Tracing txtai
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
MLflow Tracing provides automatic tracing capability for txtai. Auto tracing for txtai can be enabled by calling the mlflow.autolog function, MLflow will capture traces for LLM invocation, embeddings, AI Search, and log them to the active MLflow Experiment.
Prerequisites
To use MLflow Tracing with txtai, you need to install MLflow, the txtai library, and the mlflow-txtai extension.
- Development
- Production
For development environments, install the full MLflow package with Databricks extras, txtai, and mlflow-txtai:
pip install --upgrade "mlflow[databricks]>=3.1" txtai mlflow-txtai
The full mlflow[databricks] package includes all features for local development and experimentation on Databricks.
For production deployments, install mlflow-tracing, txtai, and mlflow-txtai:
pip install --upgrade mlflow-tracing txtai mlflow-txtai
The mlflow-tracing package is optimized for production use.
MLflow 3 is highly recommended for the best tracing experience with txtai.
Before running the examples, you'll need to configure your environment:
For users outside Databricks notebooks: Set your Databricks environment variables:
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
For users inside Databricks notebooks: These credentials are automatically set for you.
API Keys: Ensure your LLM provider API keys are set:
export OPENAI_API_KEY="your-openai-api-key"
# Add other provider keys as needed if using txtai with different models
Basic Example
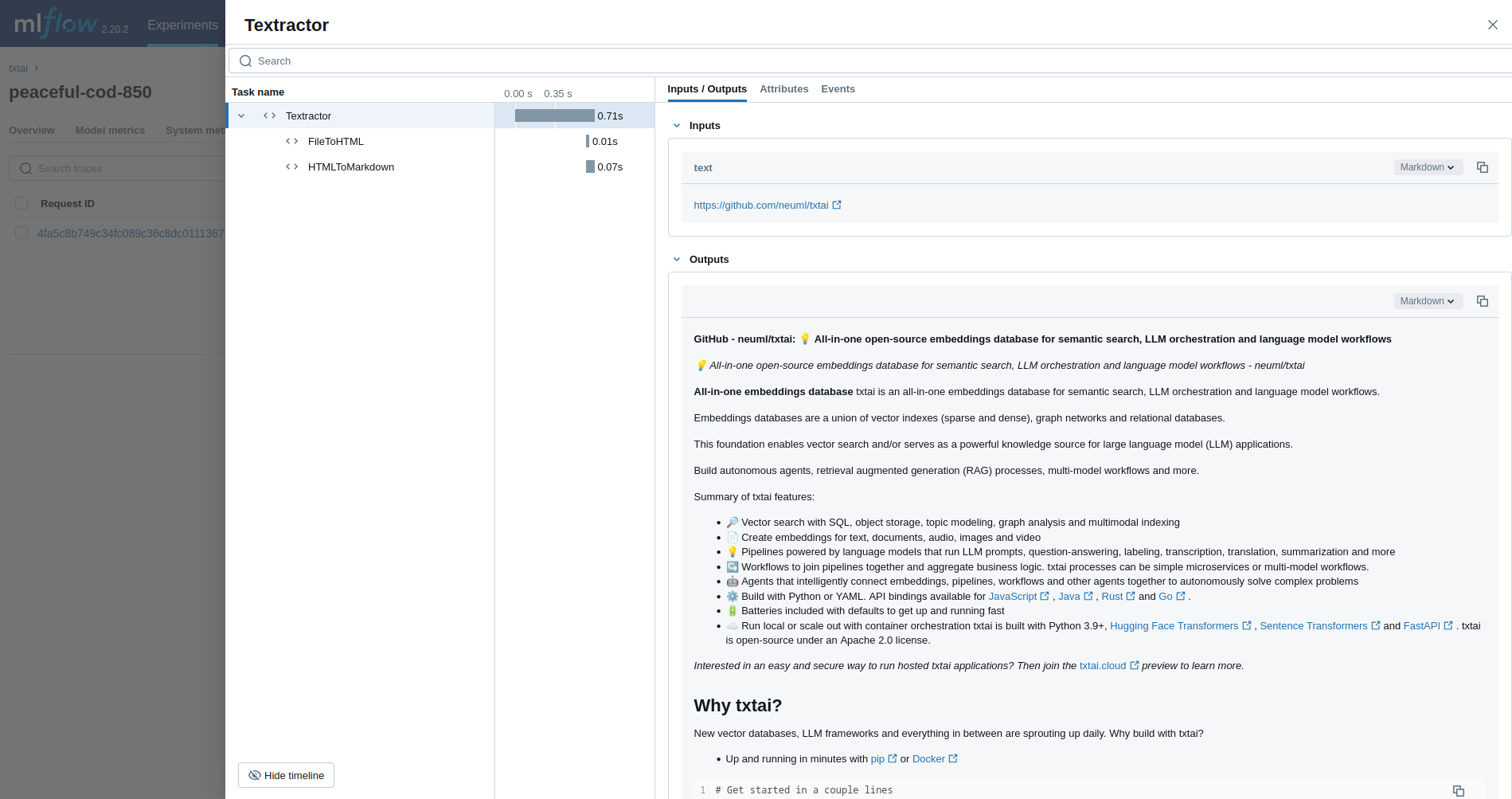
The first example traces a Textractor pipeline.
On serverless compute clusters, autologging for genAI tracing frameworks is not automatically enabled. You must explicitly enable autologging by calling the appropriate mlflow.<library>.autolog() function for the specific integrations you want to trace.
import mlflow
from txtai.pipeline import Textractor
import os
# Ensure any necessary LLM provider API keys are set in your environment if Textractor uses one
# For example, if it internally uses OpenAI:
# os.environ["OPENAI_API_KEY"] = "your-openai-key"
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/txtai-demo")
# Define and run a simple Textractor pipeline.
textractor = Textractor()
textractor("https://github.com/neuml/txtai")
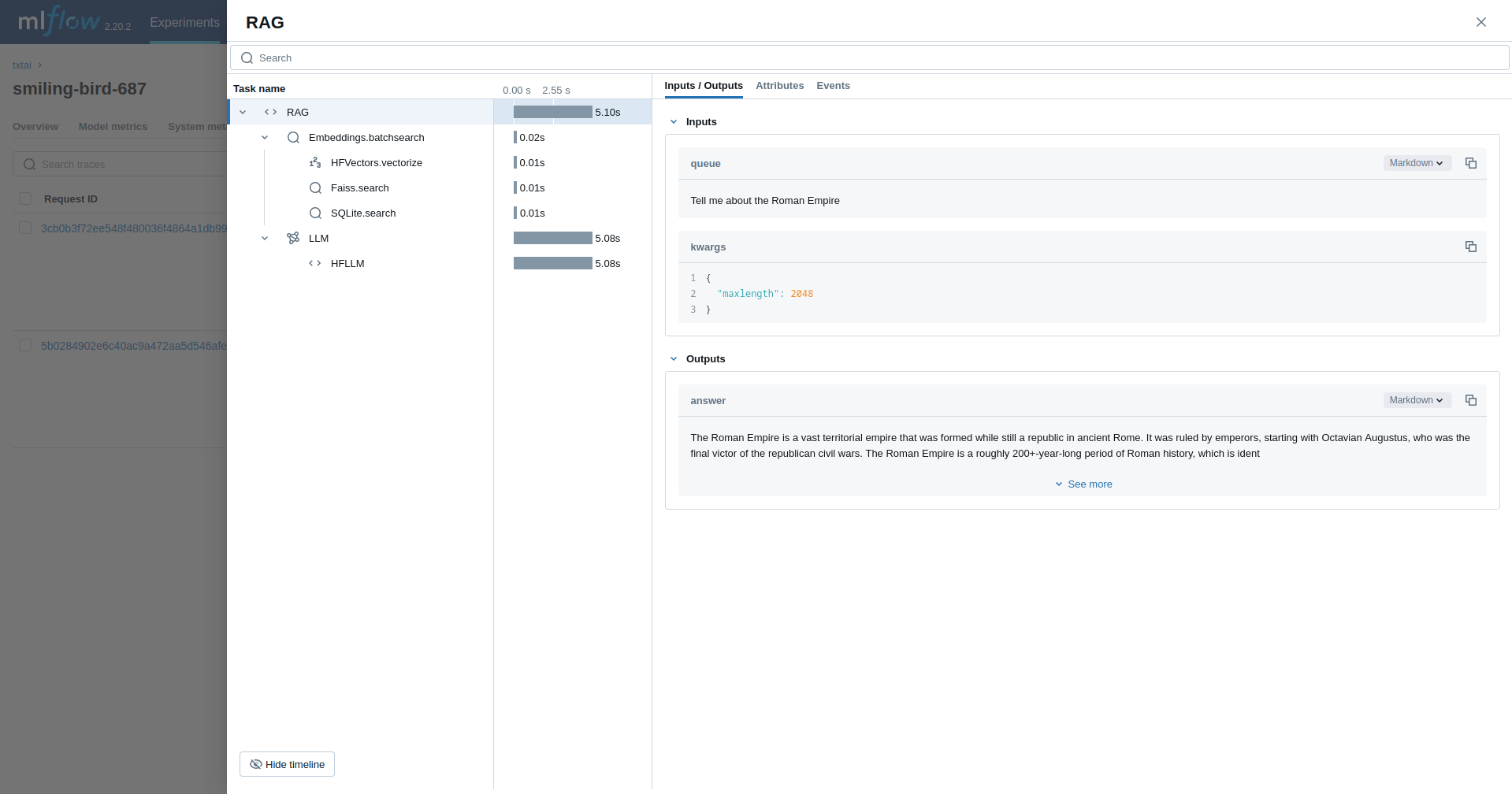
Retrieval Augmented Generation (RAG)
The next example traces a RAG pipeline.
import mlflow
from txtai import Embeddings, RAG
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-rag-demo")
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
# Define prompt template
template = """
Answer the following question using only the context below. Only include information
specifically discussed.
question: {question}
context: {context} """
# Create RAG pipeline
rag = RAG(
wiki,
"hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
system="You are a friendly assistant. You answer questions from users.",
template=template,
context=10,
)
rag("Tell me about the Roman Empire", maxlength=2048)
Agent
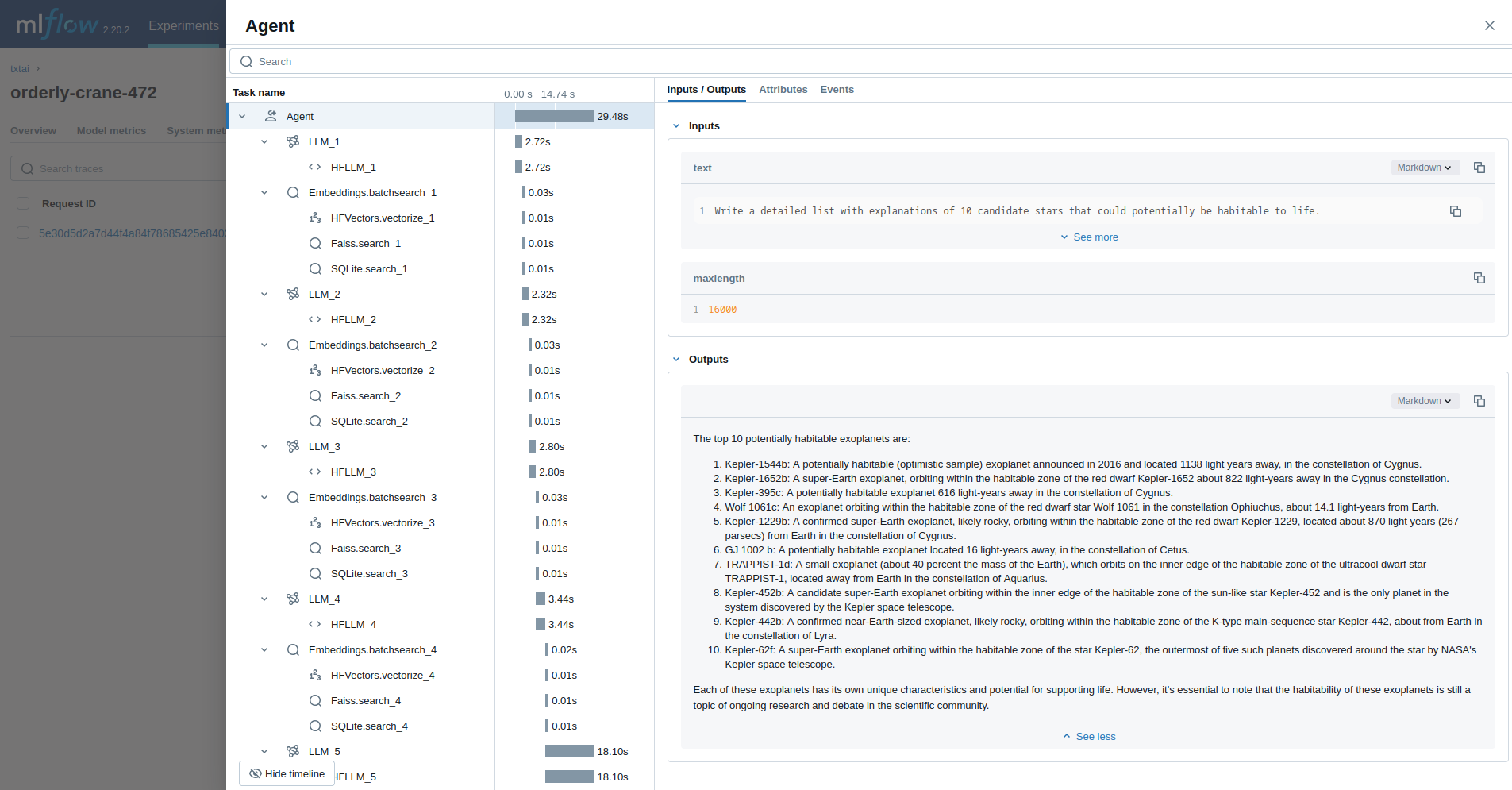
The last example runs a txtai agent designed to research questions on astronomy.
import mlflow
from txtai import Agent, Embeddings
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-agent-demo")
def search(query):
"""
Searches a database of astronomy data.
Make sure to call this tool only with a string input, never use JSON.
Args:
query: concepts to search for using similarity search
Returns:
list of search results with for each match
"""
return embeddings.search(
"SELECT id, text, distance FROM txtai WHERE similar(:query)",
10,
parameters={"query": query},
)
embeddings = Embeddings()
embeddings.load(provider="huggingface-hub", container="neuml/txtai-astronomy")
agent = Agent(
tools=[search],
llm="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
max_iterations=10,
)
researcher = """
{command}
Do the following.
- Search for results related to the topic.
- Analyze the results
- Continue querying until conclusive answers are found
- Write a Markdown report
"""
agent(
researcher.format(
command="""
Write a detailed list with explanations of 10 candidate stars that could potentially be habitable to life.
"""
),
maxlength=16000,
)
Additional resources
For more examples and guidance on using txtai with MLflow, see the MLflow txtai extension documentation.
Additional resources
- Understand tracing concepts - Learn how MLflow captures and organizes trace data for RAG and agent workflows
- Debug and observe your app - Use the Trace UI to analyze your txtai application's behavior
- Evaluate your app's quality - Set up quality assessment for your semantic search and RAG applications