モデルサービングエンドポイントでの AI Gateway の構成
新しいUnity AI Gatewayベータ版をお試しください
新しいUnity AI Gatewayエクスペリエンスがベータ版で利用可能です。新しいUnity AI Gatewayは、拡張された機能を持つLLMエンドポイントとコーディングエージェントを管理するためのエンタープライズコントロールプレーンです。Unity AI GatewayによるAIガバナンスを参照してください。
この記事では、モデルサービング エンドポイントでAI Gatewayを構成する方法を学習します。
必要条件
-
モデルサービングがサポートされている地域の Databricks ワークスペース。 モデル サービング機能の可用性を参照してください。
-
A モデルサービング エンドポイント. ワークスペースで 事前設定されたトークン単位の従量課金エンドポイント のいずれかを使用するか、次の操作を実行できます。
- 外部モデルのエンドポイントを作成するには、 外部モデルサービングエンドポイントの作成のステップ 1 と 2 を実行します。
- プロビジョニング スループットのエンドポイントを作成するには、プロビジョニング スループット 基盤モデル APIを参照してください。
- カスタムモデルのエンドポイントを作成するには、「 エンドポイントの作成」を参照してください。
-
エンドポイントの管理者操作には、そのエンドポイントに対する
CAN MANAGEが必要です。「アクセス制御リスト」を参照してください。 -
作成時、作成者には新しいエンドポイントに対して
CAN MANAGEが付与されます。 -
ガードレールやスループット制限のバイパスを防ぐため、エンドポイントの作成と
CAN MANAGEを管理者に限定し、他のユーザーには承認済みエンドポイントに対するクエリ権限のみを付与してください。
UIを使用してUnity AI Gatewayを設定する
エンドポイント作成ページの 「AI Gateway」 セクションでは、Unity AI Gatewayの機能を個別に設定できます。外部モデルサービング エンドポイントおよびプロビジョニング スループット エンドポイントで利用できる機能については、 「サポートされている機能」を参照してください。
以下の表は、Serving UIを使用してエンドポイントを作成する際にUnity AI Gatewayを設定する方法をまとめたものです。プログラムでこれを実行する場合は、ノートブックの例を参照してください。
機能 | 有効にする方法 | 詳細 |
|---|---|---|
使用状況の追跡 | 使用状況の追跡を有効にする を選択して、データ使用量メトリクスの追跡と監視を有効にします。 |
|
ペイロードのロギング | [ 推論テーブルを有効にする ] を選択すると、エンドポイントからの要求と応答が Unity Catalog によって管理される Delta テーブルに自動的に記録されます。 |
|
UI での AI ガードレールの設定を参照してください。 |
| |
レート制限 | [レート制限] を選択して、エンドポイントがサポートできる毎分のクエリ数 (QPM) または毎分トークン数 (TPM) を管理および指定します。
|
|
トラフィック分割 | サーブされるエンティティ セクションで、特定のモデルにルーティングする トラフィックの割合 を指定します。 エンドポイントのトラフィック分割をプログラムで設定するには、エンドポイントに複数の外部モデルを提供するを参照してください。 |
|
フォールバック | [AI Gateway] セクションで [ フォールバックの有効化 ] を選択して、エンドポイント上の他の提供モデルにフォールバックとしてリクエストを送信します。 |
|
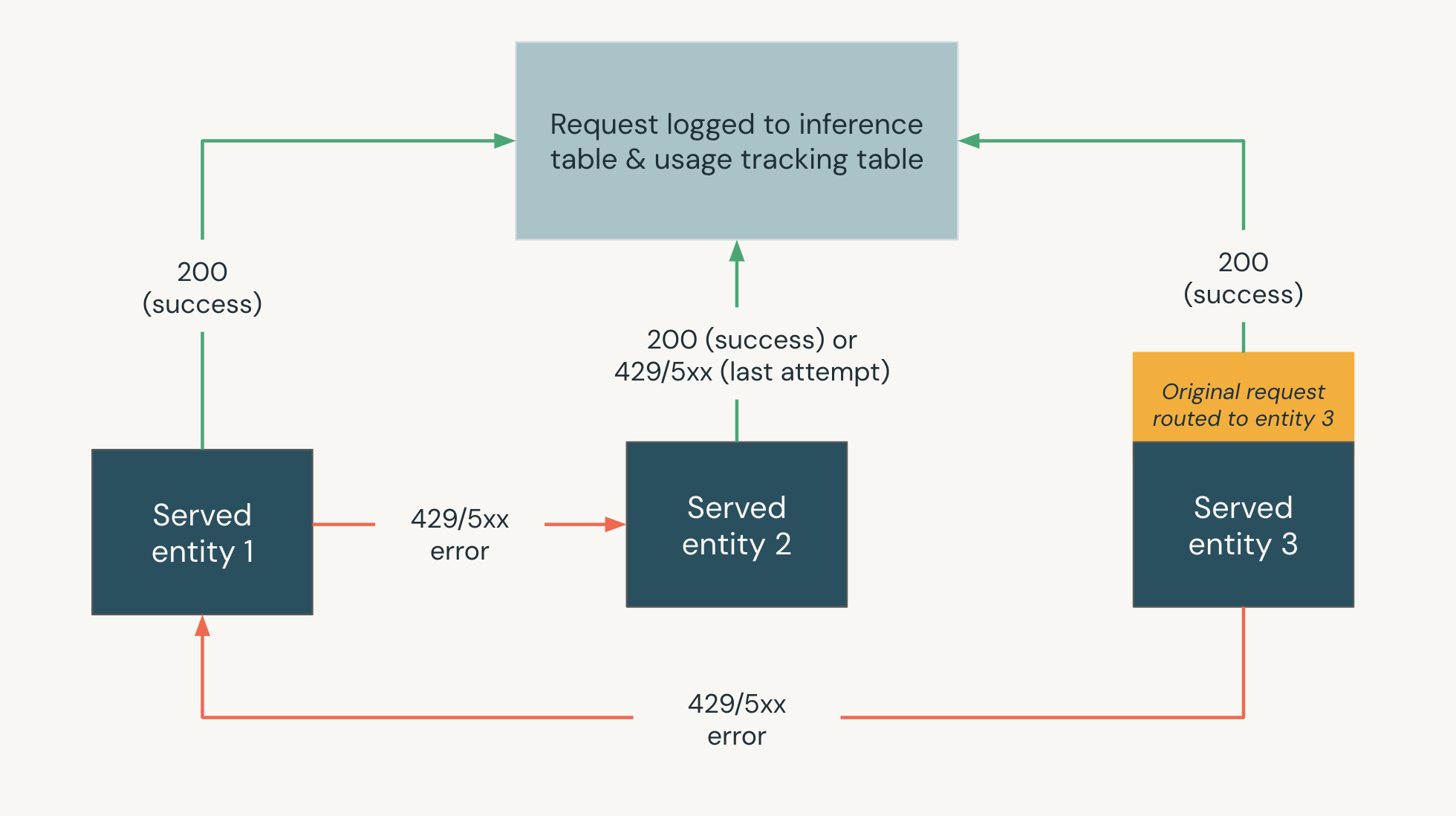
次の図は、フォールバックの例を示しています。
- 3 つのサーブされたエンティティは、モデル サービング エンドポイントで提供されます。
- 要求は最初に サーブされるエンティティ 3 にルーティングされます。
- リクエストが 200 レスポンスを返した場合、リクエストは サーブされるエンティティ 3 で成功し、リクエストとそのレスポンスはエンドポイントの使用状況追跡テーブルとペイロードロギングテーブルに記録されます。
- 要求が サーブされる エンティティ 3 で 429 または 5xx エラーを返した場合、要求はエンドポイントで次に提供されるエンティティである サーブされる エンティティ 1 にフォールバックします。
- リクエストが サーブされる エンティティ 1 で 429 または 5xx エラーを返した場合、リクエストはエンドポイントで次に提供されたエンティティである サーブされる エンティティ 2 にフォールバックします。
- 要求が サーブされる エンティティ 2 で 429 または 5xx エラーを返した場合、これがフォールバック エンティティの最大数であるため、要求は失敗します。失敗したリクエストとレスポンスエラーは、使用状況追跡テーブルとペイロードロギングテーブルに記録されます。
UI での AI ガードレールの構成
プレビュー
この機能は パブリック プレビュー段階です。
次の表は、 サポートされているガードレールを構成する方法を示しています。
ガードレール | 有効にする方法 |
|---|---|
安全性 | [ 安全性 ] を選択すると、モデルが安全でない有害なコンテンツと相互作用するのを防ぐための保護機能が有効になります。 |
個人を特定できる情報 (PII) の検出 | 名前、住所、クレジット カード番号などの PII データがエンドポイントの要求と応答で検出された場合に、 それらをブロック または マスク することを選択します。 それ以外の場合は、[ なし ] を選択して PII 検出が発生しないようにします。 |

使用状況追跡テーブルのスキーマ
次のセクションでは、 system.serving.served_entities および system.serving.endpoint_usage システムテーブルの使用状況追跡テーブル スキーマをまとめます。
system.serving.served_entities 使用状況追跡テーブル スキーマ
system.serving.served_entities使用状況追跡システムテーブルには、次のスキーマがあります。
列名 | 説明 | タイプ |
|---|---|---|
| 提供されたエンティティの一意の ID。 | 文字列 |
| OpenSharing の顧客アカウントIDです。 | 文字列 |
| サービスエンドポイントの顧客ワークスペース ID。 | 文字列 |
| 作成者の名前。ユーザー、サービスプリンシパル、またはグループ名を指定できます。 VPN単位の従量課金エンドポイントの場合、これは | 文字列 |
| サービングエンドポイントの名前。 | 文字列 |
| サービングエンドポイントの一意の ID。 | 文字列 |
| 提供されるエンティティの名前。 | 文字列 |
| 提供されるエンティティのタイプ。 | 文字列 |
| エンティティの基になる名前。 ユーザーが指定した名前である | 文字列 |
| 提供されたエンティティのバージョン。 | 文字列 |
| エンドポイント設定のバージョン。 | INT |
| タスクの種類。 | 文字列 |
| 外部モデルの構成。 例えば | 構造体 |
| 基盤モデルの構成。 例えば | 構造体 |
| カスタムモデルの設定。 例えば | 構造体 |
| 機能仕様の構成。 例えば | 構造体 |
| 提供されたエンティティの変更のタイムスタンプ。 | TIMESTAMP |
| エンティティ削除のタイムスタンプ。 エンドポイントは、提供されるエンティティのコンテナです。 エンドポイントが削除されると、提供されたエンティティも削除されます。 | TIMESTAMP |
system.serving.endpoint_usage 使用状況追跡テーブル スキーマ
system.serving.endpoint_usage使用状況追跡システムテーブルには、次のスキーマがあります。
列名 | 説明 | タイプ |
|---|---|---|
| 顧客アカウント ID。 | 文字列 |
| サービスエンドポイントの顧客ワークスペース ID。 | 文字列 |
| モデルサービング要求本文で指定できるユーザー指定の要求識別子。 カスタムモデルエンドポイントの場合、これは 4MiB を超えるリクエストではサポートされていません。 | 文字列 |
| すべてのモデルサービング要求にアタッチされた Databricks 生成要求識別子。 | 文字列 |
| サービスエンドポイントの呼び出しリクエストにアクセス許可が使用されるユーザーまたはサービスプリンシパルの ID。 | 文字列 |
| モデルから返された HTTP 状態コード。 | Integer |
| 要求が受信されたタイムスタンプ。 | TIMESTAMP |
| 入力のトークン数。カスタム モデル要求の場合は 0 になります。 | ロング |
| 出力のトークン数。カスタム モデル要求の場合は 0 になります。 | ロング |
| 入力文字列またはプロンプトの文字数。カスタム モデル要求の場合は 0 になります。 | ロング |
| 応答の出力文字列の文字数。カスタム モデル要求の場合は 0 になります。 | ロング |
| ユーザーは、エンドポイントへの呼び出しを行うエンド ユーザーまたは顧客アプリケーションの識別子を含むマップを提供しました。 | マップ |
| 要求がストリーム・モードであるかどうか。 | ブール値 |
| エンドポイントと提供されるエンティティに関する情報を検索するために | 文字列 |
使用法をさらに定義する usage_context
使用状況の追跡が有効になっている外部モデルに対してクエリを実行する場合は、 usage_context パラメーターに Map[String, String]型を指定できます。 使用状況コンテキスト マッピングは、使用状況追跡テーブルの usage_context 列に表示されます。 usage_contextマップサイズは 10 KiB を超えることはできません。
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
OpenAI Python クライアントを使用している場合は、extra_body パラメーターに usage_context を含めることで指定できます。
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=[{"role": "user", "content": "What is Databricks?"}],
temperature=0,
extra_body={"usage_context": {"project": "project1"}},
)
answer = response.choices[0].message.content
print("Answer:", answer)
アカウント 管理者は、使用状況のコンテキストに基づいて異なる行を集計して知見を得ることができ、この情報をペイロードログテーブルの情報と結合することができます。 たとえば、エンドユーザーのコスト属性を追跡するための end_user_to_charge を usage_context に追加できます。
エンドポイントの使用状況を監視する
エンドポイントの使用状況をモニタリングするために、エンドポイントのシステムテーブルと推論テーブルを結合できます。
Join システムテーブル
この例は、外部、プロビジョニング スループット、仮想単位の従量課金、およびカスタム モデル エンドポイントに適用されます。
endpoint_usage システムテーブルと served_entities システムテーブルを結合するには、次の SQL を使用します。
SELECT * FROM system.serving.endpoint_usage as eu
JOIN system.serving.served_entities as se
ON eu.served_entity_id = se.served_entity_id
WHERE created_by = "\<user_email\>";
エンドポイント上のUnity AI Gateway機能を更新する
Unity AI Gateway 機能は、以前に有効になっていたモデルビング エンドポイントと有効になっていなかったエンドポイントで更新できます。 Unity AI Gatewayの設定更新には約20~40秒かかりますが、レート制限の更新には最大60秒かかる場合があります。
以下に、Serving UI を使用してモデルサービング エンドポイントの Unity AI Gateway 機能を更新する方法を示します。
エンドポイントページの 「ゲートウェイ」 セクションでは、どの機能が有効になっているかを確認できます。これらの機能を更新するには、 「Unity AI Gateway を編集」を クリックしてください。

ノートブックの例
以下のノートブックでは、Databricks Unity AI Gatewayの機能をプログラムによって有効化し、プロバイダーからのモデルを管理および統制する方法を示します。PUT /api/2.0/serving-endpoints/{name}/AI-gatewayを参照してください REST APIの詳細については、こちらをご覧ください。