Evaluate and monitor AI agents
MLflow provides comprehensive agent evaluation and LLM evaluation capabilities to help you measure, improve, and maintain the quality of your AI applications. MLflow supports the entire development lifecycle from testing through production monitoring for LLMs, agents, RAG systems, or other GenAI applications.
Evaluating AI agents and LLMs is more complex than traditional ML model evaluation. These applications involve multiple components, multi-turn conversations, and nuanced quality criteria. Both qualitative and quantitative metrics require specialized evaluation approaches to accurately assess performance.
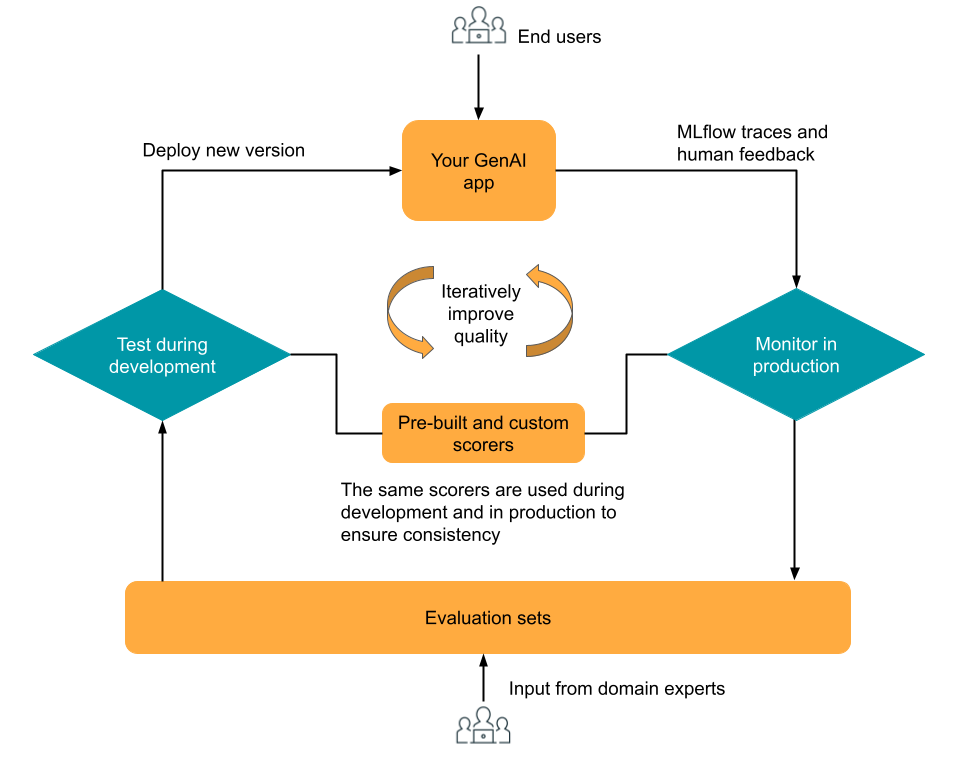
The evaluation and monitoring component of MLflow 3 is designed to help you iteratively optimize the quality of your GenAI app. Evaluation and monitoring build upon MLflow Tracing, which provides real-time trace logging in the development, testing, and production phases. Traces can be evaluated during development using built-in or custom LLM judges and scorers, and production monitoring can reuse the same judges and scorers, ensuring consistent evaluation throughout the application lifecycle. Domain experts can provide feedback using an integrated Review App for collecting human feedback, producing evaluation data for further iteration.
The diagram shows this high-level iterative workflow.
Feature | Description |
|---|---|
Run a quick demo notebook that introduces MLflow Evaluation using a simple GenAI application. | |
Step through a tutorial of the complete evaluation workflow, using a simulated RAG application. Use evaluation datasets and LLM judges to evaluate quality, identify issues, and iteratively improve your app. | |
Define quality metrics for your app using built-in LLM judges, custom LLM judges, and custom scorers. Use the same metrics for both development and production. | |
Test your GenAI application on evaluation datasets, using scorers and LLM judges. Compare app versions, track improvements, and share results. | |
Automatically run scorers and LLM judges on your production GenAI application traces to continuously monitor quality. | |
Use the Review App to collect expert feedback and build evaluation datasets. |
Agent Evaluation is integrated with managed MLflow 3. The Agent Evaluation SDK methods are now available using the mlflow[databricks]>=3.1 SDK. See Migrate to MLflow 3 from Agent Evaluation to update your MLflow 2 Agent Evaluation code to use MLflow 3.