チェンジデータキャプチャとスナップショット
データエンジニアは、Databricks の上流にあるリレーショナル データベース (Oracle、Postgres、SQL Server) などのソースから、アナリティクス、レポート作成、機械学習に利用するために、データを Databricks にレプリケートする必要があることがよくあります。運用システムが変更されるにつれて、分析テーブルはその変更に合わせて同期した状態を維持する必要があります。
一部のチームは、レポート作成とアナリティクスを行うために、運用データベースの現在の状態を反映する必要があります。他のユーザーは、監査、規制要件、または顧客アナリティクスのために、変更の完全な履歴を保持する必要があります。
チェンジデータキャプチャ(CDC)は、データベースを完全な静的データベースとしてではなく、変化のセットとして扱います。以下の図は、従業員データを含むソーステーブルの行が更新されると、変更点のみを含む新しい行のセットがCDCフィード内に生成されることを示しています。CDCフィードの各行には、通常、UPDATEなどの操作、および順不同の更新を処理できるようにCDCフィード内の各行を確定的に順序付けるために使用できる列を含む、追加のメタデータが含まれています。例えば、次の図のsequenceNum列は、CDCフィードにおける行の順序を決定します。
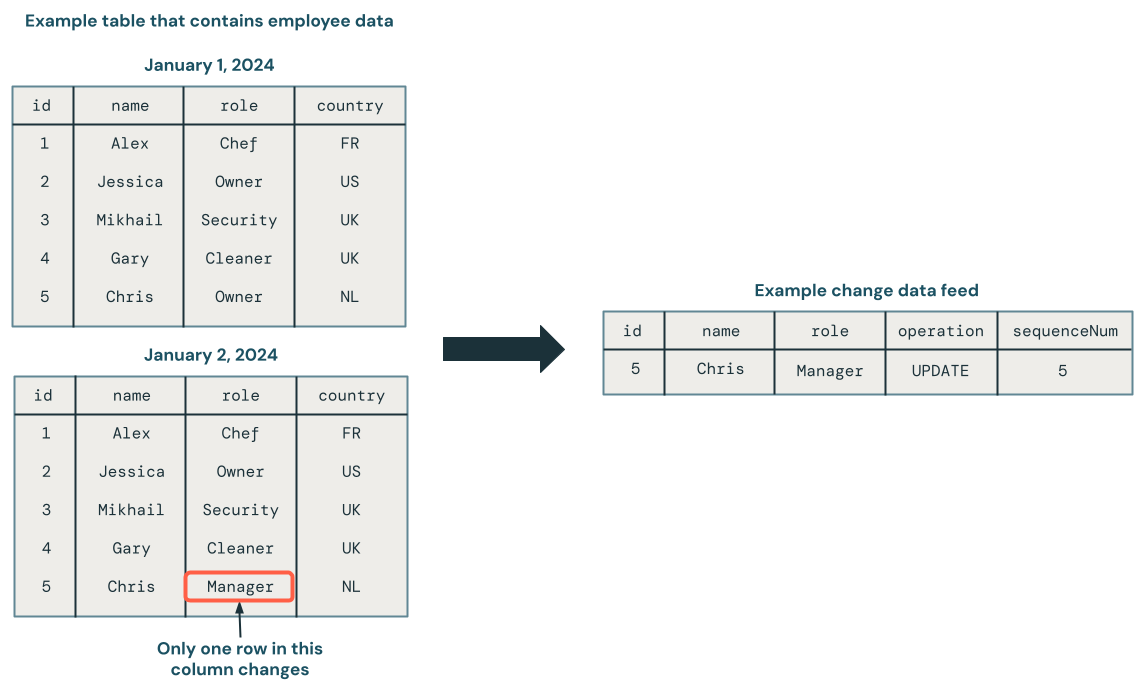
CDCにより、ダウンストリームシステムでデータベースを更新する際に、よりシンプルなトランザクションのためにデータの変更点のみを確認できます。要件である場合は、データベースの履歴を表示することもできます。
課題は、ソースシステムが異なるデータ形式でデータを提供するという点です。一部は、個々の変更(挿入、更新、削除)をキャプチャする変更フィードを出力します。他には、テーブル全体の定期的なスナップショットのみを提供しています。フォーマットごとに、下流のテーブルを正確かつ最新に保つには、異なる処理方法が必要です。
従来、チームは、チェンジフィードから、あるいはスナップショットを比較することによって、これらの変更を適用するためにカスタムMERGE INTOロジックに依存してきました。このアプローチは複雑でエラーが発生しやすく、パイプラインの進化に合わせて推論や維持が困難になる、ステージングテーブル、ウィンドウ関数、シーケンスの前提条件が必要となります。
CDC の利点
チェンジデータキャプチャは、ワークロードでいくつかのメリットを提供します。
- 変更データは通常、完全なデータセットよりも小さく、変更はデータの増分更新として下流クエリによって処理できます。
- 変更データは、特定の時点でのレコードを再構築できる方法で保存でき、監査、特定時点でのレポート、または傾向分析のための完全な履歴を提供します。
- 変更データにより、時間の経過とともに安定したサロゲートキーが可能になります。
変更の適用方法: 現在の状態または変更履歴全体
緩やかに変化するディメンション(SCD)は、アップストリームの変更がアナリティクス テーブルに取り込まれた後にどのように適用され、モデル化されるかを定義します。組織はデータニーズに応じて異なるアプローチを使用する場合があります。SCDタイプ1は、データセットの現在の状態のみを保存できます。SCDタイプ2は、データセットに対する変更の完全な履歴を保存します。このセクションでは、これらについてより詳細に説明します。
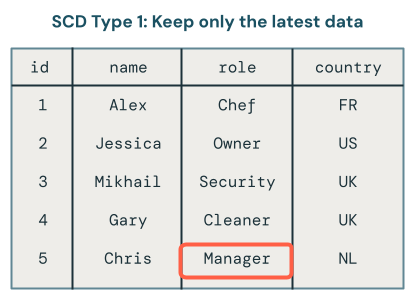
SCD タイプ 1:現在の状態のみ
SCDタイプ1は、変更があるたびに古いデータを新しいデータで上書きし、各レコードの最新バージョンのみを保持します。履歴は保持されません。
SCDタイプ1を使用する場合:
- データの現在の状態のみで十分です。
- 下流のマテリアライズドビューは、完全に再計算されるのではなく、増分更新されることが望ましいです。
- 結合には安定した代理キーが必要です。
SCD1では、データの最新バージョンのみが利用可能です。これは、最終テーブルのみを保存するものと捉えることができる、分かりやすいアプローチです。レコードがOwnerからManager,に変更された場合、テーブルにはManagerのみが残ります。
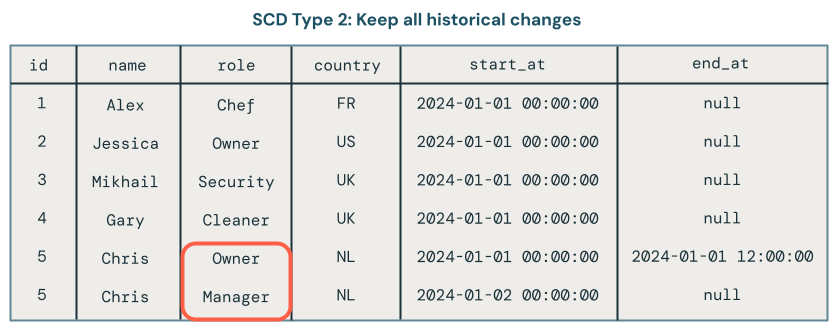
SCDタイプ2:履歴追跡
SCD Type 2は、時間の経過とともに複数のバージョンのデータを作成し、それぞれにメタデータ付きのタイムスタンプを付与することで、完全な履歴記録を保持します。__START_AT列と__END_AT列は、レコードの各バージョンの有効期間を定義します。アクティブなレコードは__END_AT = NULLです。データセットの状態を、任意の時点において確認できます。
SCDタイプ2を使用する場合:
- 監査性または規制要件により、履歴追跡が求められます。
- 顧客アナリティクスには、エンティティが時間とともにどのように進化してきたかを理解する必要があります。
- ビジネスロジックでは、特定の時点におけるレポート作成が求められる。
- トレンドを分析したり、過去の状態を比較したりする必要があります。
SCDタイプ2処理は、データの変更履歴を保持します。例えば、レコードのロールフィールドが現在 Manager に設定されている場合、ロールが以前 Owner に設定されていたことも確認できます。次の図では、Chrisのレコードにまさにそのことが発生しています。現在のレコードは、end_at フィールドに null 値があるため、識別できます。
チェンジデータキャプチャ(CDC)フィードとは
チェンジデータキャプチャ(CDC)は、ソースシステム内のデータに加えられた変更(挿入、更新、削除)をキャプチャするデータ統合パターンです。データセット全体を処理するのではなく、CDCは、変更されたレコードのみを含むフィードを生成します。
たとえば、Oracleに50行の従業員テーブルがあり、1人の従業員のジョブタイトルが変更された場合、CDCフィードには、その従業員の単一のUPDATEレコードが含まれます。これにより Databricks は、実行ごとにソーステーブル全体を読み取るのではなく、変更されたレコードのみを処理できます。
ソースデータベースからの各CDCレコードには、以下の情報が含まれています。
- 操作タイプ(
INSERT、UPDATE、DELETE) - レコードのデータ値です
- 確定的順序付けのための順序番号またはタイムスタンプ
シーケンス番号により、遅延または順不同の到着が正しく適用されることが保証されます。SQL Server、MySQL、Oracleなどのトランザクションデータベースは、標準でCDCフィードを生成します。Deltaテーブルは、チェンジデータフィード(CDF)として知られる独自のCDCフィードも生成するため、Deltaソースからの変更も簡単に処理できます。
スナップショットとは何ですか?
スナップショットは、特定の時点におけるテーブルの完全な状態を表します。変更のみをキャプチャするCDCフィードとは異なり、スナップショットにはソーステーブルのすべての行が含まれます。
チームが運用データベースでCDCフィードを必ずしも有効にしない理由はいくつかあります。
- コスト(CDCは本番運用データベースへの負荷を増大させる可能性があります)
- ソースデータベースにおける性能に関する懸念
- CDCをサポートしないレガシーシステム
- 組織的な制約(取り込みを管理するチームがアップストリームデータベースを所有していないため)
変更フィードが利用できない場合、スナップショットベースの取り込みが唯一の選択肢となります。スナップショットは以下の情報源から取得できます。
- リレーショナルデータベース(Oracle、Postgres、SQL Server)からの定期的なエクスポート
- アップストリームシステムからのクラウドストレージファイルダンプ
- Deltaテーブル(各テーブルバージョンは実質的にスナップショットです)
- 上位テナントからのオープン共有
スナップショットはレコードレベルの変更をキャプチャしないため、何が変更されたかを特定するには、挿入、更新、削除を推測するためにスナップショット間でレコードを比較する必要があります。
自動的にCDCフィードを処理する
Databricksは、Lakeflow pipelines内の AUTO CDC APIを通じてCDC処理を簡素化します。このAPIは、ソースデータベースまたはチェンジデータフィードが有効なDeltaテーブル上のCDCフィードからの変更を処理するように設計されています。
SQL および Python のコード例については、「AUTO CDC の例」を参照してください。
次のいずれかの条件が当てはまる場合は、AUTO CDC を使用します。
- ソースシステムがチェンジデータフィード (CDF) を生成します。
- チェンジデータフィードが有効になっているDelta テーブルから読み取りを行っています。
- リレーショナルデータベースからのCDCフィードがあります(DebeziumやOracle GoldenGateなどのツールを介して)。
AUTO CDC シーケンシング列によって定義された順序でイベントを処理することで、順序がずれたレコードを自動的に処理します。シーケンス列は、正しいイベント順序を単調増加的に表すものであり、各シーケンス値のキーごとに個別の更新が 1 つ必要です。NULL シーケンス値はサポートされていません。SCD タイプ 2 の場合、パイプラインはシーケンス値をターゲットテーブルの __START_AT および __END_AT 列に伝播します。
初期ハイドレーション: 既存の運用データベーステーブルをDatabricksにレプリケートする場合、継続的な変更を処理する前にすべてのヒストリカルデータをロードする必要があります。AUTO CDC は、利用可能なすべてのデータを一度処理してから停止するモードである ワンタイムフロー を通じて、これをサポートしています。初期ロードの完了後、継続的なCDC処理のために、トリガーモードまたは連続モードフローを使用してください。これにより、バルクロードとインクリメンタルロードの両方で一貫したロジックが確保されます。
自動的にスナップショットを処理
CDCフィードが利用できない場合、Databricks は AUTO CDC FROM SNAPSHOT API を提供します。このAPIはスナップショットベースの取り込み用に設計されており、 連続するスナップショット を比較し、合成変更フィードを生成し、ターゲットテーブルにSCDタイプ1またはタイプ2のロジックを適用します。ターゲットテーブルは、ダウンストリームクエリ向けに、SCDタイプ1またはタイプ2のCDCフィード(Deltaテーブルでは「チェンジデータフィード」(CDF)と呼ばれます)を提供できます。
Pythonのコード例については、AUTO CDC FROM SNAPSHOT の例を参照してください。
AUTO CDC FROM SNAPSHOT Python パイプラインインターフェースでのみサポートされています。スナップショットはバージョンごとに昇順で処理される必要があります;順不同のスナップショットが検出された場合、無視されます。AUTO CDC FROM SNAPSHOTデータセットの出力をクエリするマテリアライズドビューなどのダウンストリーム処理は、増分化できる機能や安定した代理キーなど、CDCのメリットを享受できます。
AUTO CDC FROM SNAPSHOT 初期負荷のためだけのものではありません。これは、スナップショットが唯一利用可能なフォーマットである場合に、継続的な処理を行うために設計されています。新しいスナップショットが到着するたびに、APIはそれを以前のスナップショットと比較して変更点と変更データフィードを導き出します。
AUTO CDC FROM SNAPSHOTを使用する場合:
- CDC はソースデータベースで有効になっていません。
- 定期的なスナップショット(完全なテーブルダンプ)にのみアクセスできます。
- 増分処理におけるCDCのメリットを享受したい場合、または変更の完全な履歴を保持したい場合にご利用いただけます。
AUTO CDC FROM SNAPSHOT 以下の項目を自動的に処理します。
- 連続するスナップショットを比較して、挿入、更新、削除された記録を特定します。
- スナップショット間の違いに基づいて、合成変更フィードを生成します。
AUTO CDCと同じSCDロジックを適用して、SCDタイプ1またはタイプ2をコンピュートします。
AUTO CDC FROM SNAPSHOT あるスナップショットから次のスナップショットまでの変更のみを認識し、中間変更は取得しません。たとえば、毎日スナップショットを取得し、ユーザーが1日に2回住所を変更した場合(AからB、その後BからCへ)、それらの時点のスナップショットしか受信しなかったため、変更フィードはAからCに直接移動する可能性があります。
スナップショット処理パターン
AUTO CDC FROM SNAPSHOT スナップショットバージョンを決定するための 2 つのパターンに対応しています。
パイプライン取り込み時間によるスナップショット処理
スナップショットはパイプライン実行時に読み込まれ、取り込み時刻がスナップショットのバージョンとして使用されます。パイプラインが更新されるたびに、新しいスナップショットが取り込まれます。パイプラインが連続モードで実行される場合、フローのトリガー間隔設定に基づいて複数のスナップショットが取り込まれます。
スナップショットが定期的に順番に届き、パイプラインの実行タイムスタンプをバージョン管理に利用できる場合は、このパターンを使用してください。
バージョン関数を用いたスナップショット処理
パイプラインの実行時に、処理するスナップショットバージョンを指定する関数を使用します。関数はタプルを返します:(DataFrame, version_number)。API は、バージョン番号で定義された順にスナップショットを処理します。順不同のスナップショットが検出されると、スナップショットは無視されます。
このパターンは次の場合に使用します:
- 複数のスナップショットが同時に到着できますが、順次処理が必要です。
- スナップショットは順不同で到着する場合があります。
- スナップショットの順序を明示的に制御する必要があります。
追加の CDC 機能
「AUTO CDC ターゲットに対する変更操作」
標準的なストリーミングテーブルとは異なり、AUTO CDCのターゲットであるUnity Catalogのテーブルは、パイプラインの実行中であってもINSERT、UPDATE、DELETE、およびMERGEステートメントをサポートしています。詳細と制限については、ターゲットストリーミングテーブルのデータの追加、変更、または削除を参照してください。
AUTO CDC ターゲットからのチェンジデータフィードの読み取り
AUTO CDC ターゲットストリーミングテーブルは独自のチェンジデータフィード(CDF)を出力できるため、ダウンストリームパイプラインはAUTO CDCの出力から変更を消費できます。詳細については、AUTO CDC ターゲットテーブルからのチェンジデータフィードの読み取りを参照してください。
メトリクスとモニタリング
AUTO CDC パイプラインの実行ごとに、num_upserted_rowsとnum_deleted_rowsのメトリクスが自動的に記録されます。詳細については、「高度な AUTO CDC トピック」を参照してください。
SCDタイプ2における一部の列の追跡
デフォルトでは、SCDタイプ2はいずれかの列の値が変更されるたびに新しいバージョンを作成します。AUTO CDC を使用すると、履歴を追跡する列を指定できるため、追跡されていない列への変更は、新しい履歴レコードを作成するのではなく、現在のバージョンをその場で更新します。これにより、重要な属性の履歴を保持しながら、ストレージ コストとクエリの複雑さを削減できます。例については、SCDタイプ2で列のサブセットを追跡するを参照してください。
推奨事項
データの変更のみを扱いたい場合に、たとえばダウンストリームのマテリアライズドビューを増分的に更新できるようにするには、チェンジデータキャプチャ(CDC)を使用します。特定の時点での役割を知るために、データの変更履歴を保持したい場合にもCDCを使用します。
Databricksにアップストリームデータをレプリケートし、ソースの変更と同期させる必要がある場合は、AUTO CDC APIsを使用してください。適切なAPIは、ソースシステムが変更をどのように公開するかによって異なります:
AUTO CDCソースがチェンジフィードを発行する場合、** **を使用します。たとえば、CDCが有効になっているリレーショナルデータベース(DebeziumやOracle GoldenGateなどのツールを介して)、チェンジデータフィードが有効になっているDeltaテーブル、またはシーケンシング列を持つ挿入、更新、削除のストリームを生成するあらゆるソースが該当します。AUTO CDC FROM SNAPSHOTソースがCDCをサポートしておらず、定期的な完全なテーブルダンプのみを提供する場合に、** を使用してください**。このAPIは、連続するスナップショットを比較することで変更を推測し、合成変更フィードを生成します。そのため、ネイティブのCDCフィードがなくても同じSCD処理のメリットを享受できます。
いずれの場合も、各レコードの現在の状態のみが必要な場合はSCDタイプ1を、監査、特定時点のレポート、または傾向分析のために変更の完全な履歴を保持する必要がある場合はSCDタイプ2を選択します。
その他のリソース
- 「AUTO CDC APIs: パイプラインを使用してチェンジデータキャプチャを簡素化」:
AUTO CDCとAUTO CDC FROM SNAPSHOTAPIsを使用してCDCを実装する方法を学習してください。 - 高度なAUTO CDCトピック:DML操作の使用、チェンジデータフィードの読み取り、メトリクスのモニタリングなど、高度なCDCトピックについて学習します。