Unity AIゲートウェイのエンドポイントを構成します。
備考
ベータ版
この機能はベータ版です。アカウント管理者は、アカウント コンソールの [プレビュー] ページからこの機能へのアクセスを制御できます。 Databricksのプレビューを管理するを参照してください。
このページでは、Unity AI Gateway エンドポイントを構成する方法について説明します。
要件
- お客様のアカウントでUnity AI Gatewayのプレビュー版が有効になりました。Databricksのプレビューを管理するを参照してください。
- Unity AI GatewayでサポートされているリージョンにあるDatabricksワークスペース。
- ワークスペースでUnity Catalog有効化されていること。 Unity Catalog のワークスペースを有効にする方法をご覧ください。
- エンドポイントの管理者操作には、そのエンドポイントで
CAN MANAGEが必要です。「アクセス制御リスト」を参照してください。 - 作成時に、作成者には新しいエンドポイントに対して
CAN MANAGEが付与されます。 - ガードレールまたはスループット制限の回避を防ぐため、エンドポイントの作成と
CAN MANAGEは管理者に制限し、他のユーザーには承認済みエンドポイントでのクエリ権限のみを付与してください。
Unity AI Gatewayエンドポイントを作成
Unity AI Gateway エンドポイントを作成するには:
- サイドバーで、**AI Gateway**をクリックします。
- Unity AI Gateway Endpoint を作成 をクリックします。
- エンドポイント名とプライマリモデルを構成します。
- 作成 をクリックします。
エンドポイントの機能を構成します。
Unity AI Gateway エンドポイントを更新して、機能を有効または無効にできます。Unity AI Gateway の構成への更新は、有効になるまでに最大1分かかります。
既存のエンドポイントで Unity AI Gateway の機能を更新するには:
- AI Gateway ページからエンドポイントをクリックしてください。
- 「Gateway Endpoint Details」サイドバーで、更新する機能の横にある編集アイコンをクリックします。
- 変更を行い、「 保存 」をクリックします。
次の表は、利用可能なUnity AIゲートウェイの機能と、それらの構成方法をまとめたものです。
機能 | 設定方法 | 詳細 |
|---|---|---|
デフォルトで有効です。 |
| |
リクエストとレスポンスをログに記録するには、 推論テーブルを有効にする を選択します。 |
| |
レート制限 を選択して、1分あたりのクエリー数(QPM)または1分あたりのトークン数(TPM)を構成します。 |
| |
ガードレール | コンテンツポリシーを構成するには、**ガードレール**を選択します。 |
|
フォールバック | **フォールバックモデルの追加** を選択して、フォールバックモデルを構成します。 |
|
トラフィック分割 | 「**トラフィック分割の追加**」を選択して、複数のモデルバックエンドにリクエストを分散させます。 |
|
カスタム APIs | 外部APIに接続するエンドポイントを作成する際には、**Custom API** を選択します。 |
|
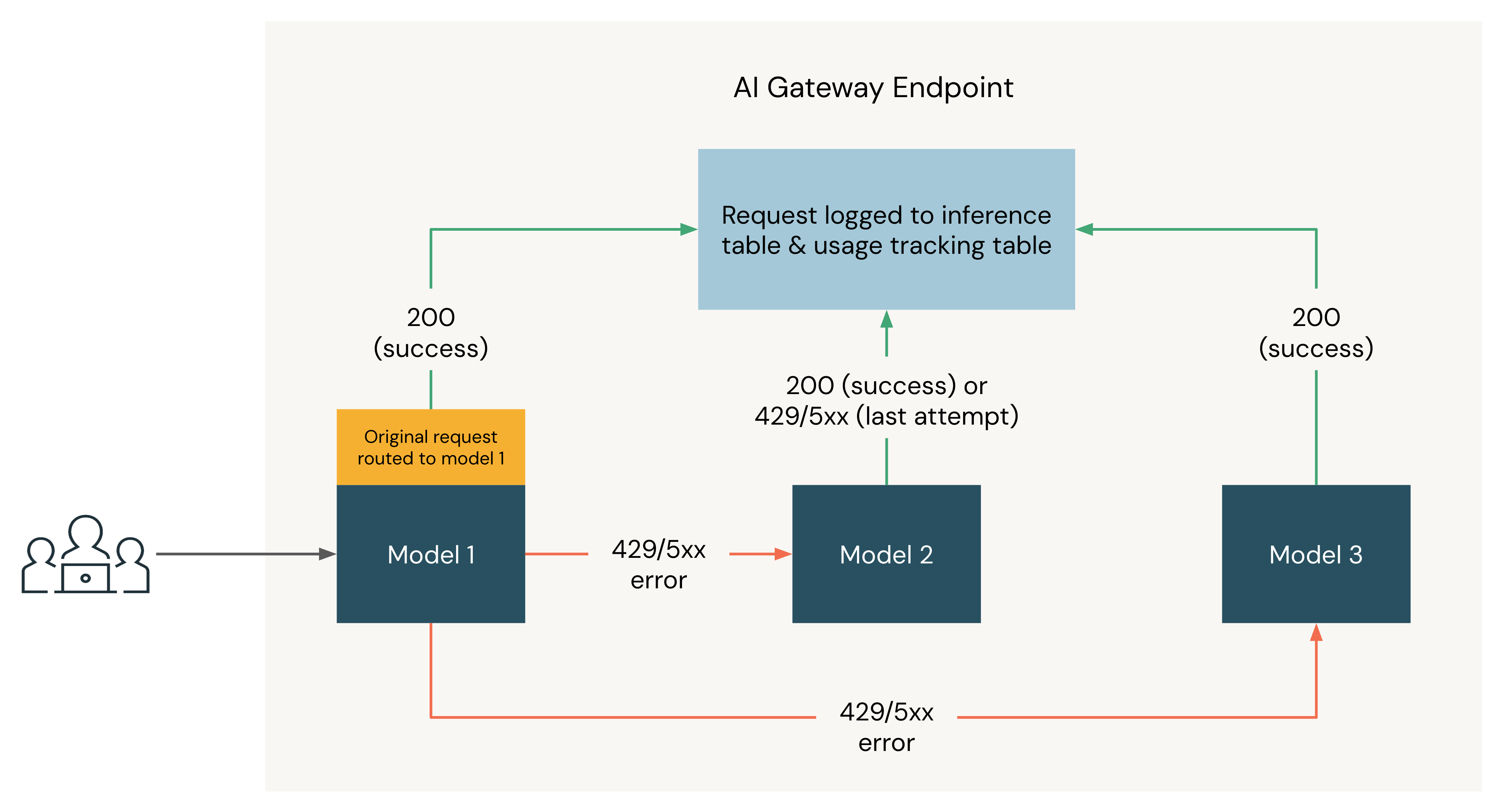
次の図は、3つのモデルがUnity AI Gatewayエンドポイントの宛先として登録されているフォールバックの例を示しています:
- リクエストは最初にModel 1にルーティングされます。
- リクエストが200レスポンスを返した場合、リクエストはモデル1で成功し、リクエストとそのレスポンスは使用状況追跡テーブルと推論テーブルに記録されます。
- リクエストがモデル1で
429または5XXエラーを返した場合、リクエストはエンドポイントの次のモデルであるモデル2にフォールバックします。 - リクエストがモデル2で
429または5XXエラーを返した場合、リクエストはエンドポイント上の次のモデルであるモデル3にフォールバックします。 - リクエストがモデル3で
429または5XXエラーを返す場合、すべてのフォールバックモデルが試行されているため、リクエストは失敗します。失敗したリクエストとレスポンスエラーは、使用状況追跡および推論テーブルに記録されます。