Fan-in and fan-out architecture in LakeFlow Pipelines
ファンインおよびファンアウトは、スケーラブルで信頼性の高いデータパイプラインを構築するための一般的なパターンです。このページでは、両方について説明し、それらをLakeFlow Pipelinesで実装する方法を示します。
ファンインとファンアウトとは何ですか?
ファンインは、 複数のソースからのデータが単一のパイプライン内で取り込まれ、処理されるアーキテクチャ パターンです。
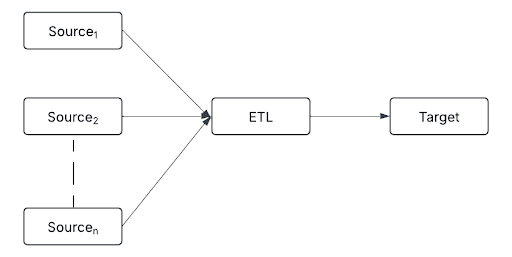
ソースには以下が含まれます:
- リアルタイム イベント ストリーム (Kafka や Kinesis など)
- クラウド ストレージ (S3、ADLS、Google Cloud Storage など)
- リレーショナル データベース (例: PostgreSQL、MySQL、Snowflake)
- IoTデバイス(センサー、ログ、 APIsなど)
ファンインは、多様なデータ ストリームを単一の処理層に統合することにより、データが下流に移動する前に一貫した変換、重複排除、データ エンリッチメントを可能にします。
ファンアウトは 1 対多のアプローチに従い、単一の処理済みデータ ストリームを複数の宛先にルーティングします。
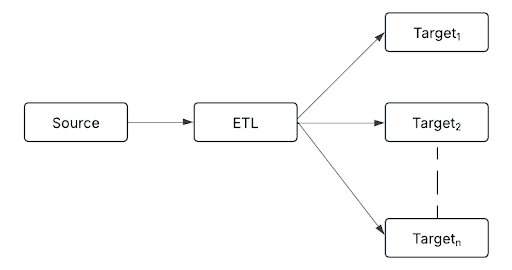
目的地には以下が含まれます。
- 構造化ストレージのDeltaテーブル
- 異常検出のためのリアルタイムアラートシステム
- 予測分析のための機械学習モデル
- レポートと分析のためのデータウェアハウス
- 非同期通信と分離処理のためのメッセージキュー
このパターンにより、各ダウンストリーム システムが必要な形式でデータを受信することが保証され、組織はストリーミング データをさまざまなビジネス アプリケーションに統合できるようになります。
実際には、パイプラインでは両方のパターンが組み合わされることが多いです。例えば:
- 企業は、複数のアプリケーション、Web サイト、モバイル デバイスからユーザー アクティビティ データを収集します (ファンイン)。
- 処理されたデータは履歴分析のために Delta Lake に保存され、異常なアクティビティ (ファンアウト) に対してはリアルタイム アラートがトリガーされます。
追加フローでファンインを実装する
ファンイン パイプラインは、複数のデータ ストリームを 1 つのターゲットにマージします。従来、これには複雑なユニオンクエリと手動のチェックポイント設定が必要でした。Append フローは、明示的なユニオンや複雑なロジックを使用せずに、さまざまなデータ ストリームを単一のストリーミング テーブルに直接フィードできるようにすることでこれを簡素化します。 各ソースは独立して管理され、増分データの取り込みと更新が可能です。
たとえば、追加フローを使用して、複数の Kafka トピックまたはリージョン データ ストリームを 1 つの統合ターゲット テーブルに統合します。
- Python
- SQL
from pyspark import pipelines as dp
dp.create_streaming_table("all_topics")
# Kafka stream from topic1
@dp.append_flow(target="all_topics")
def topic1():
return spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,...") \
.option("subscribe", "topic1") \
.load()
# Kafka stream from topic2
@dp.append_flow(target="all_topics")
def topic2():
return spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,...") \
.option("subscribe", "topic2") \
.load()
CREATE OR REFRESH STREAMING TABLE all_topics;
CREATE FLOW
topic1
AS INSERT INTO
all_topics BY NAME
SELECT * FROM
read_kafka(bootstrapServers => 'host1:port1,...', subscribe => 'topic1');
CREATE FLOW
topic2
AS INSERT INTO
all_topics BY NAME
SELECT * FROM
read_kafka(bootstrapServers => 'host1:port1,...', subscribe => 'topic2');
ファンアウトを実装する
ファンアウトパイプラインは、1つのソースから複数の出力へデータを分散します。LakeFlow Pipelinesは、ユースケースに応じて3つのアプローチをサポートします。
一般化されたロジックにはforループを使用する
ETL ロジックが複数のターゲット間で同一である場合は、Python の for ループを使用して、パラメーター化されたループを通じて複数のテーブルを動的に生成します。これにより、繰り返しのコーディングが回避され、構成によるパイプラインのスケーリングが簡素化されます。
生成された各フローまたはテーブルは、ソースデータセット全体を独立して処理します。Kafkaなどの、共有スループットまたは読み取り容量の制限があるソースでは、パフォーマンスに著しい影響を及ぼす可能性があります。このようなソースに対しては、そのアプローチを利用する前に、慎重に評価してください。
regions = ["US", "EU", "APAC"]
for region in regions:
@dp.materialized_view(name=f"orders_{region.lower()}_filtered")
def filtered_orders(region_filter=region):
return spark.read.table("combined_orders").filter(f"region = '{region_filter}'")
ターゲット固有のロジックには独立したフローを使用する
ETL 変換がターゲットごとに大きく異なる場合は、独立したデータ フローを実装します。このアプローチは、各ユースケースに合わせて正確な制御と最適化されたパフォーマンスを実現します。
from pyspark import pipelines as dp
# Grouped output
@dp.materialized_view(name="orders_sink")
def region_orders():
df = spark.read.table("combined_orders").groupBy("region").count()
# Add additional logic here
return df
# BI materialized view
@dp.materialized_view(name="orders_bi_materialized")
def orders_bi():
return spark.read.table("combined_orders").select("order_id", "amount", "region")
# ML feature table
@dp.materialized_view(name="orders_ml_features")
def orders_ml():
return (
spark.read.table("combined_orders")
.withColumn("high_value_order", col("amount") > 1000)
.select("order_id", "high_value_order", "region")
)
カスタムルーティングにはForEachBatchを使用する
パブリックプレビュー
foreach_batch_sink LakeFlow Pipelinesプレビューチャンネルを介してパブリックプレビューで提供されています。パイプラインの構成でchannelを参照してください。
foreach_batch_sink は、各マイクロバッチにカスタムロジックを適用することで、複雑な変換、結合、ルーティングを可能にし、組み込みのストリーミングサポートを持たないJDBCシンクなど、複数の宛先に対応します。
各バッチは複数の書き込み操作を独立して実行します。1 つの操作が失敗しても、以前に成功した書き込みは自動的にロールバックされません。これにより、特に Kafka などの共有ソースを処理するときに、ターゲット間でデータが不完全または不整合になる可能性があります。慎重なエラー処理と徹底的なテストを実施してパイプラインを設計します。「パイプライン内の任意のデータ シンクに書き込むには ForEachBatch を使用する」を参照してください。
from pyspark import pipelines as dp
@dp.foreach_batch_sink(name="user_events_feb")
def user_events_handler(batch_df, batch_id):
# Write to Delta table
batch_df.write.format("delta").mode("append").saveAsTable("my_catalog.my_schema.my_delta_table")
# Write to JSON files
batch_df.write.format("json").mode("append").save("/Volumes/path/to/json_target")
@dp.append_flow(target="user_events_feb", name="user_events_flow")
def read_user_events():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/data/incoming/events")
)
一般的なForEachBatchパターン
foreach_batch_sinkは複数のパターンをサポートします。一般的なパターンには次のようなものがあります:
-
単一フローから複数の宛先シンクへ : 単一の
append_flowストリーミング ソースから読み取り、データをforeach_batch_sinkにルーティングします。シンクは、複数の宛先 (Delta、JSON、外部システムなど) への書き込みを処理します。これは、共有変換ロジックを備えた単純なマルチ出力ユースケースに最適です。 -
統合されたシンクへの複数のフロー :複数の
append_flowソース(例えば、異なるディレクトリ、フォーマット、Kafkaトピック、または外部APIs)が単一のforeach_batch_sinkに統合されます。これにより、共通の変換ロジック、出力管理、およびエラー処理が一元化されます。単一のチェックポイントを維持するだけでよいため、このアプローチは調整の複雑さを大幅に軽減します。Kafkaなどのメッセージキューや外部APIsを処理する際に特に便利です。 -
1 つのフローから 1 つのシンクへ (多数の独立したペア) : 各
append_flowには専用のforeach_batch_sinkがあり、単一のソースとそのターゲットの間に明確で分離された関係を確立します。これは、独自の処理ロジック、簡素化されたトラブルシューティング、および分離されたエラー処理を必要とする、多数の独立したストリームを持つパイプラインに最適です。
実際には、これらのアプローチは互いに補完し合うことがよくあります。たとえば、大規模なファンイン シナリオではループを使用して複数の追加フローを動的に生成し、ファンアウトの場合はループまたはforeach_batch_sinkを使用して結果を配布します。
ベストプラクティス
- アペンドフローでは、処理エラーを防ぐために、ソーススキーマがターゲットストリーミングテーブルと一致している必要があります。LakeFlow Pipelinesのスキーマの期待値を使用して、例外を事前に検出および処理し、パイプライン全体でのスキーマの一貫性を確保します。
- for ループのロジックを明確に定義し、わかりやすく保ちます。
- 読みやすさを維持するために、各フローとテーブルに明確な名前を付けます。
- リソース使用率を監視して効率的に拡張し、パフォーマンスのボトルネックを回避します。
- メッセージ キューに書き込む場合は、すべての入力ストリームを統合する単一の
append_flowで 1 つのforeach_batch_sinkを使用します。これにより、ダウンストリームの状態とチェックポイントの管理が簡素化されます。
制限事項
- The Lakeflow pipelines リネージUIは、新しい追加フローソースのメトリクスとフローレベルのメタデータを表示しない場合があります。
- for ループで使用する値のリストは、削減するのではなく、展開してください。以前に定義されたデータセットが後続のパイプライン実行で省略されると、ターゲットスキーマから自動的に削除され、意図しないデータ損失が発生します。