Databricks はどのようにしてユーザーの分離を強制しますか?
このページでは、 Databricks が Lakeguard を使用して、共有コンピュート環境でユーザー分離を強制し、専用コンピュートできめ細かなアクセス制御を適用する方法について説明します。
Lakeguardとは?
Lakeguard は、コード分離とデータ フィルタリングを強制するDatabricks上の一連のテクノロジであり、複数のユーザーが同じコンピュート リソースを安全かつコスト効率よく共有し、特権マシン アクセスを提供するコンピュート上で設定されたきめ細かいアクセス制御でデータにアクセスできるようにします。
Lakeguard はどのように機能しますか?
標準クラシックコンピュート、Serverlessコンピュート、SQL Warehouseなどの共有コンピュート環境では、LakeguardはユーザーコードをSparkエンジンや他のユーザーから分離します。この設計により、多数のユーザーが同じコンピュートリソースを共有しながら、ユーザー、Spark ドライバー、およびエグゼキューターの間で厳密な境界を維持できます。この分離が確立されているため、標準コンピュートでは、行フィルターや列マスクなどのきめ細かなアクセス制御をネイティブに適用できます。
専用コンピュートはクラシックなSparkアーキテクチャを使用しており、ユーザーコードがエンジンから分離されていないため、オーバーフェッチのリスクなしにきめ細やかなアクセス制御を適用することはできません。代わりに、専用コンピュートはデータフィルタリングをワークスペースのServerlessコンピュートに委任します。これはLakeguardで分離されており、データフィルタリングを代行します。これが、専用コンピュートにおけるきめ細かなアクセス制御には、ワークスペースでServerlessコンピュートを有効にする必要がある理由です。専用コンピュートにおけるきめ細かなアクセス制御を参照してください。
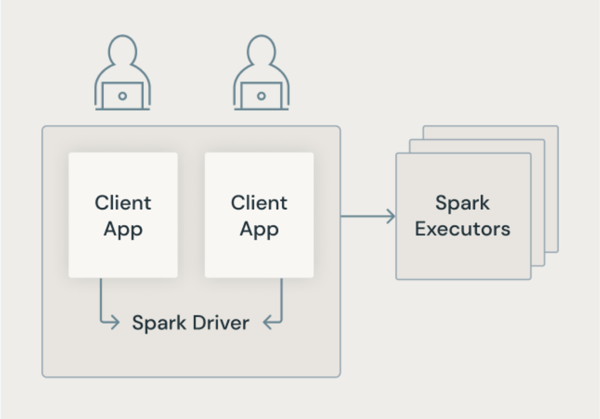
クラシック Spark アーキテクチャ
次の図は、従来の Spark アーキテクチャで、ユーザーアプリケーションが基盤となるマシンへの特権アクセスを持つ JVM を共有する方法を示しています。
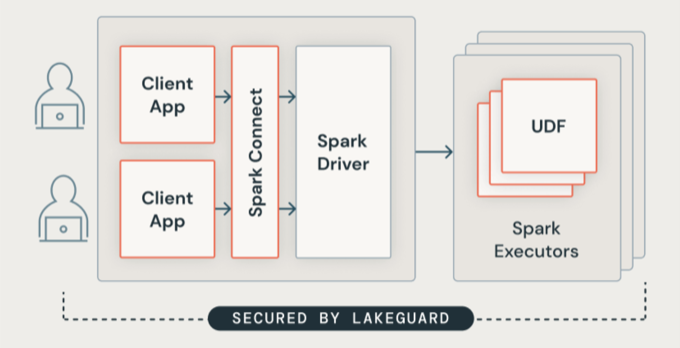
Lakeguard アーキテクチャ
Lakeguard は、セキュリティで保護されたコンテナーを使用してすべてのユーザー コードを分離します。これにより、複数のワークロードを同じコンピュート リソースで実行しながら、ユーザー間の厳密な分離を維持します。
Spark クライアントの分離
Lakeguard は、次の 2 つの主要なコンポーネントを使用して、クライアント アプリケーションを Spark ドライバーから分離し、クライアント アプリケーションを相互に分離します。
- Spark Connect : Lakeguard は、Spark Connect (Apache Spark 3.4 で導入) を使用して、クライアント アプリケーションをドライバーから切り離します。クライアントアプリケーションとドライバーは、同じJVMまたはクラスパスを共有しなくなりました。この分離により、不正なデータアクセスが防止されます。また、この設計により、クエリに行レベルまたは列レベルのフィルターが含まれている場合に、オーバーフェッチによって生じるデータにユーザーがアクセスできないようにします。
Spark Connect は分析と名前解決を実行時まで延期するため、コードの動作が変わる可能性があります。「Spark Connect と Spark Classic の比較」を参照してください。
- コンテナサンドボックス: 各クライアントアプリケーションは、独自の分離されたコンテナ環境で実行されます。これにより、ユーザーコードが他のユーザーのデータや基になるマシンにアクセスできなくなります。サンドボックスでは、コンテナベースの分離技術を使用して、ユーザー間の安全な境界を作成します。
UDF 分離
デフォルトでは、 Spark エグゼキューター UDF を分離しません。 この分離の欠如により、UDF はファイルを書き込んだり、基盤となるマシンにアクセスしたりする可能性があります。
Lakeguard は、次の方法で UDF を含むユーザー定義コードを Spark エグゼキューター で分離します。
- サンドボックス エグゼキューター上の実行環境 Spark .
- エグレスネットワークトラフィックをUDFから分離して、不正な外部アクセスを防止します。
- クライアント環境を UDF サンドボックスにレプリケートして、ユーザーが必要なライブラリにアクセスできるようにします。
この分離は、標準コンピュートの UDF と、サーバレス コンピュートと SQLウェアハウスのPython UDF に適用されます。