エージェントシステム設計パターン
GenAIエージェントは、GenAIモデルの知能と、データ取得、外部アクション、その他の機能のためのツールを組み合わせたものです。このページでは、エージェントの設計について解説します。
- エージェントシステムを構築する具体的な例を通して、モデルとツールの呼び出しがどのように連携して流れるかを説明します。
- エージェントシステムの設計パターンは、決定論的な連鎖から、動的な意思決定を行うことができる単一エージェントシステム、そして複数の専門エージェントを連携させるマルチエージェントアーキテクチャまで、複雑さと自律性の連続体を形成する。
- 実践的なアドバイスのセクションでは、適切な設計の選択、エージェントの開発、テスト、および本番運用への移行に関するアドバイスを提供します。
エージェントは、情報収集や外部への行動を起こすためのツールに大きく依存している。ツールに関する詳しい背景情報については、 「ツール」を参照してください。
エージェントシステムの例
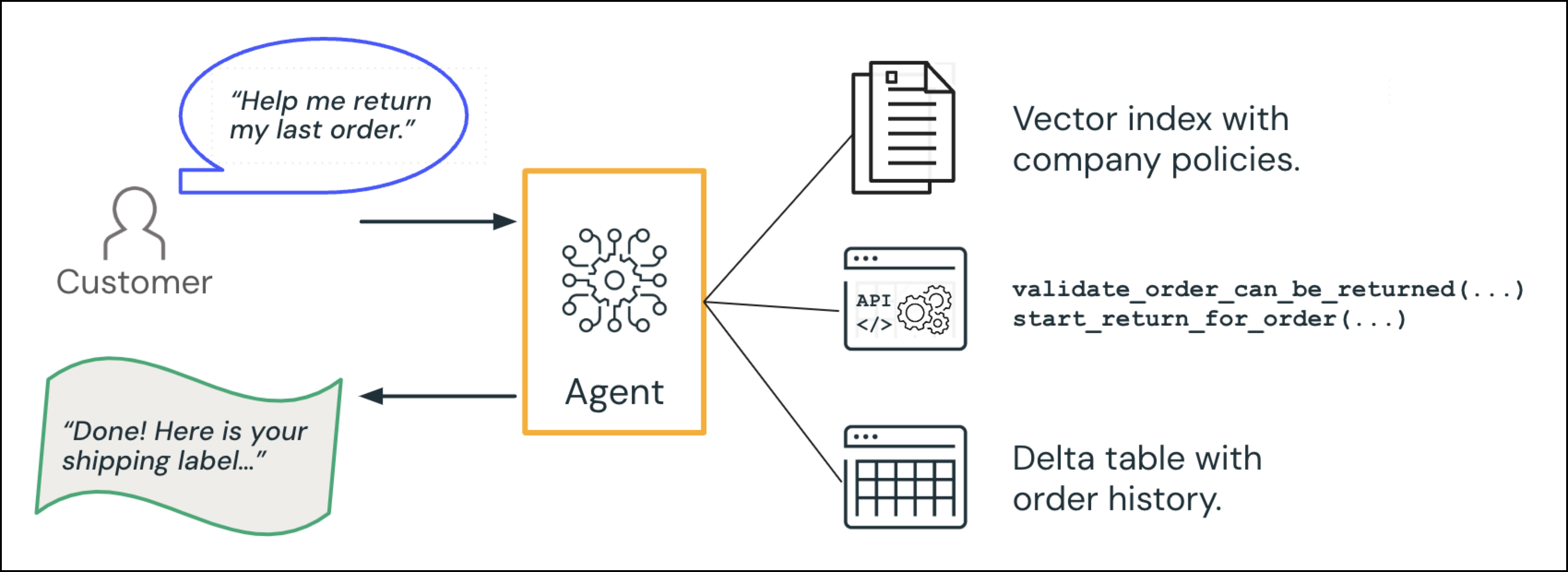
エージェントシステムの具体的な例として、コールセンターのGenAIエージェントが顧客とやり取りする場面を考えてみましょう。
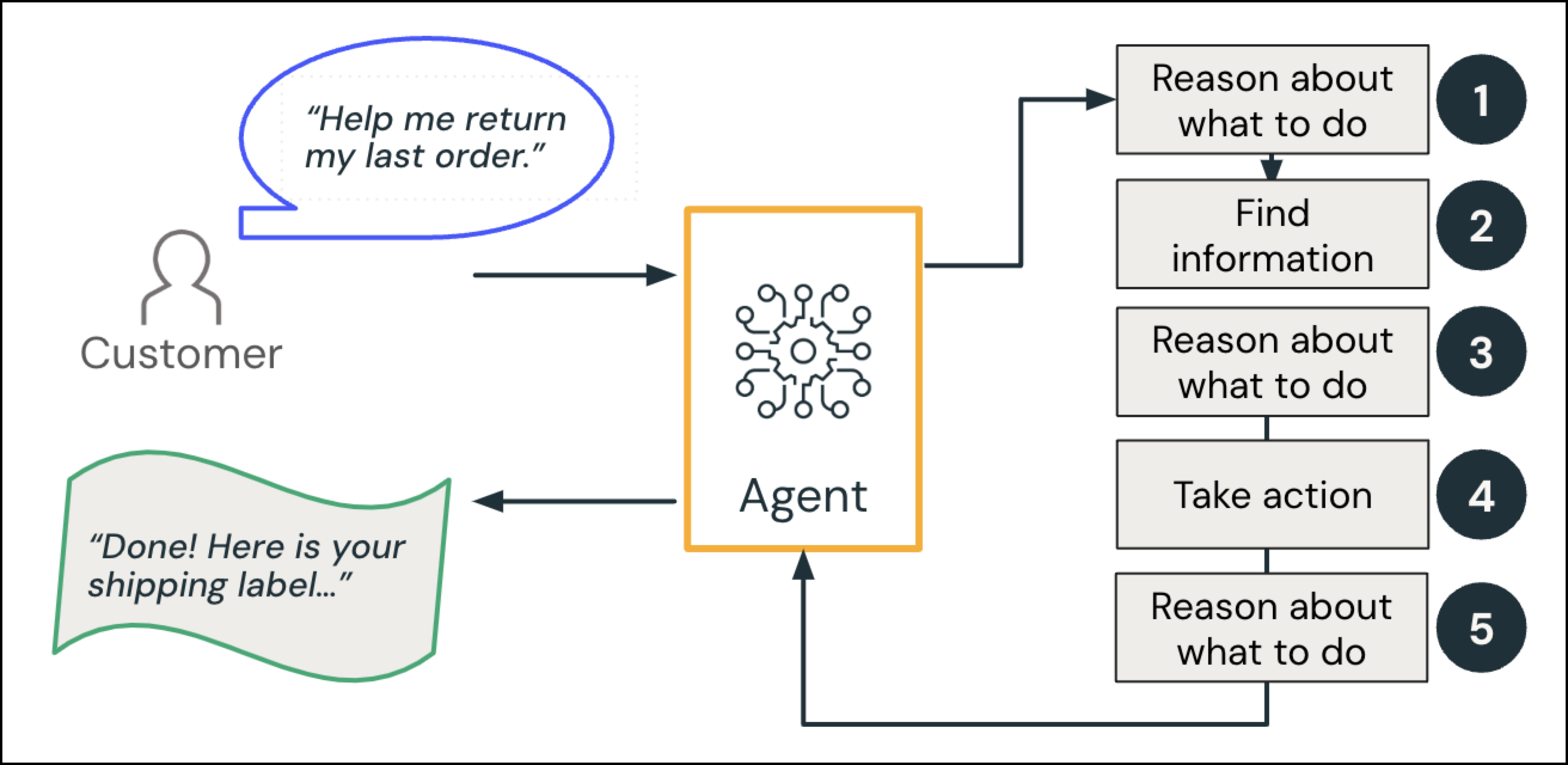
顧客から「前回の注文品を返品するのを手伝ってもらえますか?」という依頼がありました。
-
理由と計画 :クエリの意図に基づいて、エージェントは「ユーザーの最近の注文を検索し、返品ポリシーを確認する」という計画を立てます。
-
情報検索 (データインテリジェンス):エージェントは注文データベースにクエリを実行して関連する注文を取得し、ポリシー文書を参照します。
-
理由 :担当者は、その注文が返品期間内に収まるかどうかを確認します。
- オプションのヒューマン・イン・ザ・ループ: エージェントは追加のルールを確認します。商品が特定のカテゴリに該当する場合、または通常の返品期間外である場合は、人間にエスカレーションします。
-
アクション :担当者が返品手続きを開始し、配送ラベルを生成します。
-
理由 :エージェントが顧客への応答を生成する。
AIエージェントは顧客に「完了しました!」と応答します。こちらが発送ラベルです…
これらのステップは、 人間の コールセンターのコンテキストでは第二の性質です。 エージェントシステムの 文脈では、LLMが「推論」を行い、システムは詳細を補完するために専用のツールやデータソースを呼び出す。
複雑性のレベル:LLMからエージェントシステムまで
GenAIアプリは、単純なLLM呼び出しから複雑なマルチエージェントシステムまで、さまざまなシステムによって駆動できます。AIを活用したアプリケーションを開発する際は、まずはシンプルなものから始めましょう。より高度な柔軟性やモデル駆動型の意思決定のために本当に必要な場合にのみ、より複雑なエージェントの挙動を導入してください。決定論的チェーンは、明確に定義されたタスクに対して、予測可能でルールに基づいた流れを提供する。より主体的なアプローチは、より大きな柔軟性と可能性を提供するが、複雑さが増し、潜在的な遅延が発生するという代償を伴う。
デザインパターン | 使用時期 | 長所 | 短所 |
|---|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
|
カスタム エージェントはこれらの設計パターンにとらわれないため、シンプルに開始し、アプリケーションの要件が増大するにつれて、より高度な自動化と自律性へと進化させられます。
エージェントシステムの理論についてさらに詳しく知りたい場合は、Databricksの創設者によるブログ記事をご覧ください。
LLMとプロンプト
最もシンプルな設計では、膨大なトレーニングデータセットからの知識に基づいてプロンプトに応答する、スタンドアロンのLLMまたはその他のGenAIモデルが使用されます。この設計は単純なクエリや一般的なクエリには適していますが、実際のビジネスデータとはかけ離れていることが多いです。独自の指示や埋め込みデータを含むシステムプロンプトを提供することで、動作をカスタマイズできます。

決定的なチェーン (ハードコードされたステップ)
決定論的チェーンは、ツール呼び出しによって GenAI モデルを拡張しますが、開発者はどのツールまたはモデルが、どの順序で、どの を使用して呼び出されるかを定義します。 LLMは 、どのツールをどの ような順序 で呼び出すかについて決定を下すことはありません。このシステムは、すべてのリクエストに対して事前に定義されたワークフロー、つまり「チェーン」に従うため、非常に予測可能です。
例えば、決定論的な検索拡張生成(RAG)チェーンは常に以下のようになる可能性がある。
- ベクターインデックスから上位k件の結果を取得し、ユーザーのリクエストに関連するコンテキストを見つけます。
- ユーザーのリクエストと取得したコンテキストを組み合わせることで、プロンプトを拡張します。
- 拡張プロンプトをLLMに送信して応答を生成します。

使用時期:
- 明確に定義されたタスクと予測可能なワークフローに適しています。
- 一貫性と監査が最優先事項である場合。
- オーケストレーションの決定のために複数のLLM呼び出しを回避することで、レイテンシを最小限に抑えたい場合。
利点:
- 最高の予測可能性と監査可能性。
- 一般的にレイテンシが低い(オーケストレーションのためのLLM呼び出しが少ない)。
- テストと検証が容易になる。
考慮事項:
- 多様な要求や予期せぬ要求への対応において、柔軟性に欠ける。
- 論理分岐が増えるにつれて、複雑化し、保守が困難になる可能性がある。
- 新たな機能に対応するためには、大幅なリファクタリングが必要になる場合があります。
単一エージェントシステム
単一エージェントシステムは、協調的なロジックの流れを調整するLLM(論理論理管理)を備えている。LLMは、どのツールを使用するか、いつLLM呼び出しをさらに行うか、そしていつ停止するかを適応的に決定します。このアプローチは、状況に応じた動的な意思決定を支援する。
単一エージェントシステムは以下のことが可能です。
- ユーザーからの問い合わせなどのリクエストや、会話履歴などの関連するコンテキストを受け入れる。
- 最適な対応方法を検討し、必要に応じて外部データやアクションのためのツールを呼び出すかどうかを決定する。
- 必要に応じて反復処理を行い、目的が達成されるか、有効なデータを受信する、エラーを解決するなどの特定の条件が満たされるまで、LLMまたはツールを繰り返し呼び出します。
- ツールの出力結果を会話に組み込む。
- 一貫性のある応答を出力として返してください。
例えば、ヘルプデスクアシスタントエージェントは次のように対応できるかもしれません。
- ユーザーが簡単な質問(「返品ポリシーはどうなっていますか?」)をした場合、担当者はLLMの知識に基づいて直接回答する可能性があります。
- ユーザーが注文状況を確認したい場合、エージェントは関数
lookup_order(customer_id, order_id)を呼び出す可能性があります。そのツールが「無効な注文番号」と応答した場合、担当者は再試行するか、ユーザーに正しいIDを入力するように促し、最終的な回答が得られるまで処理を続けます。

使用時期:
- ユーザーからの問い合わせ内容は多岐にわたるものの、いずれも一貫性のあるドメインまたは製品領域内にとどまることが想定されます。
- 顧客データの取得タイミングを決定するなど、特定のクエリや条件によっては、ツールの使用が正当化される場合があります。
- 決定論的なチェーンよりも柔軟性が欲しいが、異なるタスクごとに個別の専用エージェントは必要ない。
利点:
- エージェントは、呼び出すツール(もしあれば)を選択することで、新規または予期せぬ問い合わせに対応できます。
- エージェントは、完全なマルチエージェント構成を必要とせずに、LLM呼び出しやツール呼び出しを繰り返し実行して結果を洗練させることができます。
- この設計パターンは、エンタープライズ用途において最適な選択肢となることが多い。マルチエージェント構成よりもデバッグが容易でありながら、動的なロジックと限定的な自律性も維持できるからだ。
考慮事項:
- ハードコードされたチェーンと比較すると、ツール呼び出しの繰り返しや無効な呼び出しを防ぐ必要があります。無限ループはあらゆるツール呼び出しシナリオで発生する可能性があるため、反復回数の制限またはタイムアウトを設定してください。
- アプリケーションが(財務、DevOps、マーケティングなど)全く異なるサブドメインにまたがる場合、単一のエージェントでは扱いにくくなったり、機能要件が過剰になったりする可能性があります。
- エージェントの集中力と関連性を維持するためには、綿密に設計された指示と制約が依然として必要です。
- 主体性とは連続的なものであり、モデルにシステムの動作を制御する自由度を多く与えるほど、アプリケーションの主体性は高まる。実際には、ほとんどの本番運用システムは、コンプライアンスと予測可能性を確保するために、たとえば危険なアクションに対して人間の承認を必要とするなど、エージェントの自律性を慎重に制限します。
マルチエージェントシステム
マルチエージェントシステムとは、メッセージを交換したり、タスクで協力したりする2つ以上の専門的なエージェントで構成されるシステムである。各エージェントは、それぞれ独自の専門分野やタスクに関する知識、状況認識、そして場合によっては異なるツールセットを持っている。別の「コーディネーター」または「AIスーパーバイザー」が、リクエストを適切なエージェントに振り分けたり、あるエージェントから別のエージェントに引き継ぐタイミングを決定したりする。スーパーバイザーは、別のLLM(論理論理モデル)でも、ルールベースのルーターでも構いません。

例えば、カスタマーアシスタントには、専門のエージェントに業務を委任するスーパーバイザーがいる場合がある。
- ショッピング アシスタント: 顧客の製品検索を支援し、レビューから長所と短所についてのアドバイスを提供します。
- カスタマーサポート担当者:フィードバック、返品、配送に対応します。
使用時期:
- あなたには、コーディングエージェントや財務エージェントなど、明確な専門分野やスキルセットがあります。
- 各エージェントは、会話履歴またはドメイン固有のプロンプトにアクセスできる必要があります。
- 利用できるツールが非常に多いため、それらすべてを1つのエージェントのスキーマに収めるのは現実的ではありません。各エージェントは、それらのツールのサブセットを所有することができます。
- 専門分野の担当者間で、振り返り、批判、あるいは双方向の協働を実現したいと考えているのですね。
利点:
- このモジュール式のアプローチにより、各エージェントは、狭い分野に特化した別々のチームによって開発または保守されることが可能になる。
- 単一のエージェントでは管理が困難な、大規模で複雑な企業ワークフローにも対応できます。
- 高度な複数ステップまたは複数視点からの推論を容易にします。例えば、あるエージェントが回答を生成し、別のエージェントがそれを検証するといった場合です。
考慮事項:
- エージェント間のルーティング戦略が必要となるほか、複数のエンドポイントにわたるログ記録、トレース、デバッグのためのオーバーヘッドも発生する。
- 多くのサブエージェントとツールがある場合、どのエージェントがどのデータまたは APIにアクセスできるかを決定するのは複雑になる可能性があります。
- 適切に制約を設けないと、エージェントはタスクを解決せずに際限なく相互にたらい回しにしてしまう可能性がある。単一エージェントによるツール呼び出しにも無限ループのリスクは存在するが、マルチエージェント構成ではデバッグの複雑さがさらに増す。
実践的なアドバイス
カスタムエージェントシステムを構築する必要がある場合、Databricks と Custom Agents は、選択するパターンに依存しないため、アプリケーションの成長に合わせて設計パターンを容易に進化させることができます。安定して保守可能なエージェントシステムを開発するための以下のベストプラクティスをご検討ください。
- まずは簡単なことから始めましょう。 単純なチェーンが必要なだけであれば、決定論的なチェーンは素早く構築できます。
- 徐々に複雑さを増していく: より動的なクエリや柔軟なデータソースが必要になったら、ツール呼び出し機能を備えたシングルエージェントシステムに移行する。明確に区別されたドメインやタスク、複数の会話コンテキスト、あるいは大規模なツールセットがある場合は、マルチエージェントシステムを検討してください。
- パターンを組み合わせる: 実際には、多くの現実世界のエージェントシステムはパターンを組み合わせています。例えば、ほぼ決定論的なチェーンには、必要に応じてLLM特定のAPIsを動的に呼び出すことができる1つの要素が含まれる可能性があります。
開発ガイダンス
-
プロンプトとツール
- 矛盾した指示や注意をそらす情報を避け、幻覚を軽減するために、指示は明確かつ最小限に抑えてください。
- エージェントが必要とするツールとコンテキストのみを提供し、無制限のAPIsセットや無関係な大量のコンテキストは提供しないでください。 設計段階で、使用するツールを選択する。
-
ロギングと可観測性
- MLflow Tracingを使用して、各ユーザーリクエスト、エージェントプラン、およびツール呼び出しの詳細なログ記録を実装します。
- ログは安全に保管し、会話データに含まれる個人情報(PII)に注意してください。自動化のためにデータ分類を検討してみましょう。
テストと反復に関するガイダンス
-
評価
- MLflow評価と本番運用モニタリングを使用して、開発と本番運用の評価メトリクスを定義します。
- 専門家やユーザーから人間によるフィードバックを収集して、自動評価メトリクスが適切に調整されていることを確認します。
-
エラー処理とフォールバックロジック
- ツールやLLMの故障に備えて計画を立てましょう。タイムアウト、不正な応答、または空の結果は、ワークフローを中断させる可能性があります。高度な機能が失敗した場合に備え、再試行戦略、フォールバックロジック、またはよりシンプルなフォールバックチェーンを組み込んでください。
-
反復的な改善
- プロンプトやエージェントのロジックは、今後徐々に改良されていく予定です。プロンプトのバージョン変更は、MLflowプロンプトレジストリを使用して行います。バージョン管理によって操作が簡素化され、ロールバックや比較が可能になります。
- 評価データを収集し、メトリクスを定義する際には、 MLflow Prompt Optimizationなどのより自動化された最適化手法を検討してください。
本番運用ガイダンス
-
モデルの更新とバージョンの固定
- LLM(法執行モデル)の運用方法は、プロバイダーが裏でモデルを更新すると変化する可能性がある。エージェントのロジックが堅牢かつ安定した状態を維持するために、バージョン固定と頻繁な回帰テストを実施してください。
-
レイテンシとコストの最適化
- LLMまたはツール呼び出しが増えるごとに、トークンの使用量と応答時間が増加します。可能な限り、繰り返し発生するクエリを結合またはキャッシュして、パフォーマンスとコストを管理可能な範囲に抑えてください。
-
セキュリティとサンドボックス
- エージェントがレコードを更新したりコードを実行したりできる場合は、それらの操作をサンドボックス化するか、必要に応じて人間の承認を強制してください。これは、企業環境や規制環境において、意図しない損害を回避するために非常に重要です。Unity Catalog機能は、本番運用のためのサンドボックス実行を提供します。
- ツールオプションに関する詳細なガイダンスについては、「エージェントをツールに接続する」を参照してください。
これらのガイドラインに従うことで、ツールの誤呼び出し、LLMパフォーマンスの変動、予期せぬコストの急増など、最も一般的な障害モードの多くを軽減し、より信頼性が高く、拡張性の高いエージェントシステムを構築できます。