Lakeflow Designer とは何ですか?
Lakeflow Designerは、アナリストがデータ分析、データ準備、および基本的な自動化を実行するための視覚的なキャンバスを提供します。Designerでは、視覚的なデータ準備ファイルを作成します。各ファイルは、結果を生成するためにDAGとして配置された一連の演算子(フィルタ、結合、変換など)で構成されます。すべての変換はコードによってサポートされているため、 Gitでファイルのバージョンを管理し、それらをジョブとしてスケジュールして、本番運用にシームレスに移行できます。
Lakeflow Designer を使用すると、次のことが可能になります。
- ドラッグ&ドロップ式のキャンバスを使った デザインワークフロー 。
- 組み込み演算子を使用してデータをフィルタリング、集計、結合、および再形成することで 、コードを記述せずにデータを変換します 。
- Genie Code を使用すると 、自然言語を使ってビジュアルデータ準備における変換を生成または調整できます。
- パイプライン全体を実行せずに、 各中間ステップをプレビューできます 。
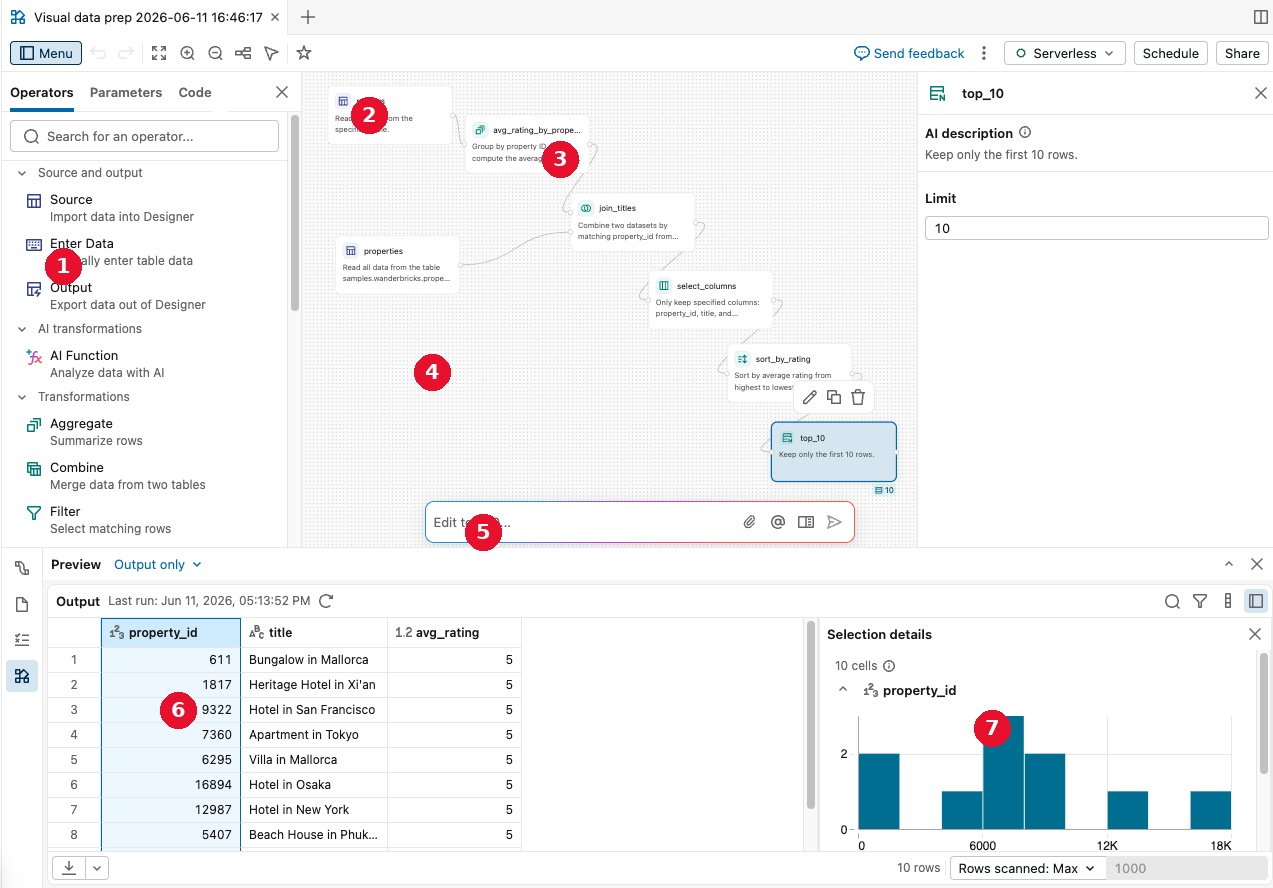
上の画像には、以下のものが写っています。
- メニュー、 Operators および パラメーター タブ付き
- オペレーター
- 2人のオペレーター間の接続
- ドラッグ&ドロップキャンバス
- Genie Codeプロンプト
- 出力ペイン
- 出力のデータプロファイリング
重要な概念
メニュー
左ペインのメニューで、ビジュアルデータ準備のためのビルディングブロックを見つけることができます。3つのタブがあります。
- オペレーター:組み込みオペレーター を参照して検索します。リストからオペレータータイプをキャンバスにドラッグアンドドロップして追加します。
- パラメーター : ビジュアルデータプレップ向けのパラメーターを定義および管理します。
- 目次 :ビジュアルデータの準備で任意のオペレーターを見つけて移動し、それぞれに生成されたコードを表示できます。目次をご覧ください。
キャンバス
キャンバスは、オペレーターを追加、設定、接続してビジュアルデータ準備を構築するメインのワークスペースです。
キャンバス内を移動するには:
- パン : スペースキー を押しながらクリックしてドラッグするか、トラックパッド上で 2 本の指をスライドします。
- ズーム : トラックパッド上でピンチまたはストレッチするか、 Ctrl キー を押しながらスクロールします。
キャンバスツールバーは、キャンバスナビゲーションツールとともにヘッダー部分に配置されています。![]() ズームイン、
ズームイン、![]() ズームアウトして、
ズームアウトして、![]() フィットビュー、
フィットビュー、![]() 自動レイアウト、そして
自動レイアウト、そして![]() ドラッグモード。
ドラッグモード。
キャンバス上の任意の場所を右クリックすると、演算子の追加、元に戻すとやり直し、自動レイアウト、ビューの調整、コード ペインのオープンなどの一般的なアクションにアクセスできます。
エディターのアクションにすばやくアクセスするには、macOS では Cmd+Shift+P 、Windows では Ctrl+Shift+P を押してコマンド パレットを開きます。
Excel または CSV ファイルをキャンバスに直接ドラッグ アンド ドロップして、そのファイルのソース演算子を作成することもできます。
オペレーター
オペレーターはビジュアルデータの準備の構成要素です。演算子は、結合、変換、フィルタなどのアクションです。キャンバス上でオペレーターを連結して、ワークフローを構築できます。各演算子は、その種類に基づいて設定できます。演算子には、AI支援による効果の説明が表示されます。説明を編集すると、演算子が再構成されます。
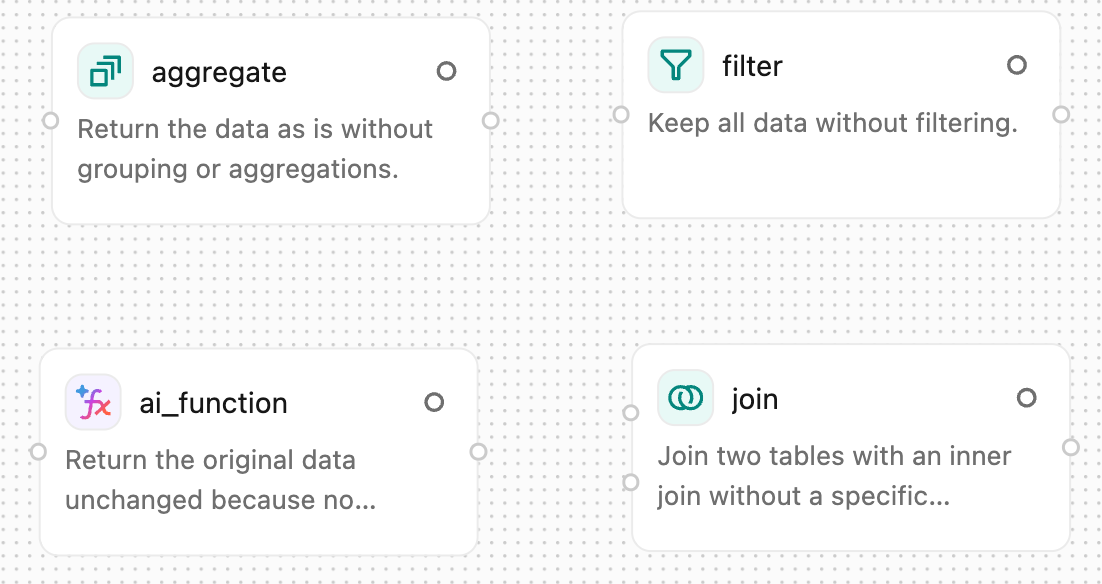
Lakeflow Designer には、一般的なデータ変換タスク用の組み込み演算子が含まれています。 詳細については、 Lakeflow Designer の組み込み演算子」を参照してください。
接続
接続によって、オペレーター間でデータがどのように流れるかが定義されます。接続を作成するには、あるオペレーターの右端にあるポートをドラッグして、別のオペレーターの左端にあるポートに接続します。これは、データが最初のオペレーターから2番目のオペレーターに流れることを示します。データはビジュアルデータの準備を通じて左から右へ流れます。 Join や Combine などの一部のオペレーターは、複数の入力接続を受け入れます。
ノードポートは大きな接続ターゲットと明確な視覚的合図を提供するため、オペレーターの接続が簡単になります。
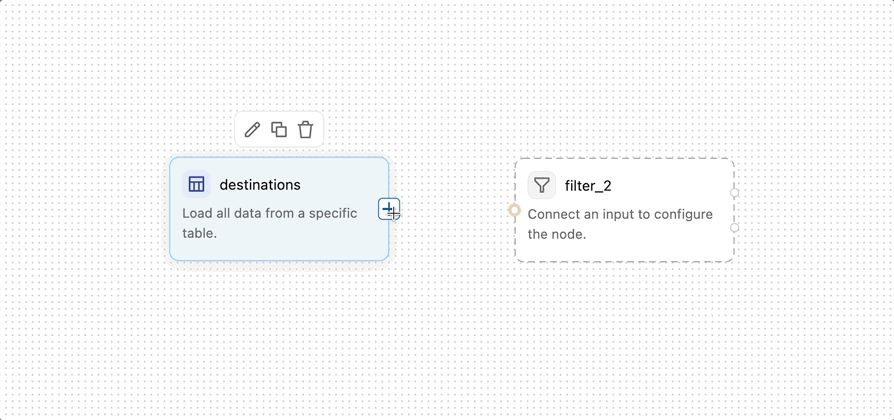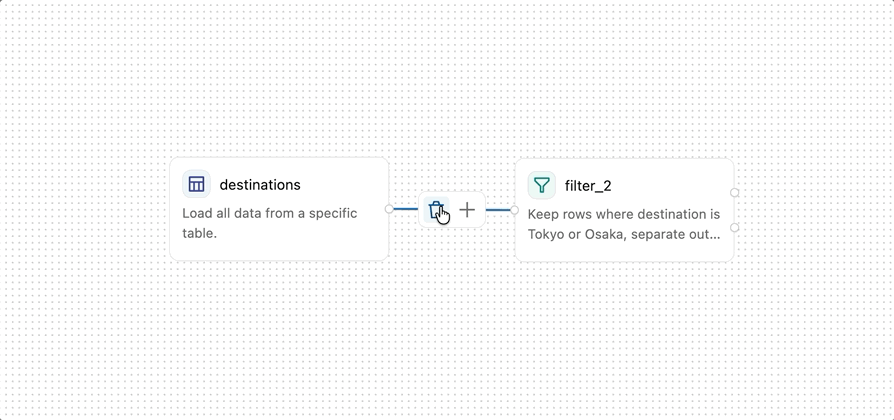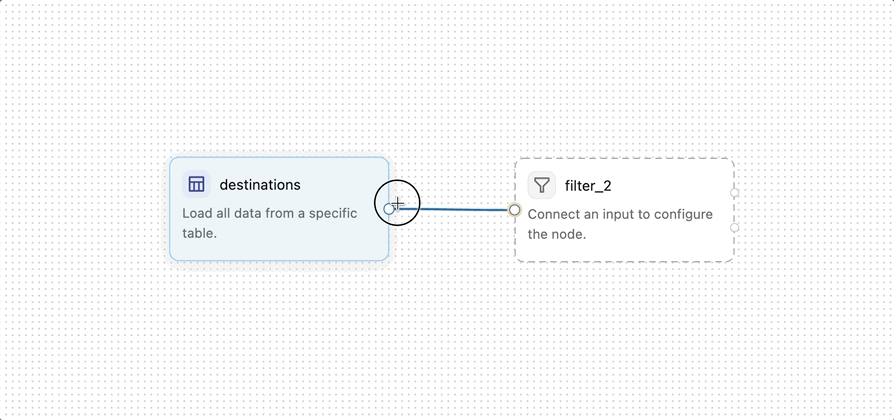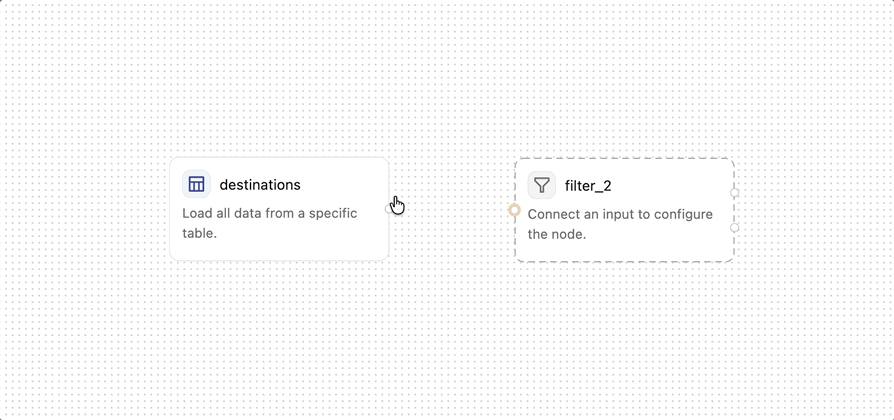
演算子のポートは、その設定ステータスも示します。
- 未設定のオペレーターには破線の境界線があります。
- 接続されていない必須入力ポートは黄色でハイライトされます。
出力ペイン
オペレーターを選択すると、出力ペインが画面の下部に表示されます。いずれかの演算子を選択して、画面下部の出力ウィンドウで結果を確認します。ほとんどの演算子では、入力データは左側に、出力データは右側にあります。プロット、HTML、または画像など、表形式以外の結果を生成するオペレーターは、その出力を出力ペインに直接表示します。
出力ペインの表示コントロールを使用して、入力と出力(デフォルト)、入力のみ、または出力のみを切り替えます。結合ビューで、区切りをドラッグして入力ペインと出力ペインのサイズを変更します。
defaultでは、オペレーターは限られたデータサンプルを処理します。出力ペインの Rows scanned ドロップダウンメニューを使用して、処理する行数を制御します。
- スキャンする行数:制限 : 最初のN個の入力行を処理します。ドロップダウンメニューの隣のフィールドで行数を指定します。
- スキャンされた行数: 最大 : すべての入力行を処理します。

行 スキャンを実行しても、Max は 完全な無制限のデータセットを使用してすべての上流オペレーターを再実行するため、時間がかかる場合があります。
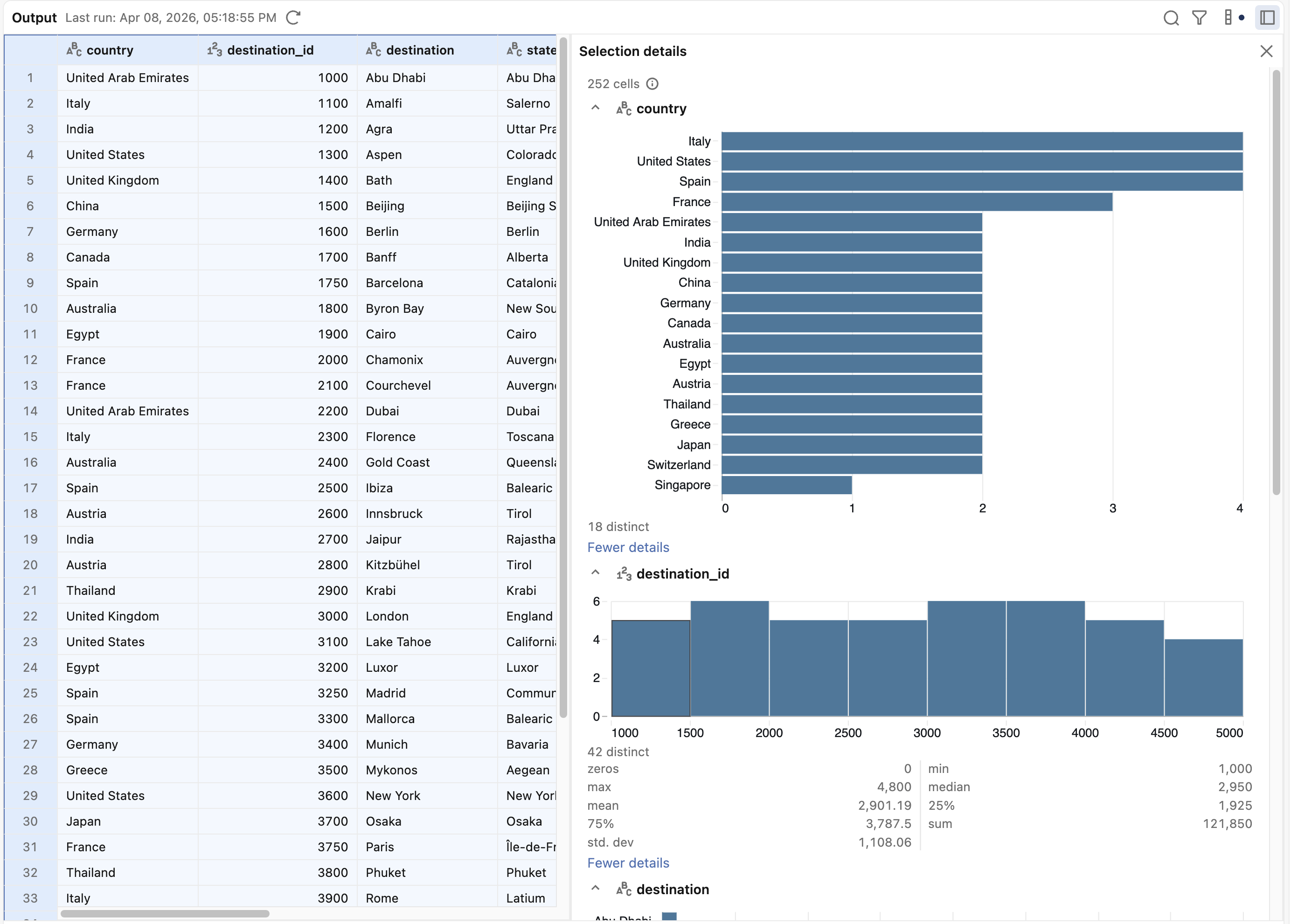
データプロファイリング
出力の一部に関する詳細を表示するには、検査したいデータを選択し、出力ペインの右上隅にある ![]() サイドバーボタンをクリックして詳細パネルを開きます。
サイドバーボタンをクリックして詳細パネルを開きます。
Genie Code
Genie Codeを使用すると、自然言語で変換を記述できます。すべてのインタラクションはエージェントによって行われ、Databricksプラットフォームのコンテキストを使用します。See Genie Code.

変換を生成または修正するプロンプトを入力します。Genie Codeのやり取りの履歴を表示し、各応答の詳細を確認するには、右サイドバーの![]() をクリックしてGenie Codeサイドペインを開きます。サイドペインが開いているとき、キャンバス内ツールバーは最小化されます。Genie Codeは、入力ボックスの上に最新の編集の1行の要約を表示します。
をクリックしてGenie Codeサイドペインを開きます。サイドペインが開いているとき、キャンバス内ツールバーは最小化されます。Genie Codeは、入力ボックスの上に最新の編集の1行の要約を表示します。
目次
左側のメニューにある 目次 tab には、ビジュアルデータ準備内のすべての演算子がリスト表示され、名前で検索できます。キャンバス上で演算子を選択して、それをフォーカスします。すべてのビジュアルデータ準備は、生成されたコードによって支えられています。演算子のコードを検査するには、目次でそれを選択し、 生成されたコード セクションを展開してその基盤となるコードを表示します。
パラメーター
パラメーター は、ビジュアルデータプレップ全体のために定義された名前付きの値で、SQLおよびPython演算子から参照できます。パラメーターを管理するには、左側のメニューで**パラメーター**タブを開きます。
各パラメーターには、定義するときに設定する値があります。ビジュアルデータの準備をスケジュールして実行する際、各スケジュールで必要に応じてこれらの値を上書きできます。例えば、同じビジュアルデータの準備を、environmentパラメーターをtestに設定して毎日正午に実行するように、またenvironmentをproductionに設定して午後2時に実行するようにスケジュール設定できます。
オペレーターからパラメーターを次のように参照します。
- SQL operator : Use named パラメーター marker syntax, such as
:environment. 名前付きパラメーターマーカーの使用を参照してください。 - Python演算子 :
dbutils.widgets.get()を呼び出します(例:dbutils.widgets.get("environment"))。ウィジェットツール (dbutils.widgets)をご覧ください。
編集のために SQL または Python オペレーターを開くと、Lakeflow Designer はソースエディターの上に利用可能なパラメーターを参照する方法の例を表示します。