Use dbt transformations in Lakeflow Jobs
You can run your dbt Core projects as a task in a job. By running your dbt Core project as a job task, you can benefit from the following Lakeflow Jobs features:
- Automate your dbt tasks and schedule workflows that include dbt tasks.
- Monitor your dbt transformations and send notifications on the status of the transformations.
- Include your dbt project in a workflow with other tasks. For example, your workflow can ingest data with Auto Loader, transform the data with dbt, and analyze the data with a notebook task.
- Automatic archiving of the artifacts from job runs, including logs, results, manifests, and configuration.
To learn more about dbt Core, see the dbt documentation.
Development and production workflow
Databricks recommends developing your dbt projects against a Databricks SQL warehouse. Using a Databricks SQL warehouse, you can test the SQL generated by dbt and use the SQL warehouse query history to debug the queries generated by dbt.
To run your dbt transformations in production, Databricks recommends using the dbt task in a Databricks job. By default, the dbt task runs the dbt Python process using Databricks compute and the dbt generated SQL against the selected SQL warehouse.
You can run dbt transformations on a pro SQL warehouse, Databricks compute or any other dbt-supported warehouse. This article discusses the first two options with examples.
Developing dbt models against a SQL warehouse and running them in production on Databricks compute can lead to subtle differences in performance and SQL language support. Databricks recommends using the same Databricks Runtime version for the compute and the SQL warehouse.
Requirements
-
To learn how to use dbt Core and the
dbt-databrickspackage to create and run dbt projects in your development environment, see Connect to dbt Core.Databricks recommends the dbt-databricks package, not the dbt-spark package. The dbt-databricks package is a fork of dbt-spark optimized for Databricks.
-
To use dbt projects in a Databricks job, you must set up Databricks Git folders. You cannot run a dbt project from DBFS.
- You must have SQL warehouses enabled.
- You must have the Databricks SQL entitlement.
Create and run your first dbt job
The following example uses the jaffle_shop project, an example project that demonstrates core dbt concepts. To create a job that runs the jaffle shop project, perform the following steps.
-
In your workspace, click
 Jobs & Pipelines in the sidebar.
Jobs & Pipelines in the sidebar. -
Click Create, then Job.
-
Click the dbt tile to configure the first task. If the dbt tile is not available, click Add another task type and search for dbt.
-
Optionally, replace the name of the job, which defaults to
New Job <date-time>, with your job name. -
In Task name, enter a name for the task.
-
In the Source drop-down menu, choose Git provider because this example uses the jaffle shop project located in a Git repository.
-
In Project directory, enter the Git repository URL:
https://github.com/dbt-labs/jaffle_shop.git.
-
In the dbt commands text boxes, specify the dbt commands to run (deps, seed, and run). These should be the default. You must prefix every command with
dbt. Commands are run in the specified order.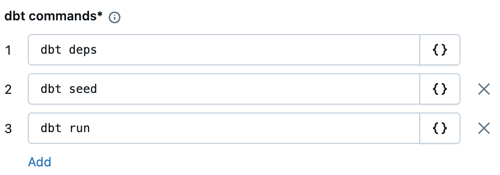
-
In SQL warehouse, select a SQL warehouse to run the SQL generated by dbt. The SQL warehouse drop-down menu shows only serverless and pro SQL warehouses.
-
(Optional) You can specify a catalog and schema for the task output. By default, the
defaultcatalog and schema is used. -
(Optional) If you want to change the compute configuration that runs dbt Core, click dbt CLI compute. Choose an existing compute option or click Add new job cluster to create a new job cluster.
-
In the Environment and Libraries drop-down, leave
dbt-defaultselected. -
Click Save task.
-
To run the job now, click
 .
.
View the results of your dbt job task
When the job is complete, you can test the results by running SQL queries from a notebook or by running queries in your SQL warehouse. For example, see the following sample queries:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Replace <schema> with the schema name configured in the task configuration.
API example
You can also use the Jobs API to create and manage jobs that include dbt tasks. The following example creates a job with a single dbt task:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main",
"sparse_checkout": {
"patterns": ["models", "seeds"]
}
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "c2-standard-16",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": ["dbt deps", "dbt seed", "dbt run"],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
Access dbt task output and artifacts
After a dbt task runs, you can retrieve the task output programmatically using the Databricks CLI or Jobs API. The response includes inline logs and a download link for the archived artifacts.
For multi-task jobs, use the individual dbt task run ID, not the parent job run ID. Using the parent run ID returns the following error:
Retrieving the output of runs with multiple tasks is not supported. Please retrieve the output of each individual task run instead.
The response includes the following fields for dbt tasks:
Field | Description |
|---|---|
| Download URL for the packaged dbt output artifacts, such as |
| Inline dbt logs from the task run. |
| Whether the returned |
| Task run metadata including state, timing, IDs, and task configuration. |
Databricks CLI
Use the databricks jobs get-run-output command to retrieve task output. Replace <task_run_id> with your dbt task's run ID.
databricks jobs get-run-output <task_run_id> --output JSON
Jobs API
Send a GET request to the runs/get-output endpoint. Replace <task_run_id> with your dbt task's run ID.
GET /api/2.0/jobs/runs/get-output?run_id=<task_run_id>
(Advanced) Run dbt with a custom profile
To run your dbt task with a SQL warehouse (recommended) or all-purpose compute, use a custom profiles.yml defining the warehouse or Databricks compute to connect to. To create a job that runs the jaffle shop project with a warehouse or all-purpose compute, perform the following steps.
Only a SQL warehouse or all-purpose compute can be used as the target for a dbt task. You cannot use job compute as a target for dbt.
-
Create a fork of the jaffle_shop repository.
-
Clone the forked repository to your desktop. For example, you could run a command like the following:
Bashgit clone https://github.com/<username>/jaffle_shop.gitReplace
<username>with your GitHub handle. -
Create a new file called
profiles.ymlin thejaffle_shopdirectory with the following content:YAMLjaffle_shop:
target: databricks_job
outputs:
databricks_job:
type: databricks
method: http
schema: '<schema>'
host: '<http-host>'
http_path: '<http-path>'
token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Replace
<schema>with a schema name for the project tables. - To run your dbt task with a SQL warehouse, replace
<http-host>with the Server Hostname value from the Connection Details tab for your SQL warehouse. To run your dbt task with all-purpose compute, replace<http-host>with the Server Hostname value from the Advanced Options, JDBC/ODBC tab for your Databricks compute. - To run your dbt task with a SQL warehouse, replace
<http-path>with the HTTP Path value from the Connection Details tab for your SQL warehouse. To run your dbt task with all-purpose compute, replace<http-path>with the HTTP Path value from the Advanced Options, JDBC/ODBC tab for your Databricks compute.
You do not specify secrets, such as access tokens, in the file because you check this file into source control. Instead, this file uses the dbt templating functionality to insert credentials dynamically at runtime. For more information about accessing environment variables in dbt, see Environment variables in the dbt documentation.
noteThe generated credentials are valid for the duration of the run, up to a maximum of 30 days, and are automatically revoked after completion.
- Replace
-
Check this file into Git and push it to your forked repository. For example, you could run commands like the following:
Bashgit add profiles.yml
git commit -m "adding profiles.yml for my Databricks job"
git push -
Click
Jobs & Pipelines in the sidebar of the Databricks UI. -
Select the dbt job and click the Tasks tab.
-
In Source, click Edit and enter your forked jaffle shop GitHub repository details.
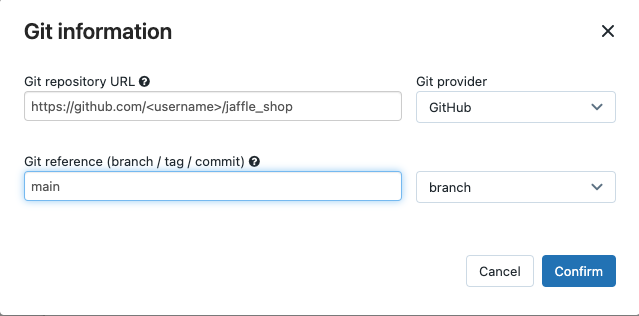
-
In SQL warehouse, select None (Manual).
noteIf you set a Catalog or Schema in the standard task configuration, clear both before switching the SQL warehouse to None (Manual). A catalog or schema can only be set when a SQL warehouse is selected, so leaving either set causes the task to fail validation with the error
Catalog can only be defined if the warehouseId is defined. -
In Profiles Directory, enter the relative path to the directory containing the
profiles.ymlfile. Leave the path value blank to use the default of the repository root.
(Advanced) Use dbt Python models in a workflow
dbt support for Python models is in beta and requires dbt 1.3 or greater.
dbt now supports Python models on specific data warehouses, including Databricks. With dbt Python models, you can use tools from the Python ecosystem to implement transformations that are difficult to implement with SQL. You can create a Databricks job to run a single task with your dbt Python model, or you can include the dbt task as part of a workflow that includes multiple tasks.
You cannot run Python models in a dbt task using a SQL warehouse. For more information about using dbt Python models with Databricks, see Specific data warehouses in the dbt documentation.
Errors and troubleshooting
Profile file does not exist error
Error message:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Possible causes:
The profiles.yml file was not found in the specified $PATH. Make sure the root of your dbt project contains the profiles.yml file.