RAGチェーン品質の改善
この記事では、RAGチェーンのコンポーネントを使用してRAGアプリの精度を向上させる方法について説明します。
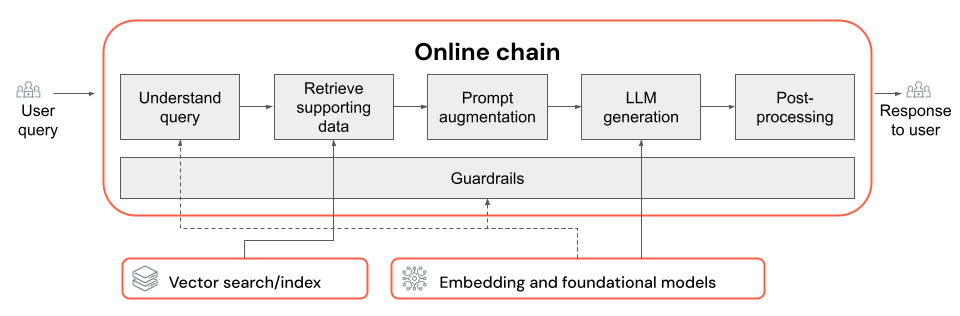
RAGチェーンは、ユーザーのクエリーを入力として受け取り、そのクエリーに基づいて関連情報を取得し、取得したデータに基づいて適切な応答を生成します。RAGチェーン内の正確なステップは、ユースケースと要件によって大きく異なる場合がありますが、RAGチェーンを構築する際に考慮すべき主要なコンポーネントは以下のとおりです。
- クエリーの理解: ユーザーのクエリーを分析および変換して、意図をより適切に表現し、フィルタやキーワードなどの関連情報を抽出することで、検索プロセスを改善します。
- **検索:** 検索クエリに基づいて、最も関連性の高い情報のチャンクを見つけること。非構造化データの場合、これは通常、セマンティック検索またはキーワードベースの検索の1つまたは組み合わせです。
- **プロンプト拡張:** ユーザー クエリを、取得した情報と指示と組み合わせて、LLM が高品質な応答を生成するようにガイドします。
- LLM: アプリケーションに最適なモデル (およびモデル パラメーター) を選択して、パフォーマンス、レイテンシ、およびコストを最適化/バランスします。
- 後処理とガードレール: LLMが生成した回答がトピックに沿っており、事実に一貫性があり、特定のガイドラインや制約に準拠していることを確認するために、追加の処理手順と安全対策を適用する。
3. AIエージェントの品質を反復的に改善するで、アプリの繰り返し評価および改善について詳しくご確認ください。
クエリの理解
ユーザーのクエリを検索クエリとして直接使用することは、一部のクエリで機能する場合があります。ただし、検索ステップの前にクエリを再定式化することは一般的に有益です。クエリの理解は、チェーンの最初に一連のステップで構成され、ユーザーのクエリを分析および変換して意図をよりよく表し、関連情報を抽出し、最終的にその後の検索プロセスを支援します。検索を改善するためにユーザーのクエリを変換するためのアプローチは次のとおりです。
-
クエリの書き換え: クエリの書き換えには、ユーザーのクエリを元の意図をより良く表現する1つ以上のクエリに変換することが含まれます。目的は、取得ステップが最も関連性の高いドキュメントを見つける可能性を高めるような方法でクエリを再構成することです。これは、取得ドキュメントで使用されている用語と直接一致しない可能性がある複雑または曖昧なクエリを扱う際に特に有用です。
例:
- マルチターンチャットにおける会話履歴の言い換え
- ユーザーのクエリのスペルミスを修正します。
- ユーザーのクエリー内の単語またはフレーズを同義語に置き換えて、より広範囲の関連ドキュメントを捕捉します
クエリの書き換えは、検索コンポーネントの変更と併せて行う必要があります。
-
フィルター抽出: 場合によっては、ユーザーのクエリに、検索結果を絞り込むために使用できる特定のフィルターや基準が含まれている可能性があります。フィルター抽出には、クエリからこれらのフィルターを特定して抽出し、追加のパラメーターとして検索ステップに渡すことが含まれます。これは、利用可能なデータの特定のサブセットに焦点を当てることで、取得されたドキュメントの関連性を改善するのに役立ちます。
例:
- クエリで言及されている特定の期間(例えば「過去6か月間の記事」や「2023年のレポート」)を抽出します。
- クエリ内の特定の製品、サービス、またはカテゴリ (「Databricks プロフェッショナル サービス」や「ラップトップ」など) の言及を特定します。
- クエリーから、都市名や国コードなどの地理的エンティティを抽出します。
フィルター抽出は、メタデータ抽出データパイプラインとリトリーバーチェーンコンポーネントの両方への変更と組み合わせて行う必要があります。メタデータ抽出ステップでは、各ドキュメント/チャンクで関連するメタデータフィールドが利用可能であることを確認し、抽出されたフィルターを受け入れて適用するように検索ステップを実装する必要があります。
クエリーの書き換えとフィルターの抽出に加えて、クエリーの理解におけるもう1つの重要な考慮事項は、単一のLLM呼び出しを使用するか、複数の呼び出しを使用するかです。慎重に作成されたプロンプトで単一の呼び出しを使用することは効率的ですが、クエリー理解プロセスを複数のLLM呼び出しに分解することで、より良い結果が得られる場合があります。ちなみに、これは複雑なロジックの複数のステップを単一のプロンプトに実装しようとする際に一般的に適用される経験則です。
たとえば、クエリの意図を分類するために 1 つの LLM 呼び出しを使用し、関連するエンティティを抽出するために別の呼び出しを使用し、抽出された情報に基づいてクエリを書き換えるために 3 番目の呼び出しを使用することができます。このアプローチでは、プロセス全体に多少のレイテンシーが追加される可能性がありますが、よりきめ細かな制御が可能になり、取得されたドキュメントの品質が向上する可能性があります。
サポートボットのためのマルチステップクエリー理解
顧客サポートボット向けの多段階クエリ理解コンポーネントの例は次のとおりです:
- 意図の分類: LLM を使用して、ユーザーのクエリを「製品情報」、「トラブルシューティング」、または「アカウント管理」などの定義済みのカテゴリに分類します。
- エンティティ抽出: 特定された意図に基づいて、製品名、報告されたエラー、アカウント番号などの関連するエンティティをクエリから抽出するために、別のLLM呼び出しを使用します。
- クエリの書き換え: 抽出された意図とエンティティを使用して、元のクエリをより具体的でターゲットを絞った形式に書き換えます。例えば、「RAGチェーンがModel Servingにデプロイできません。次のエラーが表示されています…」
検索
RAGチェーンの検索コンポーネントは、検索クエリーに基づいて最も関連性の高い情報のチャンクを見つける役割を担います。非構造化データの場合、検索には通常、セマンティック検索、キーワードベースの検索、メタデータフィルタリングのいずれか、またはそれらの組み合わせが伴います。検索戦略の選択は、アプリケーションの特定の要件、データの性質、および処理を想定するクエリーの種類に依存します。これらのオプションを比較してみましょう。
- **セマンティック検索:** セマンティック検索では、埋め込みモデルを使用して各テキストチャンクをベクトル表現に変換し、その意味的意味を捉えます。検索クエリのベクトル表現とチャンクのベクトル表現を比較することで、セマンティック検索は、クエリの正確なキーワードが含まれていなくても、概念的に類似したドキュメントを取得できます。
- キーワードベースの検索: キーワードベースの検索は、取得クエリとインデックス付きドキュメントの間で共有語の頻度と分布を分析することによって、ドキュメントの関連性を判断します。クエリとドキュメントの両方で同じ単語が頻繁に出現するほど、そのドキュメントに割り当てられる関連性スコアが高くなります。
- **ハイブリッド検索**:ハイブリッド検索は、セマンティック検索とキーワードベースの検索の両方の強みを組み合わせたもので、2段階の検索プロセスを採用しています。まず、セマンティック検索を実行して、概念的に関連性の高いドキュメントのセットを取得します。次に、この絞り込まれたセットにキーワードベースの検索を適用し、正確なキーワード一致に基づいて結果をさらに絞り込みます。最後に、両方のステップのスコアを組み合わせてドキュメントをランク付けします。
取得戦略の比較
次の表は、それぞれの検索戦略を互いに対比しています:
セマンティック検索 | キーワード検索 | ハイブリッド検索 | |
|---|---|---|---|
簡単な説明 | クエリと潜在的なドキュメントに同じ**概念**が含まれている場合、それらは関連性があります。 | クエリと可能性のあるドキュメントに同じ**単語**が出現する場合、それらは関連性があります。ドキュメント内のクエリからの**単語**が多いほど、そのドキュメントは関連性が高くなります。 | セマンティック検索とキーワード検索の両方を実行し、結果を結合します。 |
使用例 | 製品マニュアルの用語と異なるユーザーのクエリに対する顧客サポート。例: 「携帯電話の電源をオンにするにはどうすればよいですか?」、マニュアルのセクションは「電源の切り替え」という名称です。 | 特定の非記述的な専門用語を含むクエリに関する顧客サポート例: 「モデル HD7-8D は何をしますか?」 | セマンティック用語とテクニカル用語の両方を組み合わせた顧客サポートクエリ。例: 「HD7-8Dの電源をどうすれば入れられますか?」 |
テクニカルアプローチ | エンベディングを使用して連続ベクトル空間でテキストを表し、セマンティック検索を可能にします。 | キーワードマッチングのために、bag-of-words、TF-IDF、BM25のような個別トークンベースのメソッドを使用します。 | Reciprocal Rank Fusionや再ランク付けモデルなどの再ランク付けアプローチを使用して、結果を結合します。 |
強み | 正確な単語が使用されていない場合でも、クエリーに対して文脈的に類似した情報を取得します。 | 製品名などの特定の用語に焦点を当てたクエリに最適な、正確なキーワードの一致を必要とするシナリオです。 | 両者の長所を組み合わせています。 |
検索プロセスを強化する方法
これらの主要な検索戦略に加えて、検索プロセスをさらに強化するために適用できるいくつかの手法があります。
- クエリ拡張: クエリ拡張は、取得クエリの複数のバリエーションを使用することで、より広範囲の関連ドキュメントを取り込むのに役立ちます。これは、拡張された各クエリに対して個別に検索を実行するか、すべての拡張された検索クエリを単一の取得クエリで連結することで実現できます。
クエリ拡張は、クエリ理解コンポーネント (RAG チェーン) の変更と合わせて行う必要があります。検索クエリの複数のバリエーションは、通常このステップで生成されます。
- リランキング: チャンクの初期セットを取得したら、追加のランク付け条件 (時間による並べ替えなど) またはリランカーモデルを適用して結果を並べ替えます。 リランキングは、特定の取得クエリに対して最も関連性の高いチャンクに優先順位を付けるのに役立ちます。 mxbai-rerank や ColBERTv2 などのクロスエンコーダーモデルでリランキングすると、検索パフォーマンスが向上する可能性があります。
- **メタデータ フィルター:** クエリ理解ステップから抽出されたメタデータ フィルターを使用して、特定の基準に基づいて検索スペースを絞り込みます。メタデータ フィルターには、ドキュメント タイプ、作成日、作成者、またはドメイン固有のタグなどの属性を含めることができます。メタデータ フィルターとセマンティックまたはキーワードベースの検索を組み合わせることで、より的を絞った効率的な取得を作成できます。
メタデータフィルタリングは、クエリ理解 (RAG チェーン) とメタデータ抽出 (データパイプライン) コンポーネントの変更と併せて行う必要があります。
プロンプトの拡張
プロンプト拡張は、ユーザー クエリをプロンプト テンプレートで取得した情報と指示と組み合わせて、言語モデルを高品質の応答を生成するようにガイドするステップです。 このテンプレートを反復処理して LLM に提供されるプロンプト (別名 プロンプトエンジニアリング ) を最適化するには、モデルが正確で接地された一貫性のある応答を生成するようにガイドされるようにする必要があります。
プロンプトエンジニアリングに関する完全なガイドがありますが、プロンプトテンプレートを反復処理する際に留意すべき点をいくつか示します。
-
例を挙げてください
- 整形式のクエリとそれに対応する理想的な応答の例をプロンプトテンプレート自体に含めます(few-shot学習)。 これにより、モデルは応答の目的の形式、スタイル、および内容を理解できます。
- 良い例を考案する1つの有効な方法は、チェーンが苦戦しているクエリのタイプを特定することです。これらのクエリに対してゴールドスタンダードの回答を作成し、プロンプトに例として含めます。
- 提供する例が、推論時に予測されるユーザーのクエリを代表していることを確実にしてください。モデルがより良く一般化できるように、予測される多様なクエリを網羅することを目指してください。
-
プロンプトテンプレートをパラメーター化する
- 取得されたデータとユーザー クエリに加えて追加情報を取り込むために、プロンプトテンプレートをパラメータ化して柔軟に対応できるように設計します。これらは、現在の日付、ユーザーコンテキスト、またはその他の関連するメタデータのような変数である可能性があります。
- 推論時にこれらの変数をプロンプトに挿入すると、よりパーソナライズされた応答やコンテキストを考慮した応答が可能になります。
-
チェーンオブソートを検討する
- 直接的な回答がすぐには明らかではない複雑なクエリの場合は、Chain-of-Thought (CoT) プロンプトを検討してください。このプロンプトエンジニアリング戦略は、複雑な質問をよりシンプルで順序だったステップに分解し、LLMを論理的な推論プロセスを通じてガイドします。
- モデルに「問題をステップバイステップで検討する」ように促すことで、より詳細で説得力のある応答を提供するように促し、複数ステップまたはオープンエンドのクエリの処理に特に効果的です。
-
プロンプトはモデル間で引き継がれない可能性があります。
- プロンプトは多くの場合、異なる言語モデル間でシームレスに転送されないことを認識します。各モデルには独自の特性があり、あるモデルでうまく機能するプロンプトが別のモデルでは効果的でない場合があります。
- さまざまなプロンプト形式と長さをエクスペリメントします。オンラインガイド(OpenAI CookbookやAnthropic cookbookなど)を参照し、モデルを切り替える際には、プロンプトを調整および改良する準備をしてください。
LLM
RAGチェーンの生成コンポーネントは、前のステップから拡張されたプロンプトテンプレートを受け取り、LLMに渡します。RAGチェーンの生成コンポーネント用のLLMを選択および最適化する際には、LLM呼び出しを含む他のどのステップにも同様に適用される以下の要素を考慮してください。
-
さまざまな既製のモデルを用いた実験。
- 各モデルには、独自のプロパティ、長所、短所があります。一部のモデルは、特定のドメインをよりよく理解している場合や、特定のタスクでより優れたパフォーマンスを発揮する場合があります。
- 前述のとおり、異なるモデルでは同じプロンプトに対して異なる応答をする可能性があるため、モデルの選択がプロンプトエンジニアリングプロセスに影響を与える可能性があることに留意してください。
- 生成ステップに加えてクエリ理解のための呼び出しなど、チェーン内にLLMを必要とする複数のステップがある場合は、異なるステップに異なるモデルを使用することを検討してください。より高価な汎用モデルは、ユーザーのクエリの意図を判断するなどのタスクには過剰である場合があります。
-
小さく始めて、必要に応じてスケールアップしてください。
- 利用可能な最も強力で高性能なモデル(例:GPT-4、Claude)をすぐに利用したくなるかもしれませんが、多くの場合、より小規模で軽量なモデルから始める方が効率的です。
- 多くの場合、Llama 3のような小規模なオープンソースの代替手段は、低コストで、より高速な推論時間で満足のいく結果を提供できます。これらのモデルは、高度に複雑な推論や広範な世界知識を必要としないタスクに特に効果的です。
- RAGチェーンを開発し、改良するにつれて、選択したモデルのパフォーマンスと制限を継続的に評価してください。モデルが特定の種類のクエリを苦手としたり、十分に詳細または正確な応答を提供できない場合は、より高性能なモデルにスケールアップすることを検討してください。
- 応答品質、レイテンシー、コストなどの主要なメトリクスに対するモデル変更の影響を監視し、特定のユースケースの要件に適切なバランスをもたらすようにしてください。
-
モデルパラメーターの最適化
- エクスペリメントをさまざまなパラメーター設定で使用して、応答の品質、多様性、一貫性の最適なバランスを見つけます。 たとえば、温度を調整すると、生成されるテキストのランダム性を制御でき、max_tokensで応答の長さを制限できます。
- 最適なパラメーター設定は、特定のタスク、プロンプト、および目的の出力スタイルによって異なる場合があることに注意してください。生成された応答の評価に基づいて、これらの設定を繰り返しテストし、改良します。
-
タスク固有のファインチューニング
- パフォーマンスを向上させる際には、クエリ理解など、RAGチェーン内の特定のサブタスクのために、より小さなモデルをファインチューニングすることを検討してください。
- RAGチェーンを使用して個々のタスク向けに特化したモデルをトレーニングすることで、単一の大規模モデルをすべてのタスクに使用する場合と比較して、全体的なパフォーマンスを向上させ、レイテンシーを削減し、推論コストを低減できる可能性があります。
-
継続的な事前学習
- RAGアプリケーションが特殊なドメインを扱っている場合や、事前トレーニング済みのLLMで十分に表現されていない知識が必要な場合は、ドメイン固有のデータに対する継続的な事前トレーニング(CPT)の実施を検討してください。
- 継続的な事前トレーニングにより、特定の専門用語や、お客様のドメインに固有の概念に対するモデルの理解を向上させることができます。これにより、大規模なプロンプトエンジニアリングの必要性や、few-shotの例を減らすことができます。
後処理とガードレール
LLM が応答を生成した後、出力が必要な形式、スタイル、コンテンツ要件を満たしていることを確認するために、後処理技術またはガードレールを適用することがよく必要です。チェーン内のこの最終ステップ (または複数のステップ) は、生成された応答全体で一貫性と品質を維持するのに役立ちます。後処理とガードレールを実装している場合は、以下の点をいくつか考慮してください:
-
出力フォーマットの適用
- ユースケースに応じて、生成された応答が構造化テンプレートや特定のファイルタイプ(JSON、HTML、Markdownなど)などの特定のフォーマットに準拠する必要がある場合があります。
- 構造化出力が必要な場合、InstructorやOutlinesのようなライブラリは、この種の検証ステップを実装するための良い出発点となります。
- 開発時には、後処理ステップが、生成される応答のバリエーションに対応しつつ、必要な形式を維持できるよう、十分に柔軟であることを確認してください。
-
スタイルの一貫性の維持
- RAGアプリケーションに特定のスタイルガイドラインやトーン要件がある場合(例: フォーマルとカジュアル、簡潔と詳細など)、後処理ステップで生成された応答全体にこれらのスタイル属性を確認し、適用できます。
-
コンテンツフィルターと安全ガードレール
- RAG アプリケーションの性質や生成コンテンツに関連する潜在的なリスクによっては、不適切、不快、または有害な情報の出力を防ぐために、コンテンツフィルターまたは安全ガードレールを実装することが重要な場合があります。
- LlamaGuard のようなモデルや、APIOpenAIのモデレーションAPI など、コンテンツのモデレーションと安全性のために特別に設計された を使用して、安全ガードレールを実装することを検討してください。
-
ハルシネーションの対処。
- ハルシネーションに対する防御は、後処理ステップとして実装することもできます。これには、生成された出力を取得したドキュメントと相互参照すること、または追加のLLMを使用して応答の事実の正確性を検証することが含まれる場合があります。
- 生成された応答が事実の正確性要件を満たさない場合に備えて、代替応答の生成やユーザーへの免責事項の提供など、フォールバックメカニズムを開発します。
-
エラー処理
- 後処理のステップでは、ステップで問題が発生したり、満足のいく応答が生成されなかったりする場合に、適切に対処するための仕組みを導入してください。これには、デフォルトの応答を生成することや、問題を人間のオペレーターにエスカレートして手動でレビューすることが含まれる場合があります。