,
)
from databricks.bundles.jobs import Job
def create_job(country: str):
my_notebook = {
"task_key": "my_notebook",
"notebook_task": {
"notebook_path": "files/my_notebook.py",
},
}
return Job.from_dict(
{
"name": f"my_job_{country}",
"tasks": [my_notebook],
}
)
def load_resources(bundle: Bundle) -> Resources:
resources = load_resources_from_current_package_module()
for country in ["US", "NL"]:
resources.add_resource(f"my_job_{country}", create_job(country))
return resources
Access bundle variables
Bundle substitutions and custom variables enable dynamic retrieval of values so that settings can be determined at the time a bundle is deployed and run on a target. For information about bundle variables, see Custom variables.
In Python, define variables, then use the bundle parameter to access them. See @variables decorator, Variable, Bundle, and Resources.
from databricks.bundles.core import Bundle, Resources, Variable, variables
@variables
class Variables:
# Define a variable
warehouse_id: Variable[str]
def load_resources(bundle: Bundle) -> Resources:
# Resolve the variable
warehouse_id = bundle.resolve_variable(Variables.warehouse_id)
...
Variables can also be accessed in Python using substitutions.
sample_job = Job.from_dict(
{
"name": "sample_job",
"tasks": [
{
"task_key": "my_sql_query_task",
"sql_task": {
"warehouse_id": "${var.warehouse_id}",
"query": {
"query_id": "11111111-1111-1111-1111-111111111111",
},
...
Use target overrides to set variable values for different deployment targets.
Modify resources defined in YAML or Python
To modify resources, you can reference mutator functions in databricks.yml, similar to functions loading resources. This feature can be used independently of loading resources defined in Python and mutates resources defined in both YAML and Python.
First, create mutators.py in the bundle root with the following contents:
from dataclasses import replace
from databricks.bundles.core import Bundle, job_mutator
from databricks.bundles.jobs import Job, JobEmailNotifications
@job_mutator
def add_email_notifications(bundle: Bundle, job: Job) -> Job:
if job.email_notifications:
return job
email_notifications = JobEmailNotifications.from_dict(
{
"on_failure": ["${workspace.current_user.userName}"],
}
)
return replace(job, email_notifications=email_notifications)
Now use the following configuration to execute the add_email_notifications function during bundle deployment. This updates every job defined in the bundle with email notifications if they are absent. Mutator functions have to be specified in databricks.yml, and are executed in the specified order. Job mutators are executed for every job defined in a bundle and can either return an updated copy or unmodified input. Mutators can also be used for other fields, such as configuring default job clusters or SQL warehouses.
python:
mutators:
- 'mutators:add_email_notifications'
If functions throw an exception during the mutator execution, the bundle deployment is aborted.
To configure presets for targets (for example, to unpause schedules for the prod target), use deployment modes and presets. See Custom presets.