コンピュート 構成 リファレンス
この記事の構成は、単純な形式のコンピュート UI を使用していることを前提としています。 簡易フォームの更新の概要については、「 簡易フォームを使用してコンピュートを管理する」を参照してください。
この記事では、新しい 汎用 リソースまたはジョブ コンピュート リソースを作成するときに使用できる構成設定について説明します。 ほとんどのユーザーは、割り当てられたポリシーを使用してコンピュート リソースを作成するため、構成可能な設定が制限されます。 UI に特定の設定が表示されない場合は、選択したポリシーでその設定を構成できないためです。
ワークロードのコンピュート構成に関する推奨事項については、「クラシック コンピュート構成のベストプラクティス」を参照してください。
この記事で説明する構成と管理ツールは、汎用 とジョブ コンピュートの両方に適用されます。 ジョブ コンピュートの構成に関する考慮事項の詳細については、「 ジョブのコンピュートを構成する」を参照してください。
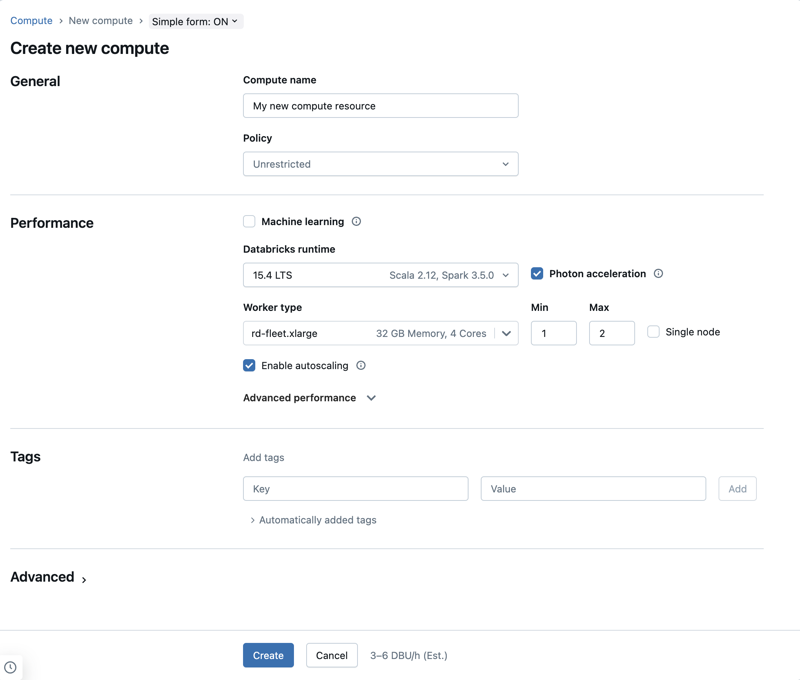
新しい汎用コンピュート リソースを作成する
新しい汎用コンピュートリソースを作成するには、次の手順を実行します。
- ワークスペースのサイドバーで、 [コンピュート] をクリックします。
- [コンピュートを作成] ボタンをクリックします。
- コンピュートリソースを構成します。
- 作成 をクリックします。
新しいコンピュートリソースは自動的にスピンアップを開始し、すぐに使用できるようになります。
コンピュート ポリシー
ポリシーは、ユーザーがコンピュート リソースを作成するときに使用できる構成オプションを制限するために使用される一連のルールです。 ユーザーが Unrestricted クラスター作成 資格を持っていない場合、付与されたポリシーを使用してのみコンピュート リソースを作成できます。
ポリシーに従ってコンピュートリソースを作成するには、[ ポリシー ] ドロップダウンメニューから目的のポリシーを選択します。
デフォルトでは、すべてのユーザーが パーソナルコンピュート ポリシーにアクセスでき、単一マシンのコンピュートリソースを作成できます。パーソナルコンピュートまたはその他のポリシーへのアクセスが必要な場合は、ワークスペース管理者にお問い合わせください。
パフォーマンス設定
次の設定は、シンプルフォームのコンピュートUIの パフォーマンス セクションに表示されます。
Databricks Runtime のバージョン
Databricks Runtime は、コンピュートで実行されるコアコンポーネントのセットです。 Databricks Runtimeバージョン ドロップダウンメニューを使用してランタイムを選択します。特定の Databricks Runtime バージョンの詳細については、 Databricks Runtime リリースノートのバージョンと互換性をご覧ください。 すべてのバージョンに Apache Spark が含まれています。 Databricks では、次のことを推奨しています。
- 汎用コンピュートの場合は、コードとプリロードされたパッケージ間の最新の互換性を確保するために、最新の最適化と、最新バージョンを使用してください。
- 運用ワークロードを実行しているジョブ コンピュートの場合は、Long Term Support (LTS) Databricks Runtime バージョンの使用を検討してください。 LTSバージョンを使用すると、互換性の問題に遭遇することがなくなり、アップグレード前にワークロードを徹底的にテストできます。
- データサイエンスと機械学習のユースケースでは、Databricks Runtime MLバージョンを検討してください。
Photonアクセラレーションを使用する
Photonは、Databricks Runtime 9.1 LTS以降を実行しているコンピューティングで使用できます。
Photon アクセラレーションを有効または無効にするには、 Photonのアクセラレーション チェックボックスを選択します。 Photonの詳細については、 Photonとはを参照してください。
ワーカーノードタイプ
コンピュート リソースは、1 つのドライバー ノードと 0 個以上のワーカー ノードで構成されます。 ドライバーノードとワーカーノードに別々のクラウドプロバイダーインスタンスタイプを選択できますが、デフォルトでは、ドライバーノードはワーカーノードと同じインスタンスタイプを使用します。 ドライバー ノードの設定は、[ 高度なパフォーマンス ] セクションの下にあります。
インスタンスタイプのファミリーが異なれば、メモリ集約型またはコンピュート集約型のワークロードなど、さまざまなユースケースに適合します。 ワーカーノードまたはドライバーノードとして使用するプールを選択することもできます。
プリエンプティブル VM インスタンスをドライバーの種類として持つプールは使用しないでください。 オンデマンド ドライバーの種類を選択して、ドライバーが再利用されないようにします。 「プールへの接続」を参照してください。
マルチノードのコンピュートでは、コンピュートリソースが正しく機能するために必要な Spark エグゼキューターやその他のサービスをワーカーノードは実行します。Spark を使用してワークロードを分散すると、すべての分散処理がワーカーノードで行われます。Databricks では、ワーカーノードごとに 1 つのエグゼキューターを実行します。そのため、エグゼキューターとワーカーという用語は、Databricks アーキテクチャのコンテキストでは同じ意味で使用されます。
Spark ジョブを実行するには、少なくとも 1 つのワーカーノードが必要です。コンピュートリソースのワーカーがゼロの場合、ドライバーノードで Spark 以外のコマンドは実行できますが、Spark コマンドは失敗します。
柔軟なノードタイプ
ワークスペースでフレキシブル ノード タイプが有効になっている場合は、コンピュート リソースにフレキシブル ノード タイプを使用できます。 柔軟なノード タイプを使用すると、指定したインスタンス タイプが使用できない場合に、コンピュート リソースを代替の互換性のあるインスタンス タイプにフォールバックできます。 この動作により、コンピュート起動中の容量障害が減少し、コンピュート起動の信頼性が向上します。 「柔軟なノード タイプを使用したコンピュート起動の信頼性の向上」を参照してください。
ワーカー ノードの IP アドレス
Databricks は、それぞれ 2 つのプライベート IP アドレスを持つワーカー ノードを起動します。ノードのプライマリ プライベート IP アドレスは、Databricks 内部トラフィックをホストします。セカンダリ プライベート IP アドレスは、 Spark コンテナーによってクラスター内通信に使用されます。 このモデルにより、 Databricks は同じワークスペース内の複数のコンピュート リソース間で分離を提供できます。
デフォルトのプロビジョニング済みワーカー・ノード・ストレージ
Databricks 、さまざまな目的でディスクの使用状況とパフォーマンスを分離するために、各コンピュート インスタンスに複数のディスクを接続します。 Google Cloud コンソールでは、ノードごとに複数のディスクが表示される場合があります。 単一ノードのコンピュートの場合、ドライバーとエグゼキューターは同じインスタンス上で実行されるため、すべてのディスクは引き続きその単一ノードに対してプロビジョニングされます。
Databricksプロビジョニングは、コンピュート インスタンスごとに次のストレージを実行します。
- ホスト オペレーティング システムと Databricks 内部サービスによって使用されるブート ディスク。デフォルトのサイズは 30 GB です。
- Spark コンテナによって使用される 150 GB のコンテナ ルート ボリューム。これは、Spark ランタイム環境、サービス、およびログをホストします。
- Spark シャッフル ファイルとキャッシュ データを保存するために使用されるローカル SSD。各ローカル SSD は 375 GB です。
- ストレージオートスケールが有効な場合のリモートSSD 。 これらは作成時に 80 GB (ローカルSSDが存在する場合は 0 GB) から始まり、必要に応じてオートスケールします。
GPU インスタンスタイプ
ディープラーニングに関連するタスクのように、高いパフォーマンスが求められる計算難易度の高いタスクの場合、 Databricks はグラフィックス プロセッシング ユニット (GPU) で高速化されるコンピュート リソースをサポートしています。 詳細については、「 GPU 対応コンピュート」を参照してください。
ローカル SSD を使用したインスタンスタイプ
インスタンスタイプの最新リスト、それぞれの価格、ローカルSSDのサイズについては、GCPの料金見積もりを参照してください。
ローカル SSD を持つインスタンスタイプは、デフォルトの Google Cloud サーバー側暗号化で暗号化され、パフォーマンスを向上させるために ディスクキャッシュ が自動的に使用されます。 すべてのインスタンスタイプのキャッシュサイズは自動的に設定されるため、ディスク使用量を明示的に設定する必要はありません。
コンピュートのローカル SSD を構成する
コンピュート リソースを作成または編集するときは、 [詳細オプション] セクションを展開し、 [インスタンス] タブを選択します。 [ローカルSSD ドロップダウンが表示され、各ノードに接続するローカルSSDの数を選択できます。 ローカルSSDは、一部の第1世代および第2世代のGCPインスタンスタイプ(例:n1、n2、n2d)でのみ構成可能です。
ドロップダウンリストには、 デフォルト オプションと具体的な数値オプションが含まれています。 デフォルトでは、 選択したインスタンスタイプに対して標準数のローカルSSDが使用されます。インスタンスタイプに-lssdサフィックスが付いている場合(例えばc3-standard-8-lssd )、ローカルSSDの数は固定されており、インスタンスタイプに組み込まれています。各インスタンスタイプでサポートされているローカルSSDの数については、 GCPのドキュメントを参照してください。
シングルノードコンピュート
シングルノード チェック・ボックスを使用すると、シングルノード・コンピュート・リソースを作成できます。
シングルノードコンピュートは、少量のデータまたはシングルノードの機械学習ライブラリなどの非分散ワークロードを使用するジョブを対象としています。マルチノードコンピュートは、作業負荷が分散された大規模なジョブに使用する必要があります。
単一ノードのプロパティ
シングルノードのコンピュートリソースには次のプロパティが含まれます。
- Sparkをローカルで実行します。
- ドライバーはマスターとワーカーの両方の役割を果たし、ワーカーノードはありません。
- コンピュートリソースの論理コアごとに 1 つのエグゼキュータースレッドを生成し、ドライバー用に 1 コアを引いたものです。
- すべての
stderr、stdout、およびlog4jログ出力をドライバーログに保存します。 - マルチノード コンピュート リソースに変換することはできません。
シングルノードまたはマルチノードの選択
シングルノードとマルチノードのコンピュートのどちらを使用するかは、ユースケースに応じて決定してください。
-
大規模なデータ処理では、シングルノードのコンピュートリソースのリソースが枯渇してしまいます。このようなワークロードの場合、Databricks ではマルチノードのコンピュートの使用を推奨しています。
-
マルチノード コンピュート リソースを 0 ワーカーにスケーリングすることはできません。 代わりに single node コンピュートを使用してください。
-
GPUスケジューリングはシングルノードコンピュートでは有効になっていません。
-
シングルノードコンピュートの場合、SparkはUDT列を含むParquetファイルを読み取ることができません。次のエラーメッセージが表示されます。
ConsoleThe Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.この問題を回避するには、ネイティブのParquetリーダーを無効にします。
Pythonspark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
オートスケールの有効化
「 オートスケールを有効にする 」をチェックすると、コンピュートリソースのワーカーの最小値と最大値を指定できます。その後で、ジョブの実行に必要な適切な数のワーカーを Databricks は選択します。
コンピュートリソースがオートスケールするワーカーの最小数と最大数を設定するには、 ワーカータイプ ドロップダウンの横にある 最小 フィールドと 最大 フィールドを使用します。
オートスケールを有効にしない場合は、 ワーカー タイプ ドロップダウンの横の ワーカー フィールドに固定数のワーカーを入力する必要があります。
コンピュートリソースが実行中の場合、コンピュートの詳細ページに割り当てられたワーカーの数が表示されます。割り当てられたワーカーの数をワーカーの設定と比較し、必要に応じて調整を行うことができます。
オートスケールのメリット
オートスケールを使用すると、 Databricks はジョブの特性に応じてワーカーをアカウントに動的に再割り当てします。 パイプラインの特定の部分は、他の部分よりも計算負荷が高い場合があり、Databricks はジョブのこれらのフェーズで追加のワーカーを自動的に追加します (不要になったら削除します)。
オートスケールを使用すると、ワークロードに合わせてコンピュートをプロビジョニングする必要がないため、高い使用率を簡単に実現できます。 これは、要件が時間の経過と共に変化するワークロード (1 日の間にデータセットを探索するなど) に特に当てはまりますが、プロビジョニング要件が不明な 1 回限りの短いワークロードにも適用できます。したがって、オートスケールには2つの利点があります。
- ワークロードは、固定サイズのプロビジョニング不足のコンピュートリソースと比較して高速に実行できます。
- オートスケールを使うことで、静的にサイズ調整されたコンピュートリソースと比較して全体的なコストを削減できます。
コンピュートリソースの固定サイズとワークロードに応じて、オートスケールでは、これらの利点の一方または両方が同時に実現されます。コンピュートのサイズは、クラウドプロバイダーがインスタンスを終了するときに選択されたワーカーの最小数を下回る可能性があります。この場合、Databricks は、ワーカーの最小数を維持するために、インスタンスの再プロビジョニングを継続的に再試行します。
オートスケールはspark-submitジョブでは使用できません。
コンピュートのオートスケーリングには、Structured Streamingワークロードのクラスターサイズをスケールダウンする際の制限があります。Databricksは、ストリーミングワークロード向けに、Lakeflow上のSpark宣言型パイプラインと強化されたオートスケールを使用することをお勧めします。オートスケーリングによるLakeFlow Pipelinesクラスターの利用率の最適化を参照してください。
オートスケールの動作
オートスケールには、次の特性があります。
- まず8ノードを追加します。その後、指数関数的にスケールアップし、最大値に達するまでに必要なステップ数を踏みます。
- ノードの90%が10分間ビジー状態でなく、コンピュートも30秒以上アイドル状態である場合にスケールダウンします。
- 1 ノードから指数関数的にスケールダウンします。
Databricksオートスケールを使用するコンピュート リソースでは、 Apache Spark動的割り当て ( spark.dynamicAllocation.enabled ) を有効にしないでください。 Databricksオートスケールは、ワーカーノードとエグゼキューターのライフサイクルをプラットフォームレベルで管理します。 Spark Dynamic Allocation を並行して有効にすると、スケーリング決定の競合が発生し、エグゼキューターのチャーン、 NODES_LOSTエラー、および決して取得されないタスクが発生する可能性があります。
プールによるオートスケール
コンピュートリソースをプールに接続する場合は、次の点を考慮してください。
- 要求されたコンピュート サイズが、プール内の アイドル インスタンスの最小数 以下であることを確認してください。 それより大きい場合、コンピュートの起動時間はプールを使わないコンピュートと同等になります。
オートスケール の例
静的コンピュートリソースをオートスケールするように再構成すると、Databricks はすぐにコンピュートリソースのサイズを最小値と最大値の範囲内で変更し、オートスケールを開始します。例として、次の表は、5~10 ノードの間でオートスケールするようにコンピュートリソースを再構成した場合に、特定の初期サイズのコンピュートリソースに何が起こるかを示しています。
初期サイズ | 再構成後のサイズ |
|---|---|
6 | 6 |
12 | 10 |
3 | 5 |
パフォーマンスの詳細設定
次の設定は、単純な形式のコンピュートUIの[ 高度なパフォーマンス ]セクションの下に表示されます。
プリエンプティブル インスタンス
プリエンプティブル VM インスタンスは、通常のインスタンスよりもはるかに低価格で作成および実行できるインスタンスです。ただし、Google Cloud は、他のタスクのためにこれらのリソースにアクセスする必要がある場合、これらのインスタンスを停止(プリエンプト)することがあります。 プリエンプティブルインスタンスは Google コンピュートエンジンの容量を余分に使用するため、可用性は使用状況によって異なります。
新しいコンピュートリソースを作成する場合、以下の2つの異なる方法でプリエンプティブルVMインスタンスを有効にすることができます。
- UI を使用してコンピュートを作成する場合は、 高度なパフォーマンス の プリエンプティブル インスタンスを使用 チェックボックスをオンにします。
- UIを使用してインスタンスプールを作成する場合は、[ オンデマンド/プリエンプティブル ] を [ すべてのプリエンプティブル ]、[ プリエンプティブル(フォールバックGCP) ]、または [ オンデマンドGCP ] に設定します。プリエンプティブルVMインスタンスが利用できない場合、コンピュートはデフォルトのフォールバックとしてオンデマンドVMインスタンスを使用するようになっています。フォールバック動作を構成するには、
gcp_attributes.gcp_availabilityをPREEMPTIBLE_GCPまたはPREEMPTIBLE_WITH_FALLBACK_GCPに設定します。デフォルトはON_DEMAND_GCPです。
{
"instance_pool_name": "Preemptible w/o fallback API test",
"node_type_id": "n1-highmem-4",
"gcp_attributes": {
"availability": "PREEMPTIBLE_GCP"
}
}
次に、新しいコンピュートリソースを作成し、 プール をプリエンプティブルインスタンスプールに設定します。
自動終了
コンピュート作成フォームの**パフォーマンス**セクションで、コンピュートの自動終了を設定できます。コンピュートの作成時に、コンピュート リソースを終了する非アクティブ期間を分単位で指定します。
コンピュート リソースで現在時刻と最後に実行されたコマンドの差が、指定した非アクティブ期間よりも大きい場合、 Databricks はそのコンピュート リソースを自動的に終了します。 コンピュートの終了の詳細については、「 コンピュートの終了」を参照してください。
ドライバーの種類
高度なパフォーマンス セクションでドライバーの種類を選択できます。ドライバー ノードは、コンピュート リソースに接続されているすべてのノートブックの状態情報を保持します。 ドライバー ノードは、SparkContext も保持し、コンピュート リソース上のノートブックまたはライブラリから実行するすべてのコマンドを解釈し、Apache Spark Sparkエグゼキューターと調整する マスターを実行します。
ドライバーノードタイプのデフォルト値は、ワーカーノードタイプと同じです。Sparkワーカーから大量のデータをcollect()により収集してノートブックで分析する場合は、より多くのメモリを備えたより大きなドライバーノードの種類を選択できます。
ドライバーノードは、アタッチされているノートブックのすべての状態情報を保持するため、未使用のノートブックは必ずドライバーノードからデタッチしてください。
タグ
タグを使用すると、組織内のさまざまなグループによって使用されるクラウドリソースのコストを簡単に監視できます。コンピュートを作成するときにキーと値のペアとしてタグを指定すると、 Databricks これらのタグを GCE クラスタリング上の Databricks Runtime ポッドと永続ボリューム、および DBU 使用ログに適用します。
アカウントコンソールのDatabricks課金利用グラフでは、タグごとに利用状況を集計できます。同じページからダウンロードした課金利用 CSV レポートには、デフォルトタグとカスタムタグも含まれています。 タグは GKE ラベルと GCE ラベルにも伝播します。
プールとコンピュートのタグタイプがどのように連携するかについての詳細な情報については、「タグを使用して使用状況を属性付けおよび追跡する」を参照してください
コンピュートリソースにタグを追加する方法は次のとおりです。
- [ タグ ] セクションで、各カスタムタグのキーと値のペアを追加します。
- [ 追加 ] をクリックします。
詳細設定
次の設定は、シンプル フォーム コンピュート UI の Advanced セクションの下に表示されます。
アクセスモード
アクセス モードは、コンピュート リソースを使用できるユーザーと、コンピュート リソースを使用してアクセスできるデータを決定するセキュリティ機能です。 Databricks内のすべてのコンピュート リソースにはアクセス モードがあります。アクセスモードの設定は、シンプルフォームのコンピュートUIの Advanced セクションにあります。
アクセスモードの選択はデフォルトで 自動 です。これは、選択した Databricks Runtime に基づいてアクセスモードが自動的に選択されることを意味します。機械学習ランタイム、GPUインスタンスタイプ、またはバージョンが14.3より低いDatabricks Runtimeが選択されていない限り、自動でデフォルトは**Standard**になります。選択されている場合は**Dedicated**が使用されます。
Databricks では、必要な機能がサポートされていない限り、標準アクセス モードを使用することをお勧めします。
アクセスモード | 説明 | 対応言語 |
|---|---|---|
Standard | ユーザー間でデータを分離することにより、複数のユーザーが使用できます。 | Python、SQL、Scala |
専用 | 1 人のユーザーまたはグループに割り当てて使用できます。 | Python、SQL、Scala、R |
これらの各アクセス モードの機能サポートの詳細については、「 標準コンピュートの要件と制限 」および 「専用コンピュートの要件と制限」を参照してください。
Databricks Runtime 13.3 LTS以降では、initスクリプトとライブラリはすべてのアクセスモードでサポートされています。要件とサポートのレベルは異なります。 initスクリプトはどこでインストールできますか? および コンピュートスコープのライブラリを参照してください。
Google サービス アカウント
Google Identity を使用してこのコンピュート リソースを Google サービス アカウントに関連付けるには、[ 詳細設定 ]、[ Google サービス アカウント ] の順にクリックし、[ Google サービス アカウント ] フィールドに Google サービス アカウントの Eメール アドレスを追加します。 この値は、 GCS データソースと BigQuery データソースでの認証に使用されます。
GCSおよびBigQueryデータソースへのアクセスに使用するサービスアカウントは、Databricksアカウントの設定時に指定したサービスアカウントと同じプロジェクトである必要があります。
可用性ゾーン
コンピュート設定ページの [Advanced > Instances ] で、コンピュート リソースの可用性ゾーンを選択します。 この設定では、コンピュート リソースで使用する可用性ゾーンを指定できます。 デフォルトでは、アベイラビリティーゾーンの設定は [自動 ] に設定されています。 [自動 ] に設定すると、1 つの可用性ゾーンが自動的に選択されます。
特定のゾーンを選択することもできます。特定のゾーンを選択することは、主に組織が特定のアベイラビリティーゾーンのリザーブドインスタンスを購入している場合に便利です。
高可用性ゾーン
可用性ゾーンとしてHAを選択することもできます。高可用性(HA)は、長時間にわたって一貫したレベルのアップタイムを提供するように設計されたシステム機能です。HAゾーン構成を使用すると、ゾーンが利用不可になったり、ゾーン内のインスタンス容量を取得できないなど、単一ゾーンの可用性の問題が発生する可能性が減ります。
可用性ゾーンとしてHAが選択されると、Databricksはリージョン内のゾーン間でインスタンスの配置を分散します。これにより、ゾーン間のエグレス料金による価格上昇につながる可能性があります。
オートスケール ローカル ストレージを有効にする
Google Cloudのコンピュートインスタンスは、ゾーンのソリッドステート永続ディスクを使用して、ワーカーレベルの追加ストレージで補完することができます。
オートスケール ローカル ストレージを使用すると、 Databricks はコンピュートの Spark ワーカーの空きディスク容量を監視します。 ワーカーがディスク上で実行を開始する場所が少なすぎる場合、 Databricks は、ディスク領域から実行する前に、ゾーン SSD PD のサイズを自動的に変更します。 Zonal-SSD PDボリュームは、インスタンスあたり合計ディスク容量(インスタンスのローカルストレージを含む)の制限までアタッチされます。
ローカルストレージのオートスケールを有効にする を構成するには、 Advanced セクションを開き、 インスタンス タブをクリックします。
ローカルディスクの暗号化
ローカル SSD を持つインスタンスタイプは、デフォルトの Google Cloud サーバー側の暗号化で暗号化されます。 「 ローカル SSD のインスタンスタイプ」を参照してください。
Spark の構成
Sparkジョブを微調整するために、カスタムSpark構成プロパティを指定できます。
標準アクセスモードでは、Databricks Runtime 19以降、特定のSpark構成プロパティが制限されます。制限されたプロパティを設定するクラスターを作成または編集すると、エラーが発生して失敗します。Spark構成の制限を参照してください。
-
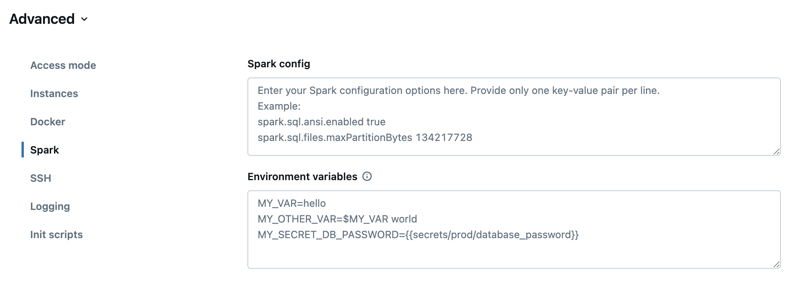
コンピュートの設定ページで、[ 詳細設定 ] トグルをクリックします。
-
[ Spark ] タブをクリックします。
-
Spark構成 では、1行に1つのキーと値のペアとして設定プロパティを入力します。
Cluster APIを使用してコンピュートを設定する場合は、Create cluster APIまたはUpdate Cluster APIでspark_confフィールドでSparkプロパティを設定します。
コンピュートで Spark 構成を適用するために、ワークスペース管理者は コンピュート ポリシーを使用できます。
シークレットから Spark 構成プロパティを取得する
Databricks では、パスワードなどの機密情報をプレーンテキストではなく シークレット に格納することをお勧めします。 Spark 構成でシークレットを参照するには、次の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
たとえば、passwordというSpark構成プロパティをsecrets/acme_app/passwordに保存されているシークレットの値に設定するには、次のようにします。
spark.password {{secrets/acme-app/password}}
詳細については、「 シークレットの管理」を参照してください。
コンピュート ログのデリバリー
汎用またはジョブ コンピュートを作成する場合、 Sparkドライバー、ワーカー ノード、およびイベントからのログを含むクラスター ログの場所を指定できます。 ログは5分ごとに配信され、1時間ごとに指定された場所にアーカイブされます。Databricks 、コンピュート リソースが終了するまでログの配信を続けます。
ログは以下のいずれかの場所に保存できます。
-
ボリューム(推奨):ログをUnity Catalogボリュームパスに保存します。 これは、Unity カタログ対応のコンピュート リソースを使用する場合に推奨される最も安全なオプションです。
-
DBFS(レガシー):ログをDatabricksファイルシステム(DBFS)パスに保存します。このオプションは、ワークスペースのDBFSルートとマウントが無効になっていない場合にのみ利用可能です。DBFSルートへのアクセスを無効にし、既存のDatabricksワークスペースにマウントする」を参照してください。
ログの配信場所を設定するには、以下の手順に従ってください。
- [コンピュート] ページで、[ 詳細設定 ] トグルをクリックします。
- [ ロギング ] タブをクリックします。
- 宛先タイプを選択します。
- ログパス を入力します。
ログを保存するために、 Databricks は選択したログ パスに、コンピュートのcluster_idにちなんで名付けられたサブフォルダを作成します。
たとえば、指定したログパスが /Volumes/catalog/schema/volumeの場合、 06308418893214 のログは
/Volumes/catalog/schema/volume/06308418893214。
ボリュームへのログの配信は、Unity Catalog が有効になっているコンピュートで、 標準 アクセス モードまたは 専用 アクセス モードがユーザーに割り当てられた場合にのみサポートされます。 グループに割り当てられた 専用 アクセスモードではサポートされていません。パスとしてボリュームを選択した場合は、コンピュートの所有者またはそれに割り当てられたユーザーが、そのボリュームに対してREAD VOLUMEおよびWRITE VOLUME権限を持っていることを確認してください。 Unity Catalogボリュームの権限」を参照してください。
環境変数
コンピュート リソース上で実行されている initスクリプト からアクセスできるカスタム環境変数を設定します。 Databricks には、initスクリプトで使用できる定義済みの 環境変数 も用意されています。 これらの事前定義された環境変数を上書きすることはできません。
-
コンピュート構成ページで、 「詳細」 をクリックします。
-
[ Spark ] タブをクリックします。
-
[ 環境変数 ] フィールドで環境変数を設定します。

ENV は予約語であり、環境変数の名前として使用することはできません。
Create cluster APIまたはUpdate cluster APIのspark_env_varsフィールドを使用して環境変数を設定することもできます。