データプロファイリング メトリクス テーブル
このページでは、データプロファイリングによって作成されたメトリクス テーブルについて説明します。 プロファイルによって作成されたダッシュボードについては、 「データプロファイリング ダッシュボード」を参照してください。
プロファイルがDatabricksテーブルで実行されると、プロファイル メトリクス テーブルとドリフト メトリクス テーブルの 2 つのメトリクス テーブルが作成または更新されます。
- プロファイル メトリック テーブルには、各列と、時間ウィンドウ、スライス、グループ化列の各組み合わせの概要統計が含まれています。
InferenceLog分析の場合、分析テーブルにはモデル精度メトリクスも含まれます。 - ドリフト メトリクス テーブルには、メトリクスの分布の変化を追跡する統計が含まれています。 ドリフト テーブルを使用すると、特定の値ではなく、データの変更を視覚化したり、アラートを出したりできます。 次のタイプのドリフトが計算されます:
- 連続ドリフトは、ウィンドウを前の時間ウィンドウと比較します。連続ドリフトは、指定された粒度に従って集約された後に連続した時間ウィンドウが存在する場合にのみ計算されます。
- ベースライン ドリフトは、ウィンドウをベースライン テーブルによって決定されたベースライン分布と比較します。ベースライン ドリフトは、ベースライン テーブルが提供されている場合にのみ計算されます。
メトリクステーブルが配置される場所
メトリクス テーブルは{output_schema}.{table_name}_profile_metricsと{output_schema}.{table_name}_drift_metricsに保存されます。ここで:
{output_schema}output_schema_nameによって指定されたカタログとスキーマです。{table_name}プロファイリングされるテーブルの名前です。
プロファイル統計のコンピュートの仕組み
メトリクス テーブル内の各統計とメトリクスは、指定された時間間隔 (「ウィンドウ」と呼ばれます) でコンピュートされます。 Snapshot分析の場合、時間枠はメトリクスが更新された時間に対応する単一の時点です。 TimeSeriesおよびInferenceLog分析の場合、時間ウィンドウはcreate_monitorで指定された粒度と、 profile_type引数で指定されたtimestamp_colの値に基づきます。
メトリクスは常にテーブル全体に対してコンピュートされます。 さらに、スライス式を指定すると、メトリクスは式の値で定義されたデータ スライスごとにコンピュートされます。
例えば:
slicing_exprs=["col_1", "col_2 > 10"]
次のスライスを生成します: col_2 > 10に 1 つ、 col_2 <= 10に 1 つ、 col1内の一意の値ごとに 1 つ。
メトリクス テーブルでは、スライスは列名slice_keyおよびslice_valueによって識別されます。 この例では、1 つのスライス キーは「col_2 > 10」になり、対応する値は「true」と「false」になります。テーブル全体はslice_key = NULL およびslice_value = NULL と同等です。スライスは単一のスライス キーによって定義されます。
メトリクスは、タイム ウィンドウとスライスのキーと値によって定義されるすべての可能なグループをコンピュートします。 また、 InferenceLog解析ではモデル ID ごとにメトリクスがコンピュートされます。 詳細については、 「生成されたテーブルの列スキーマ」を参照してください。
モデル精度に関する追加統計( InferenceLog分析のみ)
InferenceLog分析の追加統計が計算されます。
label_colとprediction_col両方が指定されている場合、モデル品質が計算されます。- スライスは、
model_id_colの個別の値に基づいて自動的に作成されます。 - 分類モデルの場合、 Boolean値を持つスライスに対して公平性とバイアスの統計が計算されます。
クエリ分析とドリフトメトリクステーブル
メトリクス テーブルに直接クエリを実行できます。 次の例はInferenceLog分析に基づいています。
SELECT
window.start, column_name, count, num_nulls, distinct_count, frequent_items
FROM census_monitor_db.adult_census_profile_metrics
WHERE model_id = 1 — Constrain to version 1
AND slice_key IS NULL — look at aggregate metrics over the whole data
AND column_name = "income_predicted"
ORDER BY window.start
生成されたテーブルの列スキーマ
メトリクス テーブルには、プライマリ テーブルの各列ごとに、グループ化列の組み合わせごとに 1 つの行が含まれます。 各行に関連付けられた列は、列column_nameに表示されます。
モデル精度メトリクスなどの複数の列に基づくメトリクスの場合、 column_nameは:tableに設定されます。
プロファイル メトリクスでは、次のグループ化列が使用されます。
- 時間枠
- 粒度(
TimeSeriesとInferenceLog分析のみ) - ログタイプ - 入力テーブルまたはベースラインテーブル
- スライスキーと値
- モデル ID (
InferenceLog分析のみ)
ドリフト メトリクスの場合、次の追加のグループ化列が使用されます。
- 比較時間枠
- ドリフトの種類(前のウィンドウとの比較またはベースラインテーブルとの比較)
メトリクス テーブルのスキーマは以下に示されており、データプロファイリングAPIリファレンス ドキュメントにも示されています。
プロファイルメトリクステーブルのスキーマ
次の表は、プロファイル メトリクス テーブルのスキーマを示しています。 メトリクスが行に適用できない場合、対応するセルは null になります。
列名 | Type | 説明 |
|---|---|---|
列のグループ化 | ||
window | 構造。下記[1]を参照。 | 時間ウィンドウ。 |
granularity | string | ウィンドウ期間。 |
model_id_col | string | オプション。 |
ログタイプ | string | メトリクスの計算に使用されるテーブル。 ベースラインまたは入力。 |
スライスキー | string | スライス表現。デフォルトでは NULL で、すべてデータです。 |
スライス値 | string | スライス式の値。 |
列名 | string | プライマリ テーブルの列の名前。 |
データ型 | string |
|
logging_table_commit_version | int | 無視してください。 |
モニターバージョン | bigint | 行のメトリクスを計算するために使用されるプロファイル構成のバージョン。 詳細は下記[3]を参照。 |
メトリクス列 - 概要統計 | ||
count | bigint | null 以外の値の数。 |
num_nulls | bigint |
|
avg | double | 列の算術平均(NULL を無視)。 |
quantiles |
| 1000 個の分位数の配列。下記[4]を参照。 |
個別カウント | bigint |
|
min | double |
|
max | double |
|
stddev | double |
|
ゼロの数 | bigint |
|
num_nan | bigint |
|
最小サイズ | double |
|
最大サイズ | double |
|
平均サイズ | double |
|
最小長さ | double |
|
最大長さ | double |
|
平均長さ | double |
|
frequent_items | 構造。下記[1]を参照。 | 最も頻繁に発生する上位 100 件の項目。 |
非NULL列 |
| 少なくとも 1 つの null 以外の値を持つ列のリスト。 |
median | double |
|
パーセント_null | double |
|
パーセントゼロ | double |
|
パーセント別 | double |
|
メトリクス列 - 分類モデルの精度 [5] | ||
精度スコア | double | モデルの精度は次のように計算されます。
NULL値は無視されます。 |
ログ損失 | double | 分類問題のログ損失は次のように計算されます。
|
roc_auc_score | 構造。下記[1]を参照。 | バイナリおよびマルチクラス分類の ROC AUC スコア。 |
混乱マトリックス | 構造。下記[1]を参照。 | |
precision | 構造。下記[1]を参照。 | |
recall | 構造。下記[1]を参照。 | |
f1_スコア | 構造。下記[1]を参照。 | |
メトリクス列 - 回帰モデルの精度 [5] | ||
平均二乗誤差 | double |
|
二乗平均平方根誤差 | double |
|
mean_average_error | double |
|
平均絶対パーセント誤差 | double |
|
r2_スコア | double | R二乗スコアは |
メトリクスコラム - 公平性と偏り [6] | ||
予測パリティ | double | 2 つのグループの精度がすべての予測クラスにわたって等しいかどうかを測定します。 |
予測平等 | double | 2 つのグループのすべての予測クラスにわたる偽陽性率が等しいかどうかを測定します。 |
機会均等 | double | 2 つのグループがすべての予測クラスにわたって同等の再現率を持っているかどうかを測定します。 |
統計的パリティ | double | 2 つのグループの受け入れ率が等しいかどうかを測定します。ここでの受け入れ率は、すべての予測クラスの中で、特定のクラスとして予測される経験的確率として定義されます。 |

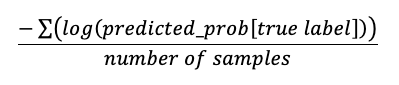
[1] confusion_matrix 、 precision 、 recall 、 f1_score 、 roc_auc_scoreの構造体のフォーマット:
列名 | Type |
|---|---|
window |
|
frequent_items |
|
混乱マトリックス |
|
precision |
|
recall |
|
f1_スコア |
|
roc_auc_score |
|
[2] 時系列プロファイルまたは推論プロファイルの場合、プロファイルは作成日から30日間遡って参照されます。このカットオフにより、最初の分析に部分的なウィンドウが含まれる可能性があります。たとえば、30 日間の制限が週または月の途中に当たる場合、その週または月全体が計算に含まれません。この問題は最初のウィンドウにのみ影響します。
[3] この列に表示されているバージョンは、行の統計を計算するために使用されたバージョンであり、プロファイルの現在のバージョンではない可能性があります。メトリクスを更新するたびに、プロファイルは現在のプロファイル構成を使用して以前に計算されたメトリクスを再計算しようとします。 現在のプロファイル バージョンは、API および Python クライアントによって返されるプロファイル情報に表示されます。
[4] 50パーセンタイルを取得するためのサンプルコード: SELECT element_at(quantiles, int((size(quantiles)+1)/2)) AS p50 ...またはSELECT quantiles[500] ... 。
[5] プロファイルにInferenceLog分析タイプがあり、 label_colとprediction_col両方が指定されている場合にのみ表示されます。
[6] プロファイルにInferenceLog分析タイプがあり、 problem_typeがclassificationの場合にのみ表示されます。
ドリフト メトリクス テーブルのスキーマ
次の表は、ドリフト メトリクス テーブルのスキーマを示しています。 ドリフト テーブルは、ベースライン テーブルが提供されている場合、または指定された粒度に従って集計された後に連続した時間ウィンドウが存在する場合にのみ生成されます。メトリクスが行に適用できない場合、対応するセルは null になります。
列名 | Type | 説明 |
|---|---|---|
列のグループ化 | ||
window |
| 時間ウィンドウ。 |
ウィンドウcmp |
| drift_type |
ドリフトタイプ | string | ベースラインまたは連続。ドリフト メトリクスを前の時間枠と比較するか、ベースライン テーブルと比較するか。 |
granularity | string | ウィンドウ期間。 |
model_id_col | string | オプション。 |
スライスキー | string | スライス表現。デフォルトでは NULL で、すべてデータです。 |
スライス値 | string | スライス式の値。 |
列名 | string | プライマリ テーブルの列の名前。 |
データ型 | string |
|
モニターバージョン | bigint | 行のメトリクスを計算するために使用されるモニター構成のバージョン。 詳細については下記[8]を参照。 |
メトリクス列 - ドリフト | 差異は現在のウィンドウ - 比較ウィンドウとして計算されます。 | |
カウントデルタ | double |
|
平均デルタ | double |
|
percent_null_delta | double |
|
パーセントゼロデルタ | double |
|
パーセント別差分 | double |
|
非NULL列デルタ |
| NULL 以外の値が増加または減少した列の数。 |
chi_squared_test |
| 分布のドリフトを調べるカイ二乗検定。カテゴリ列に対してのみ計算されます。数値列の場合は |
ks_テスト |
| 分布のドリフトを検定する KS テスト。数値列のみ計算されます。カテゴリ列の場合は |
テレビ距離 | double | 分布のドリフトの合計変動距離。カテゴリ列に対してのみ計算されます。数値列の場合は |
l_infinity_distance | double | 分布のドリフトの L 無限大距離。カテゴリ列に対してのみ計算されます。数値列の場合は |
js_距離 | double | 分布のドリフトに関する Jensen–Shannon 距離。カテゴリ列に対してのみ計算されます。数値列の場合は |
ワッサーシュタイン距離 | double | Wasserstein 距離メトリクスを使用して、2 つの数値分布間のドリフトを計算します。 数値列のみ計算されます。カテゴリ列の場合は |
人口安定指数 | double | メトリクスは、母集団安定性指標メトリクスを使用して 2 つの数値分布間のドリフトを比較します。 詳細については下記[9]を参照。数値列のみ計算されます。カテゴリ列の場合は |
[7] 時系列プロファイルや推論プロファイルの場合、プロファイルは作成日から30日間遡って参照されます。このカットオフにより、最初の分析に部分的なウィンドウが含まれる可能性があります。たとえば、30 日間の制限が週または月の途中に当たる場合、その週または月全体が計算に含まれません。この問題は最初のウィンドウにのみ影響します。
[8] この列に表示されているバージョンは、行の統計を計算するために使用されたバージョンであり、プロファイルの現在のバージョンではない可能性があります。メトリクスを更新するたびに、プロファイルは現在のプロファイル構成を使用して以前に計算されたメトリクスを再計算しようとします。 現在のプロファイル バージョンは、API および Python クライアントによって返されるプロファイル情報に表示されます。
[9] 人口安定指数の出力は、2つの分布がどれだけ異なるかを表す数値です。範囲は [0, inf) です。PSI < 0.1 は、有意な人口変化がないことを意味します。PSI < 0.2 は中程度の人口変化を示します。PSI >= 0.2 は、人口の大きな変化を示します。