カスタム計算とは何ですか?
カスタム計算を使用すると、データセット クエリを変更せずに動的なメトリクスと変換を定義できます。 このページでは、AI/BI ダッシュボードでカスタム計算を使用する方法について説明します。
カスタム計算を使用する理由は何ですか?
カスタム計算を使用すると、ソース SQL を変更せずに、既存のダッシュボード データセットから新しいフィールドを作成して視覚化できます。データセットごとに最大 200 個のカスタム計算を定義できます。
カスタム計算は次のいずれかの種類になります。
- 計算メジャー : 合計売上や平均コストなどの集計値。計算されたメジャーでは、
AGGREGATE OVERコマンドを使用して、時間範囲全体の値をコンピュートできます。 - 計算ディメンション : 年齢範囲の分類や文字列の書式設定などの集計されていない値または変換。
カスタム計算はメトリクス ビューと同様に動作しますが、カスタム計算が定義されているデータセットとダッシュボードに範囲が限定されます。 他のデータ資産で使用できるカスタム メトリクスを定義するには、 Unity Catalogメトリクス ビュー」を参照してください。
計算されたメジャーを使用して動的なメトリクスを作成する
次のデータセットがあるとします。
項目 | リージョン | 料金 | コスト | Date |
|---|---|---|---|---|
リンゴ | USA | 30 | 15 | 2024年1月1日 |
リンゴ | Canada | 20 | 10 | 2024年1月1日 |
オレンジ | USA | 20 | 15 | 2024年1月2日 |
オレンジ | Canada | 15 | 10 | 2024年1月2日 |
地域別に利益率を視覚化したいと考えています。カスタム計算を使用しない場合は、 margin列を含む新しいデータセットを作成する必要があります。
リージョン | マージン |
|---|---|
USA | 0.40 |
Canada | 0.43 |
このアプローチは機能しますが、新しいデータセットは静的であり、1 つの視覚化しかサポートしない場合があります。 元のデータセットに適用されたフィルターは、追加の手動調整を行わない限り、新しいデータセットに影響を与えません。
カスタム計算では、次の数式を使用して利益率を集計として表すことができます。
(SUM(Price) - SUM(Cost)) / SUM(Price)
この測定は動的です。視覚化で使用すると、視覚化のグループ化を反映して自動的に更新されます。たとえば、上記と同じメジャーを使用して、視覚化で選択した内容に応じて、利益率をRegionまたはItemで視覚化できます。
計算ディメンションを使用して集計されていない値を定義する
計算ディメンションを使用すると、ソースデータセットを変更せずに、集計を行わない値や軽量の変換処理を定義できます。これは、視覚化のためにデータを整理または再フォーマットする場合に便利です。
たとえば、個々の年齢ではなく年齢グループ別に年齢の傾向を分析するには、次の式を使用してカスタムage_groupディメンションを定義できます。
CASE
WHEN age < 18 THEN '<18'
WHEN age >= 18 AND age < 25 THEN '18–24'
WHEN age >= 25 AND age < 35 THEN '25–34'
WHEN age >= 35 AND age < 45 THEN '35–44'
WHEN age >= 45 AND age < 55 THEN '45–54'
WHEN age >= 55 AND age < 65 THEN '55–64'
WHEN age >= 65 THEN '65+'
END
ウィンドウ上での計算を定義する
ダッシュボードの視覚化における一般的なタスクは、過去 7 日間の売上のローリング合計など、範囲にわたる集計をコンピュートすることです。 カスタム計算はウィンドウ関数を通じてこの機能をサポートし、現在の行に関連する行セット (「ウィンドウ」) にわたって計算を実行できます。
AI/BI ダッシュボードは、次の 2 種類のウィンドウ関数をサポートしています。
- 固定されたグループを集計し、スカラー関数として動作するスカラー ウィンドウ関数。単独で使用した場合、計算されたディメンションが形成されます。
- 動的なグループを集計し、集計関数として動作する集計ウィンドウ関数。使用すると、計算された測定値が形成されます。
ウィンドウ関数は、視覚化のグループ化とは独立して集計の粒度を制御できる詳細レベル式の基礎でもあります。
スカラーウィンドウ関数
スカラー ウィンドウ関数は、視覚化のグループ化が行われる前に、オプションのPARTITION BYとORDER BY句を持つOVER演算子を使用して、関連する行全体の集計を実行します。 これらは、ウィンドウ関数自体で定義された静的なパーティション セットを集計してから、変換されていない基礎テーブルにディメンションとして結合されます。
地域別の総売上を計算する例:
SUM(sales) OVER (PARTITION BY Region)
地域ごとの累計売上を計算する例:
SUM(sales) OVER (PARTITION BY Region ORDER BY Date RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
OVER構文
<AGGREGATE_FUNCTION>(<column>) OVER (
[PARTITION BY <dimensions>]
[ORDER BY <column>]
[ROWS|RANGE frame_specification]
)
詳細については、SQL 言語リファレンスのウィンドウ関数を参照してください。
集計ウィンドウ関数
集計ウィンドウ関数は、視覚化グループ化が適用された後に、 AGGREGATE OVER演算子を使用してウィンドウ化された集計をコンピュートします。 集計するグループは、式が使用されている視覚化から自動的に継承されます。オプションで、 PARTITION BY句を*と共に使用して、継承されたすべてのパーティションを表し、 EXCEPT句を使用して特定のディメンションを除外することができます。ORDER BY句を使用すると、結果のパーティションを隣接する行にわたって部分的に集計し、「ウィンドウ」機能を提供できます。
前の例と同じデータセットを使用し、次の式は、 AGGREGATE OVER演算子を使用して後続 7 日間の平均利益率を計算します。
(
(SUM(Price) - SUM(Cost)) / SUM(Price)
) AGGREGATE OVER (
ORDER BY Date TRAILING 7 DAY
)
作成後、このメジャーはあらゆる視覚化に適用できます。
AGGREGATE OVER構文
<AGGREGATE_EXPRESSION> AGGREGATE OVER (
[PARTITION BY * [EXCEPT (<field> [, ...])]]
[ORDER BY <field> <frame_specification>]
)
この構文では、
PARTITION BY *視覚化グループから継承されたすべてのパーティションを表しますEXCEPT (<field> [, ...])パーティション セットから除外するディメンションを指定しますPARTITION BY句とORDER BY句はどちらもオプションですが、空のAGGREGATE OVER ()は無効です。
フレームの仕様は次のいずれかになります。
CURRENTCUMULATIVEALL(TRAILING|LEADING) <number> <unit><number>正の整数<unit>DAY、MONTH、またはYEAR- 例:
TRAILING 7 DAYまたはLEADING 1 MONTH
次の表は、aggregate over のフレーム仕様と同等のSQL ウィンドウ フレーム句との比較を示しています。
フレーム仕様 | 同等のSQLウィンドウフレーム句 |
|---|---|
|
|
|
|
|
|
|
|
|
|
視覚化でORDER BYフィールドがグループ化されていない場合、 AGGREGATE OVER最後の行の集計値を各グループに表示する値として取得します。これは、「最後の」半加法動作と同等です。
OVER対 AGGREGATE OVER
OVERとAGGREGATE OVERの主な違いは、 OVERがスカラー関数であり、 AGGREGATE OVERが集計関数である点です。OVERではグループを定義するためにPARTITION BY句が必要ですが、 AGGREGATE OVER周囲のビジュアリゼーションからそのグループを継承し、現在のグループの外部のデータを組み込むことができます。
次の場合にはOVER構文を使用します:
- テーブルなどの集計されていないコンテキストで使用する必要があるウィンドウ計算。
- すべての視覚化のグループ化とフィルターを無視する必要があるウィンドウ計算。
- 固定された詳細レベルでの集計:
PARTITION BYを使用して特定の粒度で集計を計算します。 ROW_NUMBER、RANK、LAGなどのランキング関数と分析関数を使用します。
次の場合にはAGGREGATE OVER構文を使用します:
- さまざまなグループ化のコンテキストで使用される可能性があり、現在のグループ外のデータを組み込む必要があるウィンドウ計算。
- 視覚化フィルターを尊重するウィンドウ計算。
- 視覚化よりも粗い詳細レベルで集計しています:
PARTITION BY * EXCEPT (...)を使用してディメンションを除外しています。 - 行の欠落に対して堅牢な時間ベースの範囲:
TRAILINGまたはLEADINGを使用した移動ウィンドウ。
パフォーマンス上の利点
カスタム計算はパフォーマンスのために最適化されています。小さなデータセット (≤100,000 行および ≤100 MB) の場合、計算はブラウザで実行されるため、応答速度が向上します。より大きなデータセットはSQLウェアハウスによって処理されます。 詳細については、データセットの最適化とキャッシュを参照してください。
カスタム計算を作成する
この例では、 samples.nyctaxi.tripsデータセットに基づいて計算メジャーを作成します。AI/BI ダッシュボードの操作方法に関する一般的な知識を前提としています。AI/BI ダッシュボードの作成に慣れていない場合は、 「ダッシュボードの作成」を参照して開始してください。
-
既存のデータセットを開くか、新しいデータセットを作成します。
-
+ カスタム計算を追加 を クリックします。
-
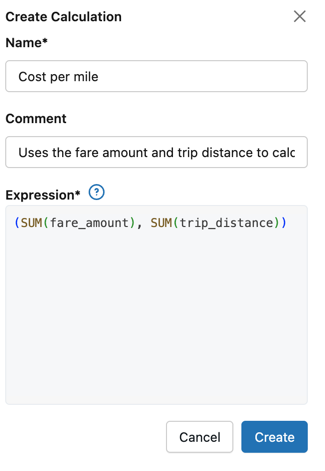
画面の右側に「 計算の作成 」パネルが開きます。 名前 テキストフィールドに Cost per mile と入力します。
-
(オプション) [ コメント ] テキスト フィールドに、「運賃額と旅行距離を使用して 1 マイルあたりのコストを計算します。」と入力します。
-
式 フィールドに、次のように入力します。
SQLtry_divide(SUM(fare_amount), SUM(trip_distance)) -
作成 をクリックします。
他の計算を参照する
カスタム計算では、同じデータセットで定義された他のカスタム計算を参照できます。これにより、より単純な計算を構成して複雑なメトリクスを構築し、再利用性と保守性を高めることができます。
別のカスタム計算を参照する場合は、データセット内の列であるかのように、式でその名前を直接使用します。
たとえば、次のような計算メジャーを作成したとします。
- 総収益 :
SUM(sale_amount) - 合計費用 :
SUM(cost_amount)
両方を参照する 3 番目の計算メジャーを作成できます。
- 利益率 :
(MEASURE(total_revenue) - MEASURE(total_cost)) / MEASURE(total_revenue)
- 同じデータセット内の計算のみを参照できます。
- 循環参照は許可されていません (計算 B が計算 A を参照している場合、計算 A は計算 B を参照できません)。
- 参照される計算は、他の式で使用する前に作成する必要があります。
カスタム計算をメトリクス ビューに追加する
プレビュー
この機能は パブリック プレビュー段階です。
メトリクス ビューによって作成されたデータセットに基づいてカスタム計算を定義できます。 データセットを開くと、 結果テーブル と スキーマ のみが表示されます。新しいカスタム計算を定義するには、 「カスタム計算」を クリックします。他のデータ資産が使用できる追加のカスタム メトリクスを定義するには、ビュー定義を変更します。 Unity Catalogメトリクス ビュー」を参照してください。
ダッシュボード データセット エディターから新しいメトリクス ビューを定義するには、 「メトリクス ビューとしてエクスポート」を参照してください。
スキーマを表示する
結果パネルの スキーマ タブをクリックして、カスタム計算とそれに関連するコメントを表示します。
計算されたメジャーは メジャー セクションに一覧表示され、 ![]() fx でマークされます。計算メジャーに関連付けられた値は、ビジュアライゼーションで
fx でマークされます。計算メジャーに関連付けられた値は、ビジュアライゼーションで GROUP BY を設定するときに動的に計算されます。結果テーブルに値は表示されません。計算されたディメンションは、 ディメンション セクションに表示されます。

視覚化でカスタム計算を使用する
以前に作成した 1 マイルあたりのコスト の計算メジャーを視覚化で使用できます。
計算されたメジャーは、チャートに設定されたディメンションに対して自動的に集計されます。この動作は、メトリクス ビューでのディメンションとメジャーの動作と同じで、集計は視覚化で定義したグループ化に動的に適応します。
- キャンバス をクリックします。次に、新しい視覚化ウィジェットをキャンバスに配置します。
- 視覚化構成パネルを使用して、次のように設定を編集します。
-
データセット: Taxicab data
-
視覚化: 棒
-
X軸:
- フィールド: dropoff_zip
- スケールタイプ: Categorical
- 変換: None
-
Y軸:
- 1マイルあたりのコスト
-
テーブルのビジュアライゼーションは、計算ディメンションをサポートしますが、計算メジャーはサポートしません。
次の画像はチャートを示しています。
カスタム計算を使用した視覚化は、フィルターが適用されると自動的に更新されます。たとえば、 pickup_zip フィルターを追加すると、視覚化が更新され、選択した値に一致するデータのみが表示されます。
カスタム計算を編集する
計算を編集するには:
- [データ] タブをクリックし、編集する計算に関連付けられたデータセットをクリックします。
- 結果パネルの スキーマ タブをクリックします。
- メジャー と ディメンションは、 データセット フィールドのリストの下に表示されます。クリック
 編集したい計算の右側にあるケバブ メニューをクリックします。次に、 「編集」を クリックします。
編集したい計算の右側にあるケバブ メニューをクリックします。次に、 「編集」を クリックします。 - カスタム計算の編集 パネルで、編集するテキスト フィールドを更新します。次に、[ 更新 ] をクリックします。
カスタム計算を削除する
計算を削除するには:
- [データ] タブをクリックし、編集するメジャーに関連付けられているデータセットをクリックします。
- 結果パネルの スキーマ タブをクリックします。
- フィールドのリストの下に メジャー セクションが表示されます。クリック編集したい計算の右側にあるケバブ メニュー。次に、 「削除」 をクリックします。
- 表示される 削除 ダイアログで 削除 をクリックします。
制限事項
カスタム計算を使用するには、次の条件を満たす必要があります。
- 式で使用される列は同じデータセットに属している必要があります。
- 外部テーブルまたはデータソースを参照する式はサポートされていないため、失敗するか、予期しない結果が返される可能性があります。
サポートされている機能
カスタム計算でサポートされているすべての関数の完全なリファレンスについては、 「カスタム計算関数リファレンス」を参照してください。サポートされていない関数を使用しようとすると、エラーが発生します。
例
次の例は、カスタム計算の一般的な使用方法を示しています。各カスタム計算は、データ タブのデータセットのスキーマに表示されます。キャンバスでは、カスタム計算をフィールドとして選択できます。
条件に応じてデータをフィルタリングして集計する
条件付きでデータを集計するには、 CASEステートメントを使用します。次の例では、 samples.nyctaxi.tripsデータセットを使用して、郵便番号 10103 で始まるすべての乗車の運賃の合計を計算します。
SUM(CASE
WHEN pickup_zip=10103 THEN fare_amount
WHEN pickup_zip!=10103 THEN 0
END)
文字列を構築する
CONCAT関数を使用して新しい文字列値を構築します。concat関数とconcat_ws関数を参照してください。
CONCAT(first_name, ' ', last_name)
日付のフォーマット
視覚化に表示される日付文字列をフォーマットするには、 DATE_FORMATを使用します。
DATE_FORMAT(tpep_pickup_datetime, 'YYYY-MM-dd')