Fixing high initialization times in pipelines
Pipelines can contain many datasets with many flows to keep them up to date. Pipelines automatically manage updates and clusters to update efficiently. However, there is some overhead with managing large numbers of flows, and at times, this can lead to larger than expected initialization or even management overhead during processing.
If you are running into delays waiting on triggered pipelines to initialize, such as initialization times over five minutes, consider splitting processing into several pipelines, even when the datasets use the same source data.
Triggered pipelines perform the initialization steps each time they are triggered. Continuous pipelines only perform the initialization steps when they are stopped and restarted. This section is most useful for optimizing triggered pipeline initialization.
When to consider splitting a pipeline
There are several cases where splitting a pipeline can be advantageous for performance reasons.
- The
INITIALIZINGandSETTING_UP_TABLESphases take longer than you want, impacting your overall pipeline time. If this is over 5 minutes, it is often improved by splitting your pipeline. - The driver that manages the cluster can become a bottleneck when running many (more than 30-40) streaming tables within a single pipeline. If your driver is unresponsive, then, your durations for streaming queries will increase, impacting the total time of your update.
- A triggered pipeline having several streaming table flows might not be able to perform all parallelizable stream updates in parallel.
Details on performance issues
This section describes some of the performance issues that can arise from having many tables and flows in a single pipeline.
Bottlenecks in the INITIALIZING and SETTING_UP_TABLES phases
The initial phases of the run can be a performance bottleneck, depending on the complexity of the pipeline.
INITIALIZING phase
During this phase, logical plans are created, including plans for building the dependency graph and determining the order of table updates.
SETTING_UP_TABLES phase
During this phase, the following processes are performed, based on the plans created in the previous phase:
- Schema validation and resolution for all the tables defined in the pipeline.
- Build the dependency graph, and determining the order of table execution.
- Check if each dataset is active in the pipeline or is new since any previous update.
- Create streaming tables in the first update, and, for materialized views, create temporary views or backup tables required during every pipeline update.
Why INITIALIZING and SETTING_UP_TABLES can take longer
Large pipelines with many flows for many datasets can take longer for several reasons:
- For pipelines with many flows and complex dependencies these phases can take a longer time due to the volume of work to be done.
- Complex transformations, including
Auto CDCtransformations, can cause a performance bottleneck, because of the operations required to materialize the tables based on the defined transformations. - There are also scenarios where a significant number of flows can cause slowness, even if those flows are not part of an update. As an example, consider a pipeline that has over 700 flows, of which fewer than 50 are updated for each trigger, based on a config. In this example, each run must go through some of the steps for all 700 tables, get the dataframes, and then select the ones to run.
Bottlenecks in the driver
The driver manages the updates within the run. It must execute some logic for every table, to decide which instances in a cluster should handle each flow. When running several (more than 30-40) streaming tables within a single pipeline, the driver can become a bottleneck for CPU resources as it handles the work across the cluster.
The driver can also run into memory issues. This can happen more often when the number of parallel flows is 30 or more. There is not a specific number of flows or datasets that can cause the driver memory issues but depends on complexity of the tasks that are running in parallel.
Streaming flows can run in parallel, but this requires the driver to use memory and CPU for all streams concurrently. In a triggered pipeline, the driver might process a subset of streams in parallel at a time, to avoid memory and CPU constraints.
In all of these cases, splitting pipelines so that there are an optimal set of flows in each can speed up initialization and processing time.
Trade-offs with splitting pipelines
When all of your flows are within the same pipeline, Lakeflow Spark Declarative Pipelines manages dependencies for you. When there are multiple pipelines, you must manage the dependencies between pipelines.
-
Dependencies You might have a downstream pipeline that depends on multiple upstream pipelines (instead of one). For example, if you have three pipelines,
pipeline_A,pipeline_B, andpipeline_C, andpipeline_Cdepends on bothpipeline_Aandpipeline_B, you wantpipeline_Cto update only after bothpipeline_Aandpipeline_Bhave completed their respective updates. One way to address this is to orchestrate the dependencies by making each pipeline a task in a job with the dependencies properly modeled, sopipeline_Conly updates after bothpipeline_Aandpipeline_Bare complete. -
Concurrency You might have different flows within a pipeline that take very different amounts of time to complete, for example, if
flow_Aupdates in 15 seconds andflow_Btakes several minutes. It can be helpful to look at the query times before splitting your pipelines, and group shorter queries together.
Plan for splitting your pipelines
You can visualize your pipeline split before you start. Here is a graph of a source pipeline that processes 25 tables. A single root datasource is split into 8 segments, each of which has 2 views.
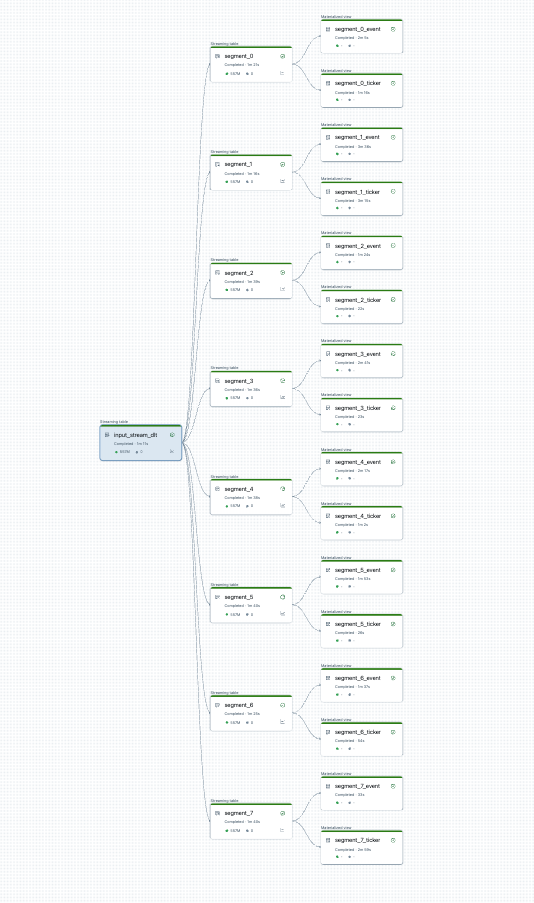
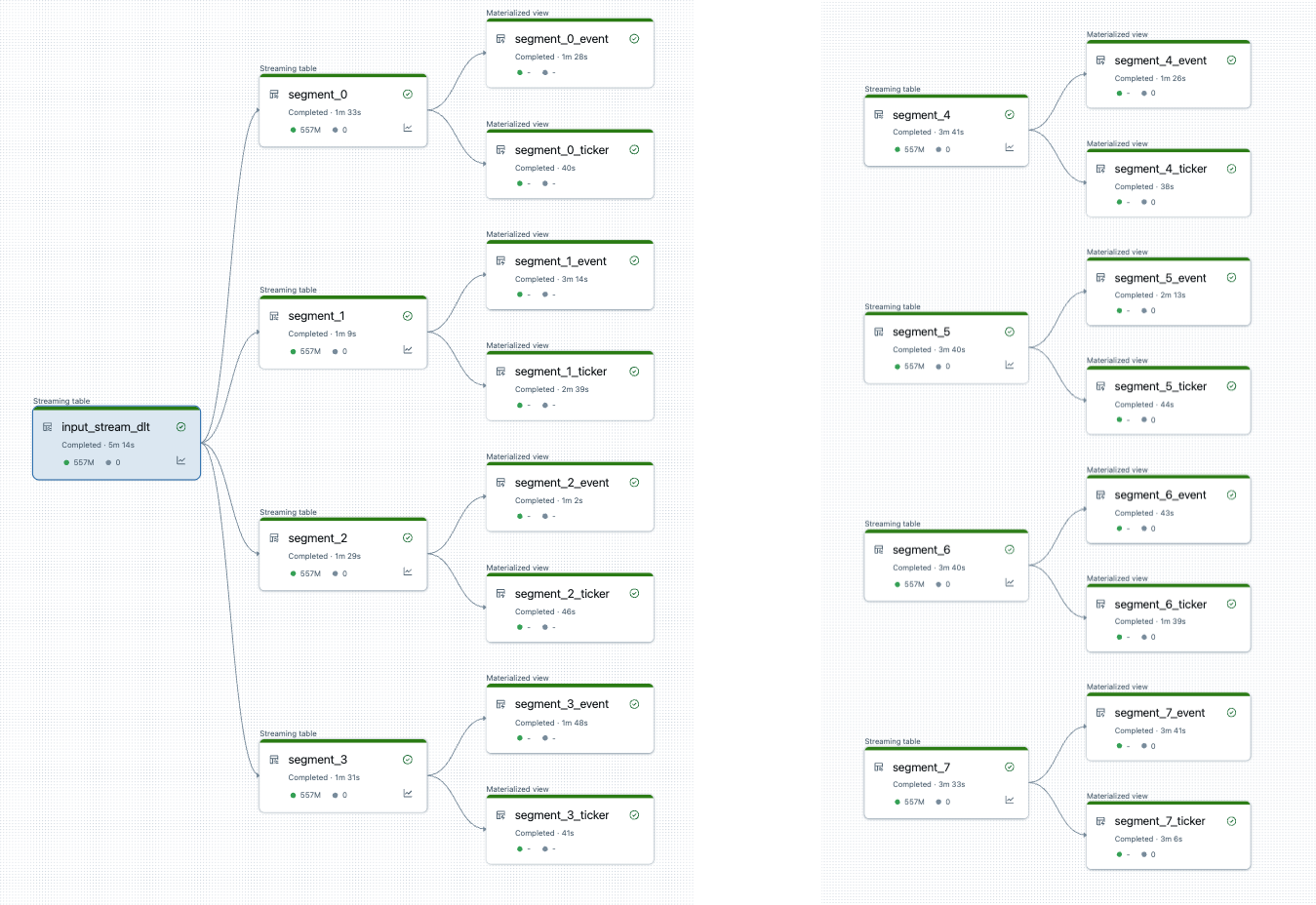
After splitting the pipeline, there are two pipelines. One processes the single root datasource, and 4 segments and associated views. The second pipeline processes the other 4 segments and their associated views. The second pipeline relies on the first to update the root datasource.
Split the pipeline without a full refresh
After you have planned your pipeline split, create any new pipelines needed, and move tables between pipelines to load balance the pipeline. You can move tables without causing a full refresh.
For details, see Move tables between pipelines.
There are some limitations with this approach:
- The pipelines must be in Unity Catalog.
- Source and destination pipelines must be within the same workspace. Cross-workspace moves are not supported.
- The destination pipeline must be created and run once (even if it fails) prior to the move.
- You cannot move a table from a pipeline that uses the default publishing mode to one that uses the legacy publishing mode. For more details, see LIVE schema (legacy).