Recover a pipeline from streaming checkpoint failure
This page describes how to recover a pipeline in Lakeflow Spark Declarative Pipelines when a streaming checkpoint becomes invalid or corrupted.
What is a streaming checkpoint?
In Apache Spark Structured Streaming, a checkpoint is a mechanism used to persist the state of a streaming query. This state includes:
- Progress information: Which offsets from the source have been processed.
- Intermediate state: Data that needs to be maintained across micro-batches for stateful operations (for example, aggregations,
mapGroupsWithState). - Metadata: Information about the streaming query's execution.
Checkpoints are essential for ensuring fault tolerance and data consistency in streaming applications:
- Fault tolerance: If a streaming application fails (for example, due to a node failure, application crash), the checkpoint allows the application to restart from the last successful checkpointed state instead of reprocessing all data from the beginning. This prevents data loss and ensures incremental processing.
- Exactly-once processing: For many streaming sources, checkpoints, in conjunction with idempotent sinks, enable exactly-once processing guarantees that each record is processed exactly once, even in the face of failures, preventing duplicates or omissions.
- State management: For stateful transformations, checkpoints persist the internal state of these operations, allowing the streaming query to correctly continue processing new data based on the accumulated historical state.
Pipeline checkpoints
Pipelines build on Structured Streaming and abstracts away much of the underlying checkpoint management, offering a declarative approach. When you define a streaming table in your pipeline, there is a checkpoint state for each flow writing to the streaming table. These checkpoint locations are internal to the pipeline and are not accessible to the users.
You typically don’t need to manage or understand the underlying checkpoints for streaming tables, except in the following cases:
- Rewind and replay: If you want to reprocess the data from a specific point in time while preserving the current state of the table, you must reset the checkpoint of the streaming table.
- Recovering from a checkpoint failure or corruption: If a query writing to the streaming table has failed due to checkpoint-related errors, it causes a hard failure, and the query cannot progress further. There are three approaches that you can use to recover from this class of failure:
- Full table refresh: This resets the table and wipes out the existing data.
- Full table refresh with backup and backfill: You take a backup of the table before performing a full table refresh and backfill old data, but this is very expensive and should be the last resort.
- Reset checkpoint and continue incrementally: If you cannot afford to lose existing data, you must perform a selective checkpoint reset for the affected streaming flows.
Example: Pipeline failure due to code change
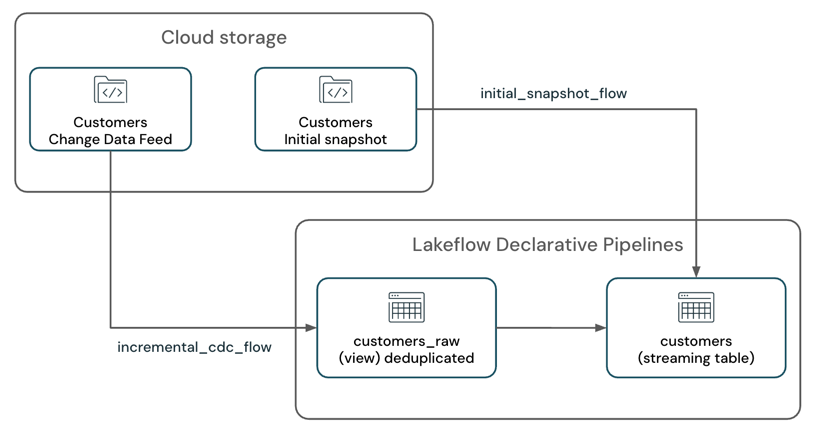
Consider a scenario where you have a pipeline that processes a change data feed along with the initial table snapshot from a cloud storage system, such as Amazon S3, and writes to an SCD-1 streaming table.
The pipeline has two streaming flows:
customers_incremental_flow: Incrementally reads thecustomersource table CDC feed, filters out duplicate records, and upserts them into the target table.customers_snapshot_flow: One-time read the initial snapshot of thecustomerssource table and upserts the records into the target table.
@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load(customers_incremental_path)
.dropDuplicates(["customer_id"])
)
@dp.temporary_view(name="customers_snapshot_view")
def full_orders_snapshot():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.includeExistingFiles", "true")
.option("cloudFiles.inferColumnTypes", "true")
.load(customers_snapshot_path)
.select("*")
)
dp.create_streaming_table("customers")
dp.create_auto_cdc_flow(
flow_name = "customers_incremental_flow",
target = "customers",
source = "customers_incremental_view",
keys = ["customer_id"],
sequence_by = col("sequenceNum"),
apply_as_deletes = expr("operation = 'DELETE'"),
apply_as_truncates = expr("operation = 'TRUNCATE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
dp.create_auto_cdc_flow(
flow_name = "customers_snapshot_flow",
target = "customers",
source = "customers_snapshot_view",
keys = ["customer_id"],
sequence_by = lit(0),
stored_as_scd_type = 1,
once = True
)
After deploying this pipeline, it runs successfully and starts processing the change data feed and initial snapshot.
Later, you realize that the deduplication logic in the customers_incremental_view query is redundant and causing a performance bottleneck. You remove the dropDuplicates() to improve performance:
@dp.temporary_view(name="customers_raw_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load()
# .dropDuplicates()
)
After removing the dropDuplicates() API and redeploying the pipeline, the update fails with the following error:
Streaming stateful operator name does not match with the operator in state metadata.
This is likely to happen when a user adds/removes/changes stateful operators of existing streaming query.
Stateful operators in the metadata: [(OperatorId: 0 -> OperatorName: dedupe)];
Stateful operators in current batch: []. SQLSTATE: 42K03 SQLSTATE: XXKST
This error indicates that the change is not allowed due to a mismatch between the checkpoint state and the current query definition, preventing the pipeline from progressing further.
Checkpoint-related failures can occur for various reasons beyond just removing the dropDuplicates API. Common scenarios include:
- Adding or removing stateful operators (for example, introducing or dropping
dropDuplicates()or aggregations) in an existing streaming query. - Adding, removing, or combining streaming sources in a previously checkpointed query (for example, unioning an existing streaming query with a new one, or adding/removing sources from an existing union operation).
- Modifying the state schema of stateful streaming operations (such as changing the columns used for deduplication or aggregation).
For a comprehensive list of supported and unsupported changes, refer to the Spark Structured Streaming Guide and Types of changes in Structured Streaming queries.
Recovery options
There are three recovery strategies, depending on your data durability requirements and resource constraints:
Methods | Complexity | Cost | Potential data loss | Potential data duplication | Requires initial snapshot | Full table reset |
|---|---|---|---|---|---|---|
Low | Medium | Yes (If no initial snapshot is available or if raw files have been deleted at source.) | No (For apply changes target table.) | Yes | Yes | |
Medium | High | No | No (For idempotent sinks. For example, auto CDC.) | No | No | |
Medium-High (Medium for append-only sources that provide immutable offsets.) | Low | No (Requires careful consideration.) | No (For idempotent writers. For example, auto CDC to the target table only.) | No | No |
Medium-High complexity depends on the streaming source type and the complexity of the query.
Recommendations
- Use a full table refresh if you do not want to deal with the complexity of a checkpoint reset, and you can recompute the whole table. This will also give you an option to make code changes.
- Use full table refresh with backup and backfill if you do not want to deal with the complexity of checkpoint reset, and you are okay with the additional cost of taking a backup and backfilling the historical data.
- Use the reset table checkpoint if you must preserve the existing data in the table and continue processing new data incrementally. However, this approach requires careful handling of the checkpoint reset to check that the existing data in the table is not lost and that the pipeline can continue processing new data.
Reset checkpoint and continue incrementally
To reset the checkpoint and continue processing incrementally, follow these steps:
-
Stop the pipeline: Make sure the pipeline has no active updates running.
-
Determine the starting position for the new checkpoint: Identify the last successful offset or timestamp from which you want to continue processing. This is typically the latest offset successfully processed before the failure occurred.
In the example above, because you are reading the JSON files using autoloader, you can use the
modifiedAfteroption to specify the starting position for the new checkpoint. This option allows you to set a timestamp for when the autoloader should start processing new files.For Kafka sources, you can use the
startingOffsetsoption to specify the offsets from which the streaming query should start processing new data.For Delta Lake sources, you can use the
startingVersionoption to specify the version from which the streaming query should start processing new data. -
Make code changes: You can modify the streaming query to remove the
dropDuplicates()API or make other changes. Also, and check that you have added themodifiedAfteroption to the autoloader read path.Python@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.option("modifiedAfter", "2025-04-09T06:15:00")
.load(customers_incremental_path)
# .dropDuplicates(["customer_id"])
)noteProviding an incorrect
modifiedAftertimestamp can lead to data loss or duplication. Check that the timestamp is set correctly to avoid processing old data again or missing new data.If your query has a stream-stream join or stream-stream union, you must apply the above strategy for all participating streaming sources. For example:
Pythoncdc_1 = spark.readStream.format("cloudFiles")...
cdc_2 = spark.readStream.format("cloudFiles")...
cdc_source = cdc_1..union(cdc_2) -
Identify the flow name(s) associated with the streaming table for which you want to reset the checkpoint. In the example, it is
customers_incremental_flow. You can find the flow name in the pipeline code or by checking the pipeline UI, or the pipeline event logs. -
Reset the checkpoint: Create a Python notebook and attach it to a Databricks cluster.
You’ll need the following information to be able to reset the checkpoint:
- Databricks workspace URL
- Pipeline ID
- Flow name(s) for which you are resetting the checkpoint
Pythonimport requests
import json
# Define your Databricks instance and pipeline ID
databricks_instance = "<DATABRICKS_URL>"
token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
pipeline_id = "<YOUR_PIPELINE_ID>"
flows_to_reset = ["<YOUR_FLOW_NAME>"]
# Set up the API endpoint
endpoint = f"{databricks_instance}/api/2.0/pipelines/{pipeline_id}/updates"
# Set up the request headers
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
# Define the payload
payload = {
"reset_checkpoint_selection": flows_to_reset
}
# Make the POST request
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Check the response
if response.status_code == 200:
print("Pipeline update started successfully.")
else:
print(f"Error: {response.status_code}, {response.text}") -
Run the Pipeline: The pipeline starts processing new data from the specified starting position with a fresh checkpoint, preserving existing table data while continuing incremental processing.
Best practices
- Avoid using private preview features in production.
- Test your changes before making changes in your production environment.
- Create a test pipeline, ideally in a lower environment. If this is not possible, try to use a different catalog and schema for your test.
- Reproduce the error.
- Apply the changes.
- Validate the results and make a decision on go/no-go.
- Roll out the changes to your production pipelines.