コーディングエージェントと統合します
ベータ版
この機能はベータ版です。アカウント管理者は、アカウント コンソールの [プレビュー] ページからこの機能へのアクセスを制御できます。 Databricksのプレビューを管理するを参照してください。
Databricksコーディングエージェント統合により、Cursor、Gemini CLI、Codex CLIのようなコーディングエージェントからのトラフィックを、Unity AI Gatewayのモデルサービスを介してルーティングできます。これにより、レート制限、使用状況の追跡、および推論テーブルが提供されます—すべての制御はモデルサービス、ユーザー、またはグループレベルで構成されます。
機能
- アクセス: さまざまなコーディングツールとモデルへの直接アクセス、すべてを単一の請求書で。
- 可観測性 :すべてのコーディングツールにおける使用状況、支出、メトリクスを追跡するための単一の統合ダッシュボードです。
- 統合ガバナンス :管理者は、Unity AI Gatewayを介して、モデルサービス、ユーザー、またはグループレベルでモデルのアクセス許可とレート制限を管理できます。
要件
- お客様のアカウントでUnity AI Gatewayのプレビュー版が有効になりました。Databricksのプレビューを管理するを参照してください。
- Unity AI GatewayでサポートされているリージョンにあるDatabricksワークスペース。
- ワークスペースでUnity Catalog有効化されていること。 Unity Catalog のワークスペースを有効にする方法をご覧ください。
セットアップ
最も簡単な開始方法は、ucodeです。これは、Databricksが提供するCLIであり、サポートされているコーディングエージェントをUnity AI Gatewayとともに1つのコマンドでインストール、認証、および構成します。
ucodeを使用(推奨)
ucode (Unity AI Gateway Coding CLI) は、Unity AI Gateway に対してコーディングエージェントを実行するための単一のエントリポイントです。OAuth を処理し、各エージェントの設定ファイルを書き込み、登録した LLM または MCP サーバーを介してトラフィックをルーティングします。サポートされているエージェント:
ステップ1:ucodeをインストールします
uv tool install git+https://github.com/databricks/ucode
Python 3.12以降とuvが必要です。
ステップ2: コーディングエージェントを開く
目的のエージェントを実行してください。初回起動時、ucodeはDatabricksワークスペースのURLを求め、認証し、エージェントの構成ファイルを自動的に書き込みます。以降の起動では、エージェントに直接アクセスします。
ucode codex # OpenAI Codex
ucode gemini # Gemini CLI
ucode opencode # OpenCode
ucode copilot # GitHub Copilot CLI
ucode pi # Pi
ucode エージェント名の後にフラグを下層ツールに渡します。例:
ucode codex --full-auto
複数のコーディング エージェントを同時に構成するには、以下を実行します。
ucode configure
Databricks MCPサーバー(Unity Catalog関数、AI Search、SQLウェアハウス、および検出された外部接続)をMCP対応エージェントに登録するには:
ucode configure mcp
過去 7 日間の Unity AI Gateway の使用状況の概要を確認するには:
ucode usage
完全なコマンドリファレンスについては、以下を実行します:
ucode --help
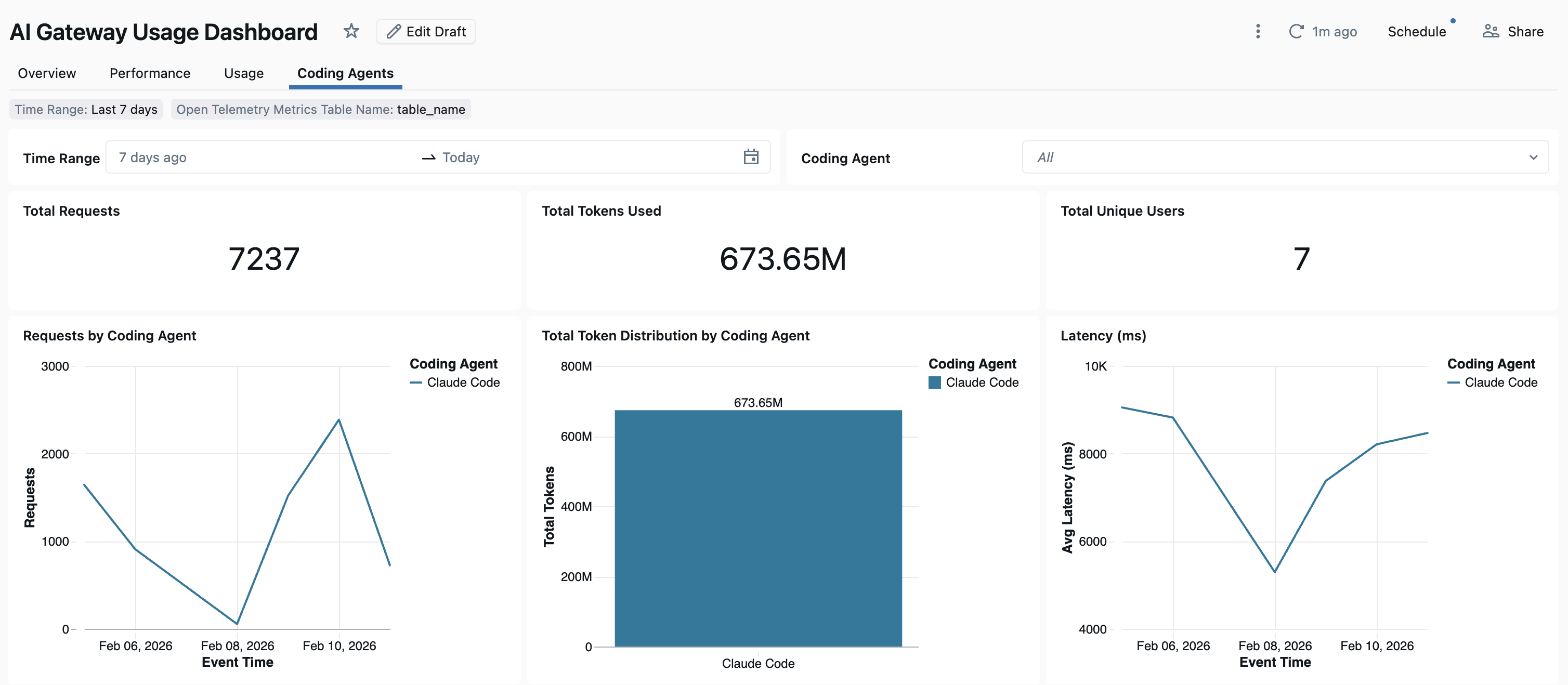
ダッシュボード
Unity AI Gatewayを介してコーディングエージェントの使用状況が追跡された後、組み込みダッシュボードでメトリクスを表示および監視できます。
ダッシュボードを開くには、AI Gatewayページから [ダッシュボードの表示] を選択します。このアクションにより、コーディングツール使用状況のグラフを含む、事前構成済みのダッシュボードが作成されます。
手動セットアップ
エージェントを自分で設定する場合は、次の手順に従ってください:
Cursor IDE
Unity AI Gateway でモデルサービスを使用するように Cursor を構成するには:
ステップ1:ベースURLとAPIキーを設定します
-
Cursorを開き、 設定 → Cursor設定 → モデル → APIキー に移動します。
-
[OpenAIベースURLを上書き] を有効にし、URLを入力します。
https://<workspace-url>/ai-gateway/cursor/v1<workspace-url>を Databricks ワークスペースの URL に置き換えます。 -
Databricks個人用アクセストークンを OpenAI API Key フィールドに貼り付けます。
ステップ2: カスタムモデルを追加
- Cursor Settingsで + カスタムモデルを追加 をクリックします。
- モデルのサービス名 (例:
system.ai.databricks-claude-opus-4-6) を追加し、トグルを有効にします。
現在、Databricksが提供するモデルサービスのみがサポートされています。
ステップ3: 統合をテスト
Cmd+L(macOS) またはCtrl+L(Windows/Linux) を使用してAskモードを開き、モデルを選択してください。- メッセージを送信してください。すべてのリクエストがDatabricksを経由するようになりました。
Codex CLI
ステップ1:Codex CLIをインストールまたは更新
Codex CLIバージョン0.118以降をインストールまたは更新します。
npm install -g @openai/codex@latest
ステップ2:Codex設定ファイルを作成または更新
~/.codex/config.tomlでCodex設定ファイルを作成または編集します:
profile = "default"
[profiles.default]
model_provider = "Databricks"
[model_providers.Databricks]
name = "Databricks :re[ai-gateway]"
base_url = "<workspace-url>/ai-gateway/codex/v1"
wire_api = "responses"
[model_providers.Databricks.auth]
command = "sh"
args = ["-c", "databricks auth token --host <workspace-url> --output json | jq -r '.access_token'"]
timeout_ms = 5000
refresh_interval_ms = 1800000
<workspace-url> を Databricks ワークスペースの URL に置き換えます。
ステップ3:ワークスペースを認証
これは一度だけ実行する必要があります。Codexを開始するたびに再認証する必要はありません。
まず、Databricks CLIがインストールされていることを確認してください。手順については、Databricks CLIのインストールまたは更新を参照してください。
次に認証します。
databricks auth login --host <workspace-url>
<workspace-url> を Databricks ワークスペースの URL に置き換えます。
ステップ4:Codexを起動
codex
モデルを変更するには、/modelを使用してください。
Gemini CLI
ステップ1: Gemini CLIの最新バージョンをインストールします。
npm install -g @google/gemini-cli@nightly
ステップ2: 環境変数を構成する
~/.gemini/.envというファイルを作成し、次の構成を追加します。詳細については、Gemini CLI認証ドキュメントを参照してください。
GEMINI_MODEL=databricks-gemini-2-5-flash
GOOGLE_GEMINI_BASE_URL=https://<workspace-url>/ai-gateway/gemini
GEMINI_API_KEY_AUTH_MECHANISM="bearer"
GEMINI_API_KEY=<databricks_pat_token>
<workspace-url>をDatabricksワークスペースURLに、<databricks_pat_token>を個人アクセストークンに置き換えます。
OpenTelemetryデータ収集を設定
Databricksは、コーディングエージェントからのOpenTelemetryメトリクスとログをUnity CatalogマネージドDeltaテーブルにエクスポートすることをサポートしています。すべてのメトリクスは、OpenTelemetry標準メトリクスプロトコルを使用してエクスポートされた時系列データであり、ログはOpenTelemetryログプロトコルを使用してエクスポートされます。
要件
- DatabricksのOpenTelemetryプレビューが有効になりました。「Databricks プレビューの管理」を参照してください。
ステップ1: Unity CatalogでOpenTelemetryテーブルを作成します
OpenTelemetryメトリクスおよびログスキーマで事前構成されたUnity Catalogマネージドテーブルを作成します。
メトリクス テーブル
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_metrics (
name STRING,
description STRING,
unit STRING,
metric_type STRING,
gauge STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
sum STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
aggregation_temporality: STRING,
is_monotonic: BOOLEAN
>,
histogram STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
bucket_counts: ARRAY<LONG>,
explicit_bounds: ARRAY<DOUBLE>,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
min: DOUBLE,
max: DOUBLE,
aggregation_temporality: STRING
>,
exponential_histogram STRUCT<
attributes: MAP<STRING, STRING>,
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
scale: INT,
zero_count: LONG,
positive_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
negative_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
flags: INT,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
min: DOUBLE,
max: DOUBLE,
zero_threshold: DOUBLE,
aggregation_temporality: STRING
>,
summary STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
quantile_values: ARRAY<STRUCT<
quantile: DOUBLE,
value: DOUBLE
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
metadata MAP<STRING, STRING>,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
metric_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
ログテーブル
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_logs (
event_name STRING,
trace_id STRING,
span_id STRING,
time_unix_nano LONG,
observed_time_unix_nano LONG,
severity_number STRING,
severity_text STRING,
body STRING,
attributes MAP<STRING, STRING>,
dropped_attributes_count INT,
flags INT,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
log_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
ステップ2: コーディングエージェントの環境変数を更新
OpenTelemetryメトリクスのサポートを有効にした任意のコーディングエージェントで、次の環境変数を設定します。
{
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_METRICS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_METRICS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/metrics",
"OTEL_EXPORTER_OTLP_METRICS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_metrics",
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_LOGS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_LOGS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/logs",
"OTEL_EXPORTER_OTLP_LOGS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_logs",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"
}
ステップ3: コーディングエージェントを実行します。
データは5分以内にUnity Catalogテーブルに反映されます。