Databricksでの開発者向けベストプラクティス
このページでは、バージョン管理、環境管理、開発者ツール、マネージドデプロイメントを含む、データエンジニアリングと開発のライフサイクルに関するベストプラクティスを紹介します。
ソース管理
すべてのファイルをバージョン管理
宣言型オートメーションは、何かがバージョン管理下にない場合、それは存在しないという考えに基づいています。そのため、Databricks では、ほぼすべてのファイルをバージョン管理することをお勧めします。以下が含まれます:
- すべてのノートブックおよびソースファイル (
.py,.sql) - バンドル構成ファイル (
databricks.ymlおよび 環境固有のYAMLの上書き)
ただし、コミットしないでください:
.jarや.whlファイルなどのビルドアーティファクト代わりに、CI中にコンパイル済みバイナリをUnity Catalogボリュームにアップロードしてください。「JARをアップロード」を参照してください。- トークンまたは資格情報です。クラウドシークレットマネージャー(AWS Secrets ManagerやAzure Key Vaultなど)によってサポートされるワークスペースレベルのシークレット管理を使用し、値をDatabricksシークレットスコープに同期します。「 シークレットの管理」を参照してください。
- ローカルデータの例および個人情報を含むファイル。
.gitignoreを使用して、除外してください。
単一のリポジトリ
Databricks は、すべてのコード(ソースコードと設定ファイル)に単一のリポジトリを使用することを推奨します。そうすることで、コラボレーション、人間と AI の両方にとってのコードとベストプラクティスの共有が容易になります。個別のデプロイメントライフサイクル向けに複数のバンドルがある場合は、それらを単一のリポジトリに保持してください。
単一のリポジトリの推奨事項に対する唯一の例外は、機密保持を目的として複数のリポジトリが必要となる規制対象の業界です。
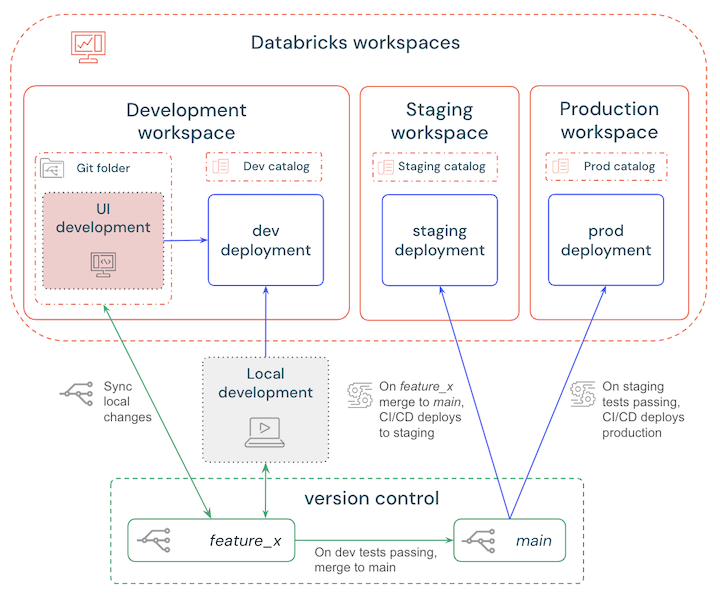
トランクベースブランチ戦略
マージの競合を最小限に抑え、メインブランチが常にデプロイ可能な状態であることを確保するため、トランクベースのブランチ戦略を使用してください。
シンプルなワークフローは次のとおりです。
- ローカルまたはワークスペースで開発し、変更をテストするためにDatabricks開発ワークスペースにデプロイしてください。
- 更新をバージョン管理し、ローカルまたはワークスペースの変更を定期的に同期するために、短期的なフィーチャーブランチを作成してください。
- テストが完了したら、フィーチャーブランチをメインブランチにマージしてください。
- CI/CD はメインブランチをステージングワークスペースに自動的にデプロイし、自動テストがトリガーされます。
- ステージングテストとチェックに合格した場合、CI/CD がメインブランチを本番運用ワークスペースにデプロイします。
次の図に、これらのステップの概要を示します。
ワークスペース設定
ワークスペース環境を分離する
デプロイ失敗の影響を最小限に抑えるために、ワークスペース環境を分離します。例えば:
- 小規模なチーム(5人までのデータエンジニア)の場合 は、単一のクラウドアカウントで2つのワークスペース(開発用と本番用)から始めます。
- 成長するチーム(データエンジニアが5人以上) :開発、ステージング、本番運用という3つのワークスペースに移行します。ステージングは、たとえ規模が縮小されていても、同じバンドル構成、スキーマ、および重要な統合を持つなど、本番運用と機能的に同等である必要があります。
- 規制対象業界 (銀行、医療、防衛):ワークスペースとクラウド アカウントを物理的に分離し、データ漏洩を防ぎます。単一のアカウント内でIAMとUnity Catalogの境界を介して隔離を管理することは可能ですが、セキュリティ体制の堅牢性は低くなります。
本番運用ワークスペースでは、可能な限りネットワークポリシーを適用したサーバレス コンピュートをご利用ください。それ以外の場合、厳密に制御されたエグレスおよびネットワークセキュリティコントロールを備えたプライベートサブネットまたはVNetを使用するように、クラウドアカウントを構成してください。
詳細については、「コンテキストベースのネットワーク ポリシー」を参照してください。
データストレージの分離
- 単一のUnity Catalogメタストアを使用し、ワークスペースのレイアウトを反映するように、開発、ステージング(該当する場合)、および本番運用向けに個別のカタログを作成してください。
- 個々の開発者向けの、開発およびステージング(本番運用ではない)カタログには、個人用スキーマを使用します。
ISOLATEDモードの本番運用カタログを本番運用ワークスペースにのみバインドします。カタログの分離モードをISOLATEDに設定すると、ID が誤って設定されていたとしても、本番運用データが開発環境やステージング環境からアクセスできないことを確実にします。- カタログレベルの分離では満たせない規制、データ主権、またはマルチリージョン要件を持つ組織にのみ、個別のメタストア、アカウント、またはリージョンを確保します。
テーブルと列のメタデータをコードとして扱う
テーブルと列のコメントは、コードの一部として見なしてください。それらをDeclarative Automation Bundlesの定義とともに.sqlファイルに保存し、正確なビジネス向け定義が常に利用できるように、メタデータジョブを介してデプロイしてください。列名を繰り返すのではなく、行が何を表すか、単位、および有効な値を平易な言葉で説明するコメントを記入します。
個人用スキーマの構成
開発中は、ユーザーごとに個人用スキーマを使用するようにバンドルを構成します。例えば dev_${user_name}。これにより、共有ワークスペースで開発者が互いのテーブルを上書きすることを防止します。
サーバレス コンピュートを活用
サーバレス コンピュートを使用すると、クラスター管理をシンプルにし、コストを最適化できます。「サーバレス コンピュートへの接続」を参照してください。
CI/CD の推奨事項
CI/CD向け宣言型オートメーションバンドル
Declarative Automation Bundles(旧称 Databricks Asset Bundles)は、Databricksエコシステム内でコード、ワークフロー、およびインフラストラクチャを管理するための強力かつ統一されたアプローチを提供し、CI/CDパイプラインに推奨されます。
CI/CD ワークフローにバンドルを使用することに関する詳細については、Databricks の CI/CD ワークフローを参照してください。
宣言型オートメーションバンドルに関する詳細については、宣言型オートメーションバンドルとは何ですか?を参照してください。
外部リソースにのみ Terraform を使用してください
Terraform を使用して、次のリソースを定義します:
- クラウドレベルおよび外部リソース
- 非特権ユーザーが実行すべきではない管理者アクション、例えばワークスペースのプロビジョニングやクラウドのネットワーキング構成など。
他のすべての Databricks リソースには、宣言型オートメーションバンドルをご使用ください。
バンドル管理
小型のバンドルを作成
Databricks は、単一の大きなバンドルよりも、小さく焦点を絞ったバンドルを開発することを推奨しています。
- 1つのチームが所有するすべてのものを1つのバンドルにまとめてください。
- 同じライフサイクルとリリースサイクルを共有する同じ CI/CD パイプラインを通して、テストおよびデプロイします。
- 各バンドルは、環境ごとに個別のバンドルを使用するのではなく、特定のプロジェクトのすべての環境(開発、ステージング、本番運用)をカバーする必要があります。
別々のバンドルを作成する対象:
- 異なる製品やドメイン(例えば、「請求アナリティクス」と「不正検出」)
- 異なる所有権または権限の境界
- 明確に異なるライフサイクルを持つワークロード
- 独立したプロモーションまたはロールバックが必要なケース
sync.paths を使用して共有フォルダを同期します。
複数のバンドルを1つのリポジトリで管理する場合、バンドルルート外の共有フォルダを同期するには、sync.pathsを使用します。これにより、異なるプロジェクトが../commonなどの共通のライブラリフォルダを共有しながら、個別のデプロイIDを維持できます。
CI/CDでバンドル間の依存関係をモデル化する
バンドルBがバンドルAによって公開されたアセットに依存する場合、両方を1つのバンドルにまとめるのではなく、その依存関係をCI/CDまたはオーケストレーションレイヤーでモデル化します。
- Bundle B の明示的な前提条件として、Bundle A のデプロイおよび公開ワークフローを設定します。Bundle A のデプロイが成功し、必要なすべての検証チェックがパスした後にのみ Bundle B が開始するように、パイプラインを構成してください。
- 公開済みアセットの識別子または場所をパイプライン入力として渡し、アップストリームアセットが見つからない場合は速やかに失敗します。これにより、バンドルBが部分的に公開された状態にデプロイされないことが保証されます。
バンドル共有の詳細については、バンドルとバンドルファイルの共有を参照してください。
カスタムバンドルテンプレート
カスタム宣言型オートメーションバンドルテンプレートを新しいプロジェクトのデフォルトの出発点として使用することで、すべてのプロジェクトが権限、タグ付け、クラスターポリシー、CI/CD構成、インスタンスベースラインといった同じガードレールを継承し、各チームがゼロから解決する必要がなくなります。
テンプレートは、ガバナンス、パフォーマンスのデフォルト、環境レイアウト、およびクォータ制限などの、共有され、長期間にわたる慣行をエンコードする必要があります。テンプレートには、アプリ固有のビジネスロジック、シークレット、または単発の構成を含めないでください。
チーム、プロジェクト、または環境によって変更される可能性のある入力のみをパラメーター化します。
- プロジェクト名またはアプリケーション名
- ターゲット ワークスペースの設定
- カタログまたはスキーマ名
- サービスプリンシパルの識別子
- スケジュールと通知設定
プラットフォームのガードレールと共有デフォルトはパラメータ化せず、テンプレートに固定します。
カスタムバンドルテンプレートおよびその作成方法に関する情報については、 「Declarative Automation Bundles プロジェクトテンプレート」を参照してください。
ロールバックとホットフィックスの計画
バンドルは、多くの関連性のないワークロード全体でロールバックを調整するのではなく、単一のバンドルでターゲットを絞ったロールバックを実行できるように、十分に小さく維持するようにしてください。
インシデント中:
- 影響を受けたバンドルを最終正常バージョンに元に戻すか、ロールバックします。
- ホットフィックスは、通常のプロモーションフローを待てない、緊急で適用範囲が限定された修正にのみ使用してください。
- 検証後すぐにホットフィックスをメインブランチにマージし、トランクが信頼できる唯一の情報源として維持されるようにしてください。
全般的な開発
サービスプリンシパルまたはOIDCを使用する
開発以外のすべての自動化にはサービスプリンシパルを使用します。これにより、自動化されたワークフローと個々のユーザーアカウントが切り離され、内部ユーザーの離職後もジョブが継続して実行されます。See サービスプリンシパル.
- デプロイ用とランタイム用に別々のサービスプリンシパルを使用してください。 バンドルデプロイメント専用のサービスプリンシパルは、最小限のデータアクセス権限を持つ必要があります。各本番運用ジョブまたはパイプラインは、そのワークロードが必要とするデータとリソースのみに限定された独自の実行主体サービスプリンシパルを持つ必要があります。この分離により、データアクセス権限をローテーションまたは厳格化する際にデプロイメントが安全に保たれ、インフラストラクチャの変更が本番運用データアクセスに結合されるのを防ぎます。
- 規制業界 : CI/CDにWorkload Identity Federation(OIDC)を使用します。これにより、GitHub Actions または Azure DevOps で有効期間の長いシークレットが不要になります。CI/CD でのワークロード ID フェデレーションの有効化を参照してください。
Databricks 開発者ツールの使用
Databricks ワークスペース UI で Git フォルダーを使用して開発するか、またはローカル IDE で開発できます。Visual Studio Code または互換性のあるフォークを使用している場合は、公式のDatabricks拡張機能をインストールしてください:
- Databricks に特化したエージェントスキル
- Unity Catalog とファイルシステムアクセス
- Databricks コンピュート上でワークロードを実行するリモート開発機能
詳細については、Visual Studio Code の Databricks 拡張機能を参照してください。
ノートブックでのビジネスロジックの最小化
ノートブックをビジネスロジックの主要なコンテナとして扱わないでください。これらは探索と可視化のみにご使用ください。
- Python :
src/またはsrc/py/にあるインポート可能な.pyモジュールに中核となるロジックを配置し、ノートブックからそれらの関数を呼び出す。 - SQL : ノートブックに SQL をインライン化するのではなく、
src/またはsrc/sql/の.sqlファイルにクエリを保持し、ジョブやパイプラインからそれらのファイルを参照してください。
基礎となるコードを呼び出す軽量なオーケストレーションおよび視覚化レイヤーとしてのみノートブックを使用してください。このアプローチにより、テストと再利用が容易になります。
ノートブックを多用するプロジェクトを移行する際は、段階的に行います。再利用可能なモジュールまたはSQLファイルを一度に1つずつ抽出し、宣言型オートメーションバンドルを使用して、移行されたアセットをプロジェクトの他の部分と同じデプロイおよびテストのワークフローに組み込んでください。
動的にコンテキストを渡す
タスクの依存関係には静的変数を避けてください。多段階ジョブ内のタスク間でランタイムコンテキストを渡すには、{{tasks.<task_key>.values.<value_key>}}のような動的値参照を使用します。
テストと可観測性
テストレイヤーの実装
バンドルが本番運用へと進む方法に合わせて、3段階のテストを使用します。
- 単体テスト: ビジネスロジックはインポート可能な
src/モジュールに実装し、pytestまたは同等のフレームワークで網羅してください。すべてのプルリクエストでこれらを実行して、失敗によってマージがブロックされるようにします。 - バンドルの検証 :
bundle validateをローカルで実行します。CIでは、非本番ワークスペースよりもbundle deployを優先し、本番運用デプロイの前にYAMLおよびリソースマッピングの問題を検出します。 - ステージング環境での統合テスト :デプロイ後、完了チェックや行数、スキーマの期待値などの重要なデータ品質アサーションを伴うエンドツーエンドのジョブを実行します。
「メインブランチとステージング環境での全てのテスト合格」を、アーティファクトを本番運用にプロモートするための条件とします。
For LakeFlow Pipelines、アドホックなノートブックのランではなく、組み込みの開発および検証機能を使用してください。エラーのあるレコードを含む小さく代表的なデータセットに対してパイプラインロジックをテストし、開発モードを使用して本番運用テーブルを更新する前に変更を検証してください。
ロギングをデプロイメントの一部として扱います
宣言型オートメーションバンドルにデプロイされたワークロードの場合、メトリクスとロギングは、各プロジェクトが個別に定義するものではなく、デプロイ契約の一部として見なしてください。
- ジョブ、パイプライン、タスク間で、一貫性のある構造化ログを出力します。バンドル名、ターゲット環境、ワークロード名、実行識別子、および障害を追跡するために必要なビジネス識別子を含めてください。
- すべての本番運用ワークロードについて、標準の運用メトリクスを追跡します:実行ステータス、期間、再試行回数、および該当する場合はスループットまたは鮮度インジケーター。
- これらの規則を共有ライブラリ、再利用可能なワークロード定義、またはバンドルテンプレートに組み込み、チームがプロジェクトごとに監視パターンを再作成する必要がないようにします。