データファイルのサイズを制御する
この記事の手動チューニングの推奨事項は、自動ファイル サイズ チューニングを使用するUnity Catalogマネージドテーブルには適用されません。 新しいテーブルの場合は、 Unity Catalogマネージドテーブルを無事設定して使用します。
Databricks Runtime 13.3 以降では、テーブル レイアウトにクラスタリングを使用することが Databricks によって推奨されています。「テーブルにリキッドクラスタリングを使用する」を参照してください。
Databricks 、予測的最適化を使用してテーブルに対してOPTIMIZEとVACUUMを自動的に実行することをお勧めします。 Unity Catalogマネージドテーブルについては、「予測的最適化」を参照してください。
Databricks Runtime 10.4 LTS 以降では、 MERGE、 UPDATE、 DELETE の各操作で、自動圧縮と最適化された書き込みが常に有効になっています。 この機能は無効にできません。
書き込みおよびOPTIMIZE操作のターゲット ファイル サイズを手動または自動で構成するオプションがあります。Databricks はこれらの設定の多くを自動的に調整し、適切なサイズのファイルを求めてテーブルのパフォーマンスを自動的に向上させる機能を有効にします。
Unity Catalogマネージドテーブルの場合、Databricks SQLウェアハウスまたはDatabricks Runtime 11.3 以降を使用している場合、LTS はこれらの構成のほとんどを自動的に調整します。
Databricks Runtime 10.4 LTS 以下からワークロードをアップグレードする場合は、「 バックグラウンド自動圧縮へのアップグレード」を参照してください。
実行タイミング: OPTIMIZE
自動圧縮と最適化された書き込みはそれぞれ小さなファイルの問題を軽減しますが、 OPTIMIZEの完全な代替にはなりません。特に1TBを超えるテーブルの場合、DatabricksはOPTIMIZEをスケジュールして実行し、ファイルをさらに統合することを推奨します。Databricksは、データスキップ機能を強化するために、リキッドクラスタリングを推奨しています。液体クラスタリングが有効な場合、 OPTIMIZEクラスタリング キーによってデータを自動的に再編成します。 テーブルにはリキッドクラスタリングを使用するを参照してください。
Unity Catalogマネージド テーブルの場合、予測的最適化が有効になっているテーブルで予測的最適化が自動的OPTIMIZE実行されます。
Databricks の自動最適化とは
自動最適化 という用語は、設定autoOptimize.autoCompactおよびautoOptimize.optimizeWriteによって制御される機能を説明するために使用されることがあります。この用語は廃止され、各設定を個別に説明するようになりました。自動圧縮と最適化された書き込みを参照してください。
自動圧縮
自動圧縮機能は、テーブルパーティション内の小さなファイルを結合することで、小さなファイルに関する問題を軽減します。書き込み処理が成功した後、書き込みを実行するクラスター上で同期的に実行され、以前に圧縮されていないファイルのみを圧縮します。
自動圧縮と予測的最適化は、個別にまたは一緒に使用できる独立した機能です。 書き込みを実行するクラスター上で自動圧縮を実行し、一方、予測的最適化実行は、サーバーレス コンピュートを使用して非同期にメンテナンス操作を実行します。
自動圧縮を設定するには、以下の設定を使用してください。
設定 | Delta | Iceberg | 説明 |
|---|---|---|---|
自動圧縮を有効にする(テーブルプロパティ) |
|
| テーブルレベルでの自動圧縮を有効にします。 |
自動圧縮を有効にする(Sparkセッション) |
|
| セッションレベルでの自動圧縮を有効にします。 |
最大出力ファイルサイズ |
|
| 出力ファイルのサイズを制御します。 |
圧縮をトリガーする最小ファイル数 |
|
| パーティションまたはテーブル内で自動圧縮をトリガーするために必要な最小の小ファイル数を設定します。 |
これらの設定では、次のオプションを使用できます:
オプション | 挙動 |
|---|---|
| 他のオートチューニング機能を尊重しながら、ターゲットファイルサイズを調整します。 Databricks Runtime 10.4 LTS 以降が必要です。 |
|
|
| ターゲットファイルサイズとして128 MBを使用します。動的なサイズ設定はありません。 |
| 自動圧縮をオフにします。セッション レベルで設定して、ワークロード内で変更されたすべてのテーブルの自動圧縮をオーバーライドできます。 |
Databricksは、テーブルサイズに基づいて出力ファイルサイズを制御するために、自動チューニングを使用することを推奨しています。テーブルサイズに基づいたオートチューンファイルのサイズを参照してください。
最適化された書き込み
書き込みが最適化されると、データが書き込まれるときのファイルサイズが改善され、その後のテーブルの読み取りが向上します。
最適化された書き込みは、各パーティションに書き込まれる小さなファイルの数を減らすため、パーティション分割されたテーブルに対して最も効果的です。小さなファイルを多数書き込むよりも、大きなファイルの書き込みを少なくするほうが効率的ですが、データが書き込まれる前にシャッフルされるため、書き込み遅延が増加する可能性があります。
次の図は、最適化された書き込みがどのように機能するかを示しています:
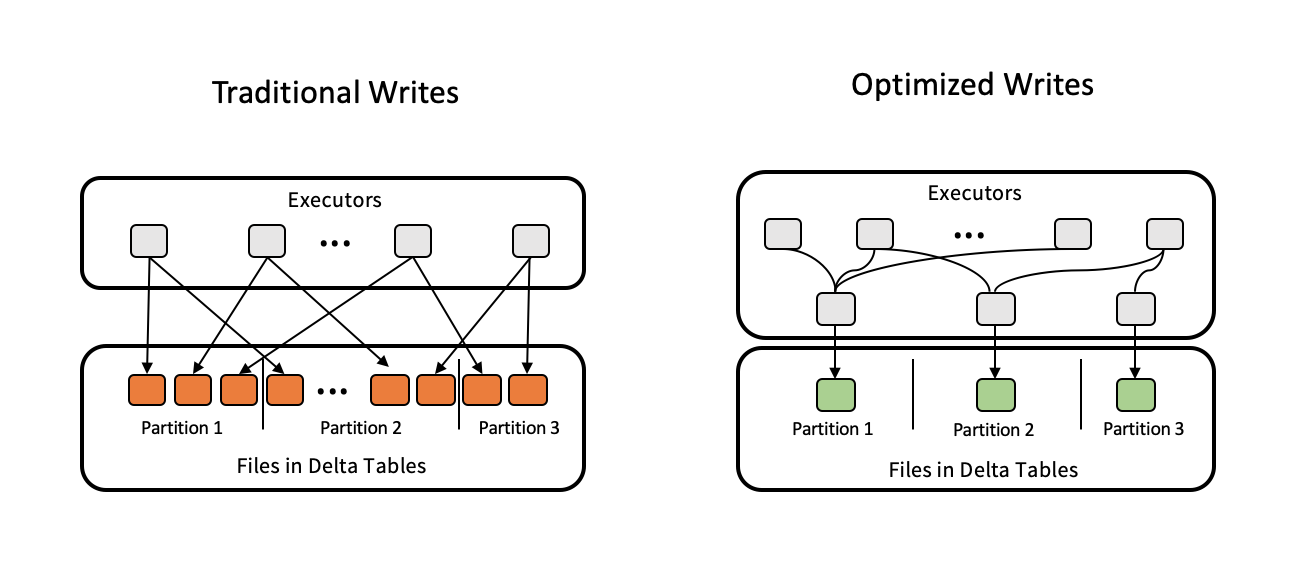
データを書き出す直前に coalesce(n) または repartition(n) 実行されるコードを使用して、書き込まれるファイルの数を制御する場合があります。 最適化された書き込みにより、このパターンを使用する必要がなくなります。
Databricks Runtime 9.1 LTS以降では、以下のオペレーションで最適化された書き込みがデフォルトで有効になっています:
MERGEUPDATEサブクエリー付きDELETEサブクエリー付き
SQLウェアハウスを使用する場合、最適化された書き込みは、 CTASステートメントとINSERT操作に対しても有効になります。 Databricks Runtime 13.3 LTS以降では、 Unity Catalogに登録されているすべてのテーブルで、パーティション分割されたテーブルのCTASステートメントとINSERT操作に対して最適化された書き込みが有効になっています。
最適化された書き込みは、次の設定を使用してテーブルレベルまたはセッションレベルで有効にすることができます:
- テーブルプロパティ:
autoOptimize.optimizeWrite - SparkSession設定:
spark.databricks.delta.optimizeWrite.enabled( Delta ) またはspark.databricks.iceberg.optimizeWrite.enabled( Iceberg )
これらの設定では、次のオプションを使用できます:
オプション | 挙動 |
|---|---|
| ターゲットファイルサイズとして128 MBを使用します。 |
| 最適化された書き込みをオフにします。セッション レベルで設定して、ワークロード内で変更されたすべてのテーブルの自動圧縮をオーバーライドできます。 |
ターゲット ファイル サイズを設定する
テーブル内のファイルのサイズを調整したい場合は、テーブルプロパティtargetFileSizeを希望のサイズに設定してください。設定されている場合、最適化、リキッドクラスタリング、自動圧縮、最適化された書き込みなど、すべてのデータレイアウト最適化操作は、指定されたサイズのファイルを生成するために最善を尽くします。
Unity Catalogで管理されるテーブルとSQLウェアハウス、またはDatabricks Runtime 11.3 LTS以降を使用する場合、OPTIMIZEコマンドのみがtargetFileSize設定を尊重します。
属性 | 説明 |
|---|---|
| タイプ : バイト以上の単位でのサイズ。 説明 : 対象ファイルのサイズ。たとえば、 デフォルト値 : なし |
既存のテーブルの場合は、SQL コマンドALTER TABLE SET TBL PROPERTIESを使用してプロパティを設定および設定解除できます。Spark セッション構成を使用して新しいテーブルを作成するときに、これらのプロパティを自動的に設定することもできます。詳細については、テーブル プロパティのリファレンスを参照してください。
テーブルサイズに基づくファイルサイズの自動調整
手動での調整の必要性を最小限に抑えるため、Databricksはテーブルのサイズに基づいてテーブルのファイルサイズを自動的に調整します。Databricksは、テーブル内のファイル数が過剰に増えないように、小さいテーブルには小さいファイルサイズを、大きいテーブルには大きいファイルサイズを使用します。Databricks は、特定のターゲット サイズでチューニングしたテーブルを自動的にチューニングしません。
ターゲット ファイル サイズは、テーブルの現在のサイズに基づきます。2.56 TB 未満のテーブルの場合、自動調整されたターゲット ファイルのサイズは 256 MB になります。サイズが 2.56 TB から 10 TB までのテーブルの場合、ターゲット サイズは 256 MB から 1 GB まで直線的に増加します。10 TB を超えるテーブルの場合、ターゲット ファイル サイズは 1 GB です。
テーブルのターゲットファイルサイズが大きくなった場合、既存のファイルは、OPTIMIZEコマンドによってより大きなファイルに再最適化されません。したがって、大きなテーブルには、ターゲットサイズよりも小さいファイルが常に含まれる可能性があります。これらの小さいファイルをさらに大きいファイルに最適化する必要がある場合は、targetFileSizeテーブルプロパティを使用してテーブルの固定ターゲットファイルサイズを構成できます。
テーブルが増分的に書き込まれる場合、ターゲットファイルサイズとファイル数は、テーブルサイズに基づいて次の数値に近くなります。このテーブルのファイル数は単なる例です。実際の結果は、多くの要因によって異なります。
テーブルサイズ | ターゲットファイルサイズ | テーブル内のファイルのおおよその数 |
|---|---|---|
10 GB | 256 MB | 40 |
1 TB | 256 MB | 4096 |
2.56 TB | 256 MB | 10240 |
3TB | 307 MB | 12108 |
5 TB | 512 MB | 17339 |
7 TB | 716 MB | 20784 |
10 TB | 1 GB | 24437 |
20 TB | 1 GB | 34437 |
50 TB | 1 GB | 64437 |
100 TB | 1 GB | 114437 |
データファイルに書き込まれる行を制限する
場合によっては、データの範囲が狭いテーブルでは、特定のデータ ファイル内の行数が Parquet 形式のサポート制限を超えるとエラーが発生することがあります。このエラーを回避するには、SQL セッション構成spark.sql.files.maxRecordsPerFileを使用して、テーブルの 1 つのファイルに書き込むレコードの最大数を指定します。ゼロまたは負の値を指定すると、制限がないことを示します。
Databricks Runtime 11.3 LTS以降では、 DataFrame APIsを使用してテーブルに書き込むときに、DataFrameWriter オプションmaxRecordsPerFileを使用することもできます。 maxRecordsPerFileが指定されている場合、SQL セッション構成spark.sql.files.maxRecordsPerFileの値は無視されます。
Databricksでは、前述のエラーを回避する必要がない限り、このオプションの使用をお勧めしません。この設定は、非常に狭いデータを含む一部のUnity Catalogマネージドテーブルでは引き続き必要になる場合があります。
バックグラウンド自動圧縮へのアップグレード
バックグラウンド自動圧縮は、 Databricks Runtime 11.3 LTS以降のUnity Catalogマネージドテーブルで利用できます。 バックグラウンドの自動圧縮には予測的最適化は必要ありません。 レガシーワークロードまたはテーブルを移行する場合は、次の操作を実行してください。
- クラスターまたはノートブックの構成設定から Spark 構成
spark.databricks.delta.autoCompact.enabled(Delta) またはspark.databricks.iceberg.autoCompact.enabled(Iceberg) を削除します。 - 各テーブルに対して、
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) またはALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) を実行して、従来の自動圧縮設定を削除します。
これらの従来の設定を削除すると、すべての Unity Catalog マネージドテーブルに対してバックグラウンドの自動圧縮が自動的にトリガーされます。