Databricks のベストプラクティスと推奨される CI/CD ワークフロー
CI/CD (継続的インテグレーションと継続的デリバリー)は、コード変更の統合、テスト、デプロイを迅速かつ確実に行うことができるため、最新のデータエンジニアリングとアナリティクスの基盤となっています。 Databricks は、組織の好み、既存のワークフロー、特定のテクノロジー環境によって形成される多様な CI/CD 要件が存在する可能性があることを認識し、さまざまな CI/CD オプションをサポートする柔軟なフレームワークを提供します。
このページでは、お客様固有のニーズと制約に合わせた堅牢でカスタマイズされた CI/CD パイプラインを設計および構築するためのベスト プラクティスについて説明します。これらの知見を活用することで、データエンジニアリングとアナリティクスの取り組みを加速し、コード品質を向上させ、デプロイの失敗リスクを軽減できます。
CI/CDの基本原則
効果的な CI/CD パイプラインは、実装の詳細に関係なく、基本原則を共有します。次の普遍的なベスト プラクティスは、組織の好み、開発者ワークフロー、クラウド環境全体に適用され、チームがノートブック ファーストの開発を優先するか、ワークフローを優先するかに関係なく、さまざまな実装間で一貫性を確保します Infrastructure-as-Code 。 これらの原則をガードレールとして採用し、組織のテクノロジースタックとプロセスに合わせて詳細を調整します。
-
すべてのバージョン管理
- ノートブック、スクリプト、インフラストラクチャ定義 (IaC)、ジョブ構成を Git に格納します。
- Gitflow などの分岐戦略は、標準的な開発、ステージング、本番運用のデプロイ環境に合わせて調整されます。
-
テストの自動化
- Python の pytest や Scala の ScalaTest などのライブラリを使用して、ビジネス ロジックの単体テストを実装します。
- ノートブックとワークフローの機能は、Databricks CLI バンドル検証などのツールを使用して検証します。
- ワークフローとデータパイプラインの統合テストを使用します (例: chispa for Spark DataFrames)。
-
Infrastructure as Code(IaC)の採用
- 宣言型自動化バンドルYAMLまたはTerraformを使用して、クラスター、ジョブ、ワークスペース構成を定義します。
- クラスター サイズやシークレットなどの環境固有の設定をハードコーディングする代わりに、パラメーター化します。
-
環境を分離する
- 開発、ステージング、本番運用用に別々のワークスペースを維持します。
- 環境間でのモデルのバージョン管理には、MLflow Model Registryを使用します。
-
クラウドエコシステムに適したツールをお選びください。
- Azure: Azure DevOpsおよび宣言型自動化バンドル、またはTerraform。
- AWS: GitHub ActionsとDeclarative Automation Bundles、またはTerraform。
- GCP : クラウド ビルドおよび宣言的自動化バンドルまたはTerraform 。
-
ロールバックの監視と自動化
- デプロイの成功率、ジョブのパフォーマンス、テストカバレッジを追跡します。
- 失敗したデプロイの自動ロールバック メカニズムを実装します。
-
資産管理の統合
- 宣言型自動化バンドルを使用すると、コード、ジョブ、インフラストラクチャを単一のユニットとしてデプロイできます。ノートブック、ライブラリ、ワークフローを個別に管理することは避けてください。
Databricks では、CI/CD 認証にワークロード ID フェデレーションをお勧めします。ワークロード ID フェデレーションを使用すると、Databricks シークレットが不要になるため、Databricks への自動フローを認証する最も安全な方法になります。「 CI/CD でのワークロード ID フェデレーションの有効化」を参照してください。
CI/CD向け宣言型自動化バンドル
Declarative Automation Bundle (以前はDatabricks Asset Bundle として知られていました) は、 Databricksエコシステム内のコード、ワークフロー、インフラストラクチャを管理するための強力で統一されたアプローチを提供し、 CI/CDパイプラインに推奨されます。 これらの要素を単一のYAML定義ユニットにまとめることで、バンドルはデプロイメントを簡素化し、環境間での一貫性を確保します。ただし、従来のCI/CDワークフローに慣れているユーザーにとって、バンドルを採用するには考え方の転換が必要になる場合があります。
たとえば、Java 開発者は、Maven や Gradle を使用して JAR を作成し、JUnit を使用して単体テストを実行し、これらの手順を CI/CD パイプラインに統合することに慣れています。同様に、Python 開発者は多くの場合、コードをホイールにパッケージ化して pytest でテストしますが、SQL 開発者はクエリの検証とノートブックの管理に重点を置いています。バンドルを使用すると、これらのワークフローはより構造化された規範的な形式に収束し、シームレスなデプロイのためのコードとインフラストラクチャのバンドルが強調されます。
次のセクションでは、開発者がバンドルを効果的に活用するためにワークフローを適応させる方法について説明します。
宣言型自動化バンドルをすぐに使い始めるには、チュートリアル「宣言型自動化バンドルを使用したジョブの開発」または「宣言型自動化バンドルを使用したパイプラインの開発」をお試しください。
CI/CD ソース管理の推奨事項
CI/CD を実装する際に開発者が最初に選択する必要があるのは、ソース ファイルの保存方法とバージョン管理方法です。バンドルを使用すると、ソース コード、ビルド アーティファクト、構成ファイルなど、すべてを簡単に格納し、それらを同じソース コード リポジトリに配置できますが、バンドル構成ファイルをコード関連ファイルから分離することもできます。 選択は、チームのワークフロー、プロジェクトの複雑さ、CI/CD の要件によって異なりますが、Databricks では次のことを推奨しています。
- 小規模なプロジェクトや、コードと構成の密結合の場合は、コードとバンドルの構成の両方に 1 つのリポジトリを使用してワークフローを簡素化します。
- 大規模なチームや独立したリリース サイクルの場合は、コードとバンドルの構成に別々のリポジトリを使用しますが、バージョン間の互換性を確保する明確な CI/CD パイプラインを確立します。
コード関連ファイルをバンドル構成ファイルと同じ場所に配置するか、バンドル構成ファイルから分離するかにかかわらず、Databricks または外部ストレージにアップロードするときは、常に Git コミットハッシュなどのバージョン管理されたアーティファクトを使用して、トレーサビリティとロールバック機能を確保します。
コードと構成のための単一のリポジトリ
このアプローチでは、ソース コードとバンドル構成ファイルの両方が同じリポジトリに格納されます。これにより、ワークフローが簡素化され、アトミックな変更が保証されます。
長所 | 短所 |
|---|---|
|
|
例: バンドル内の Python コード
この例では、Python ファイルとバンドル ファイルが 1 つのリポジトリにあります。
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── workflows/
│ │ ├── my_pipeline.yml # YAML pipeline def
│ │ └── my_pipeline_job.yml # YAML job def that runs pipeline
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
├── src/
│ ├── my_pipeline.ipynb # pipeline notebook
│ └── mypython.py # Additional Python
└── README.md
コードと構成のリポジトリを分離
このアプローチでは、ソース コードは 1 つのリポジトリに存在し、バンドル構成ファイルは別のリポジトリに保持されます。このオプションは、アプリケーション開発と Databricks ワークフロー管理を別々のグループが担当する大規模なチームやプロジェクトに最適です。
長所 | 短所 |
|---|---|
|
|
例: Java プロジェクトとバンドル
この例では、Java プロジェクトとそのファイルは 1 つのリポジトリにあり、バンドル ファイルは別のリポジトリにあります。
リポジトリ 1: Java ファイル
最初のリポジトリには、すべてのJava関連ファイルが含まれています。
java-app-repo/
├── pom.xml # Maven build configuration
├── src/
│ ├── main/
│ │ ├── java/ # Java source code
│ │ │ └── com/
│ │ │ └── mycompany/
│ │ │ └── app/
│ │ │ └── App.java
│ │ └── resources/ # Application resources
│ └── test/
│ ├── java/ # Unit tests for Java code
│ │ └── com/
│ │ └── mycompany/
│ │ └── app/
│ │ └── AppTest.java
│ └── resources/ # Test-specific resources
├── target/ # Compiled JARs and classes
└── README.md
- 開発者は、
src/main/javaまたはsrc/main/scalaでアプリケーション コードを記述します。 - 単体テストは、
src/test/javaまたはsrc/test/scalaに格納されます。 - プルリクエストまたはコミットでは、CI/CD パイプライン:
- コードを JAR にコンパイルします (例:
target/my-app-1.0.jar. - JARをDatabricks Unity Catalogボリュームにアップロードします。JARのアップロードを参照してください。
- コードを JAR にコンパイルします (例:
リポジトリ 2: バンドル ファイル
2 番目のリポジトリには、バンドル設定ファイルのみが含まれます。
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── jobs/
│ │ ├── my_java_job.yml # YAML job dev
│ │ └── my_other_job.yml # Additional job definitions
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
└── README.md
-
バンドル構成databricks.ymlとジョブ定義は、独立して保守されます。
-
databricks.ymlは、アップロードされた JAR アーティファクトを参照します。たとえば、次のようになります。
YAML- jar: /Volumes/artifacts/my-app-${{ GIT_SHA }}.)jar
推奨される CI/CD ワークフロー
コード ファイルをバンドル構成ファイルと同じ場所に配置するか、バンドル構成ファイルから分離するかに関係なく、推奨されるワークフローは次のとおりです。
-
コードをコンパイルしてテストする
- pull request またはメイン ブランチへのコミットでトリガーされます。
- コードをコンパイルし、単体テストを実行します。
- バージョン管理されたファイルを出力します (例:
my-app-1.0.jar.
-
コンパイルされたファイル (JAR など) を Databricks Unity Catalog ボリュームにアップロードして保存します。
- コンパイルされたファイルを Databricks Unity Catalog ボリューム、または AWS S3 Storage や Azure Blob Storage などのアーティファクトリポジトリに保存します。
- Git コミット ハッシュまたはセマンティック バージョニングに関連付けられたバージョン管理スキーム (
dbfs:/mnt/artifacts/my-app-${{ github.sha }}.jar.
-
バンドルを検証する
databricks bundle validateを実行して、databricks.yml構成が正しいことを確認します。- この手順により、構成ミス (例えば、ライブラリーの欠落) が早期に発見されます。
-
バンドルをデプロイする
databricks bundle deployを使用して、バンドルをステージング環境または本番運用環境にデプロイします。databricks.ymlでアップロードされたコンパイル済みライブラリを参照してください。ライブラリの参照については、 「宣言的オートメーション バンドルのライブラリの依存関係」を参照してください。
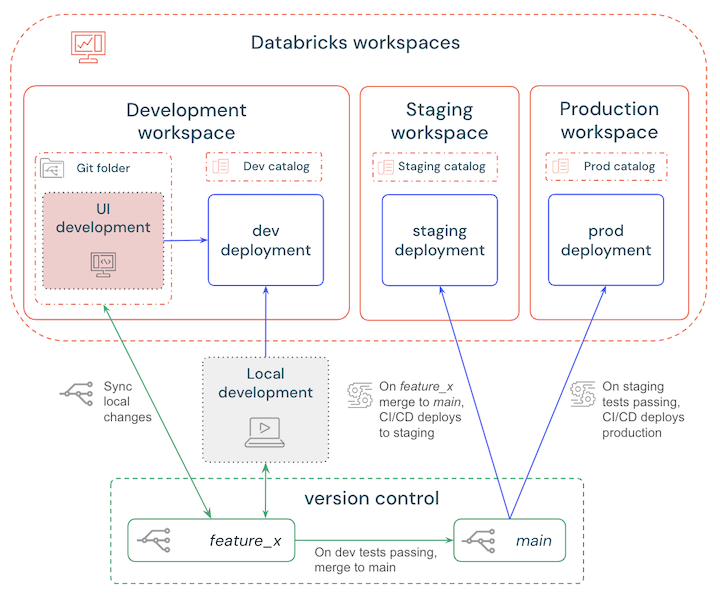
分岐戦略
CI/CD パイプラインを設定するときに、さまざまなブランチ戦略から選択できます。最も簡単なベストプラクティスは次のとおりです。
- ローカルまたはワークスペースで開発し、Databricks 開発ワークスペースにデプロイして変更をテストします。
- 機能ブランチを作成してバージョン管理の更新を行い、ローカルまたはワークスペースの変更を定期的に同期します。
- テストが終了したら、機能ブランチをメイン ブランチにマージします。
- CI/CD はメイン ブランチをステージング ワークスペースに自動的にデプロイし、自動テストがトリガーされます。
- ステージングのテストとチェックに合格すると、 CI/CDメイン ブランチを本番運用ワークスペースにデプロイします。
これらのステップの概要を次の図に示します。
機械学習のCI/CD
機械学習プロジェクトでは、従来のソフトウェア開発と比較して、独自のCI/CDの課題が発生します。ML プロジェクトの CI/CD を実装する場合は、次の点を考慮する必要があります。
- 複数チームの連携:データサイエンティスト、エンジニア、MLOpsチームは、異なるツールやワークフローを使用することがよくあります。Databricksは、エクスペリメント追跡のためのMLflow、データガバナンスのためのOpenSharing、Infrastructure-as-CodeのためのDeclarative Automation Bundlesによって、これらのプロセスを統合します。
- データとモデルのバージョン管理: 機械学習パイプラインでは、コードだけでなく、トレーニング データ スキーマ、特徴分布、モデル アーティファクトも追跡する必要があります。 Delta Lakeデータのバージョン管理にACIDとタイムトラベルを提供し、 MLflow Model Registryモデルのリネージを処理します。
- 環境間での再現性: MLモデルは、特定のデータ、コード、インフラストラクチャの組み合わせに依存します。 宣言型自動化バンドルは、YAML定義を使用して、開発、ステージング、および本番運用環境全体にわたってこれらのコンポーネントのアトミックなデプロイを保証します。
- 継続的な再トレーニングとモニタリング: データ ドリフトによりモデルが劣化します。 Lakeflowジョブによりパイプラインの自動再トレーニングが可能になり、 MLflowパフォーマンス追跡のために Prometheus およびDatabricksデータ品質モニタリングと統合されます。
ML CI/CD 用の MLOps スタック
Databricks 、宣言型オートメーション バンドル、事前構成された CI/CD ワークフロー、およびモジュラーMLプロジェクト テンプレートを組み合わせた本番運用グレードのフレームワークであるMLOpsスタックを通じてML CI/CD CI/CDさに対処します。 これらのスタックは、ベストプラクティスを徹底させると同時に、データエンジニアリング、データサイエンス、MLOpsといった役割にわたる複数チーム間のコラボレーションに柔軟性をもたらします。
チーム | 責任 | バンドルコンポーネントの例 | アーティファクトの例 |
|---|---|---|---|
データエンジニア | ETL パイプラインを構築し、データ品質を強化 | Lakeflow Spark宣言型パイプライン YAML、クラスターポリシー |
|
データサイエンティスト | Develop model トレーニング logic, validate メトリクス | MLflow プロジェクト、ノートブックベースのワークフロー |
|
MLOps エンジニア | デプロイのオーケストレーション、パイプラインの監視 | 環境変数, モニタリング ダッシュボード |
|
ML CI/CD コラボレーションは、次のようになります。
- データエンジニアは、ETL パイプラインの変更をバンドルにコミットし、自動スキーマ検証とステージングデプロイメントをトリガーします。
- data scientists MLコードを送信すると、そのコードが単体テストを実行し、統合テストのためにステージング ワークスペースにデプロイされます。
- MLOps エンジニアは、検証メトリクスをレビューし、 MLflow Registryを使用して審査済みモデルを本番運用に昇格させます。
実装の詳細については、以下を参照してください。
- MLOps スタックバンドル: バンドルの初期化とデプロイに関するステップバイステップのガイダンス。
- MLOps Stacks GitHub リポジトリ: トレーニング、推論、CI/CD 用の事前設定済みテンプレート。
標準化されたバンドルとMLOpsスタックでチームを連携させることで、組織はMLライフサイクル全体で監査可能性を維持しながら、コラボレーションを効率化できます。
SQL 開発者向けの CI/CD
Databricks SQL を使用してストリーミングテーブルとマテリアライズドビューを管理する SQL 開発者は、Git 統合と CI/CD パイプラインを活用してワークフローを合理化し、高品質のパイプラインを維持できます。クエリの Git サポートの導入により、SQL 開発者はクエリの作成に集中しながら、Git を活用して .sql ファイルのバージョン管理を行うことができ、インフラストラクチャの深い専門知識がなくてもコラボレーションと自動化が可能になります。さらに、SQL エディターにより、リアルタイムのコラボレーションが可能になり、Git ワークフローとシームレスに統合できます。
SQL 中心のワークフローの場合:
-
バージョン管理 SQL ファイル
- ストア.sqlDatabricks Git フォルダーまたは外部 Git プロバイダー (GitHub、Azure DevOps など) を使用する Git リポジトリ内のファイル。
- ブランチ (開発、ステージング、本番運用など) を使用して、環境固有の変更を管理します。
-
.sqlファイルをCI/CDパイプラインに統合して、デプロイを自動化します。- プルリクエスト中の構文とスキーマの変更を検証します。
.sqlファイルを Databricks SQL ワークフローまたはジョブにデプロイします。
-
環境分離のためのパラメーター化
-
.sqlファイル内の変数を使用して、データパスやテーブル名などの環境固有のリソースを動的に参照します。SQLCREATE OR REFRESH STREAMING TABLE ${env}_sales_ingest AS SELECT * FROM read_files('s3://${env}-sales-data')
-
-
更新のスケジュールと監視
- Databricks ジョブで SQL タスクを使用して、テーブルとマテリアライズドビュー (
REFRESH MATERIALIZED VIEW view_name) の更新をスケジュールします。 - システムテーブルを使用して更新履歴を監視します。
- Databricks ジョブで SQL タスクを使用して、テーブルとマテリアライズドビュー (
ワークフローは次のようになります。
- 開発:
.sqlスクリプトをローカルまたは Databricks SQL エディターで記述してテストし、Git ブランチにコミットします。 - 検証: プル要求中に、自動 CI チェックを使用して構文とスキーマの互換性を検証します。
- デプロイ: マージ時に、.sqlCI/CD パイプラインを使用してターゲット環境にスクリプト (GitHub Actions や Azure パイプラインなど)。
- 監視: Databricks ダッシュボードとアラートを使用して、クエリのパフォーマンスとデータの鮮度を追跡します。
ダッシュボード開発者向けの CI/CD
Databricks 、Declarative Automation Bundlesを使用したCI/CDワークフローへのダッシュボードの統合をサポートしています。 この機能により、ダッシュボード開発者は以下のことが可能になります。
- バージョン管理ダッシュボードにより、監査可能性を確保し、チーム間のコラボレーションを簡素化します。
- ダッシュボードのデプロイを、環境全体のジョブやパイプラインと一緒に自動化し、エンドツーエンドのアライメントを実現します。
- 手動エラーを減らし、更新が環境間で一貫して適用されるようにします。
- CI/CDベスト プラクティスを遵守しながら、高品質のアナリティクス ワークフローを維持します。
CI/CD のダッシュボードの場合:
-
databricks bundle generateコマンドを使用して、既存のダッシュボードをJSONファイルとしてエクスポートし、それをバンドルに含めるYAML設定を生成します。YAMLresources:
dashboards:
sales_dashboard:
display_name: 'Sales Dashboard'
file_path: ./dashboards/sales_dashboard.lvdash.json
warehouse_id: ${var.warehouse_id} -
これらの
.lvdash.jsonファイルを Git リポジトリに保存して、変更を追跡し、効果的に共同作業を行います。 -
databricks bundle deployを使用して、CI/CD パイプラインにダッシュボードを自動的にデプロイします。たとえば、デプロイメント用のGitHub Actionsステップは次のとおりです。YAMLname: Deploy Dashboard
run: databricks bundle deploy --target=prod
env:
DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }} -
${var.warehouse_id}などの変数を使用して、SQLウェアハウスやデータソースなどの設定をパラメーター化し、開発環境、ステージング環境、本番運用環境全体でシームレスにデプロイできるようにします。 -
bundle generate --watchオプションを使用して、Databricks UI で行われた変更とローカル ダッシュボードの JSON ファイルを継続的に同期します。不一致が発生した場合は、デプロイ中に--forceフラグを使用して、リモート ダッシュボードをローカル バージョンで上書きします。
バンドル内のダッシュボードに関する情報については、「 ダッシュボード リソース」を参照してください。 bundle コマンドの詳細については、「bundle コマンド グループ」を参照してください。