パイプラインの初期化時間の長さを修正
パイプラインには、最新の状態に保つために、多数のフローを備えた多数のデータセットを含めることができます。パイプラインは更新とクラスターを自動的に管理し、効率的に更新します。ただし、多数のフローを管理するとオーバーヘッドが発生し、場合によっては、処理中に予想よりも大きな初期化や管理オーバーヘッドが発生する可能性があります。
初期化に 5 分以上かかるなど、トリガーされたパイプラインの初期化を待機して遅延が発生する場合は、データセットが同じソース データを使用している場合でも、処理を複数のパイプラインに分割することを検討してください。
トリガーされたパイプラインは、トリガーされるたびに初期化ステップを実行します。 連続パイプラインは停止時と再起動時にのみ初期化ステップを実行します。 このセクションは、トリガーされたパイプラインの初期化を最適化するのに最も役立ちます。
パイプラインの分割を検討するタイミング
パフォーマンス上の理由から、パイプラインを分割すると有利になるケースがいくつかあります。
INITIALIZINGフェーズとSETTING_UP_TABLESフェーズは必要以上に時間がかかり、全体的なパイプライン時間に影響を及ぼします。5 分を超える場合は、パイプラインを分割すると改善されることが多いです。- 単一のパイプライン内で多数 (30 ~ 40 以上) のストリーミング テーブルを実行する場合、クラスターを管理するドライバーがボトルネックになる可能性があります。 ドライバーが応答しない場合は、ストリーミング クエリの実行時間が増加し、更新の合計時間に影響します。
- 複数のストリーミング テーブル フローを持つトリガーされたパイプラインでは、並列化可能なすべてのストリーム更新を並行して実行できない場合があります。
パフォーマンスの問題の詳細
このセクションでは、単一のパイプラインに多数のテーブルとフローが存在する場合に発生する可能性のあるパフォーマンスの問題について説明します。
INITIALIZING フェーズと SETTING_UP_TABLES フェーズのボトルネック
パイプラインの複雑さによっては、実行の初期段階でパフォーマンスのボトルネックが発生する可能性があります。
初期化フェーズ
このフェーズでは、依存関係グラフを構築し、テーブルの更新順序を決定するためのプランを含む論理プランが作成されます。
SETTING_UP_TABLESフェーズ
このフェーズでは、前のフェーズで作成された計画に基づいて、次のプロセスが実行されます。
- パイプラインで定義されたすべてのテーブルのスキーマ検証と解決。
- 依存関係グラフを構築し、テーブル実行の順序を決定します。
- 各データセットがパイプラインでアクティブであるか、または以前の更新以降に新規であるかを確認します。
- 最初の更新でストリーミング テーブルを作成し、マテリアライズドビューの場合は、パイプラインの更新ごとに必要な一時ビューまたはバックアップ テーブルを作成します。
INITIALIZINGとSETTING_UP_TABLESに時間がかかる理由
多数のデータセットに対して多数のフローがある大規模なパイプラインでは、いくつかの理由により時間がかかることがあります。
- フローが多く、依存関係が複雑なパイプラインの場合、実行する作業量が多いため、これらのフェーズに時間がかかることがあります。
Auto CDC変換を含む複雑な変換では、定義された変換に基づいてテーブルを具体化するために必要な操作が原因で、パフォーマンスのボトルネックが発生する可能性があります。- また、フローが更新の一部ではない場合でも、多数のフローが速度低下を引き起こす可能性があるシナリオもあります。例として、700 を超えるフローがあり、そのうち 50 未満が構成に基づいてトリガーごとに更新されるパイプラインを考えます。この例では、各実行は 700 個のテーブルすべてのステップの一部を実行し、データフレームを取得して、実行するものを選択する必要があります。
ドライバーのボトルネック
ドライバーは実行中の更新を管理します。クラスター内のどのインスタンスが各フローを処理するかを決定するために、テーブルごとに何らかのロジックを実行する必要があります。単一のパイプライン内で複数 (30 ~ 40 以上) のストリーミング テーブルを実行する場合、ドライバーはクラスター全体で作業を処理するため、CPU リソースのボトルネックになる可能性があります。
ドライバーはメモリの問題を実行することもできます。 並列フローの数が 30 以上の場合には、この問題がより頻繁に発生する可能性があります。ドライバー メモリの問題を引き起こす可能性のあるフローの数やデータセットの数は特定されていませんが、並行して実行されているタスクの複雑さによって異なります。
ストリーミング フローは並列で実行できますが、そのためにはドライバーがすべてのストリームに対して同時にメモリと CPU を使用する必要があります。トリガーされたパイプラインでは、メモリと CPU の制約を回避するために、ドライバーはストリームのサブセットを一度に並列に処理する場合があります。
これらすべてのケースでは、パイプラインを分割して、それぞれに最適なフローのセットが存在するようにすると、初期化と処理時間を短縮できます。
パイプラインの分割によるトレードオフ
すべてのフローが同じパイプライン内にある場合、 Lakeflow Spark宣言型パイプラインが依存関係を管理します。 パイプラインが複数ある場合は、パイプライン間の依存関係を管理する必要があります。
-
依存関係 下流のパイプラインが (1 つではなく) 複数の上流のパイプラインに依存している場合があります。 たとえば、3 つのパイプライン
pipeline_A、pipeline_B、pipeline_Cがあり、pipeline_Cがpipeline_Aとpipeline_Bの両方に依存している場合は、pipeline_Aとpipeline_B両方がそれぞれの更新を完了した後にのみ、pipeline_C更新する必要があります。これを解決する 1 つの方法は、依存関係が適切にモデル化されたジョブ内のタスクとして各パイプラインを作成し、依存関係を調整して、pipeline_Cpipeline_Aとpipeline_B両方が完了した後にのみ更新されるようにすることです。 -
同時実行 パイプライン内に、完了するまでの時間が大きく異なる複数のフローが存在する場合があります。たとえば、
flow_A更新が 15 秒で完了し、flow_B更新に数分かかる場合などです。パイプラインを分割する前にクエリ時間を確認し、短いクエリをグループ化すると役立ちます。
パイプラインの分割を計画する
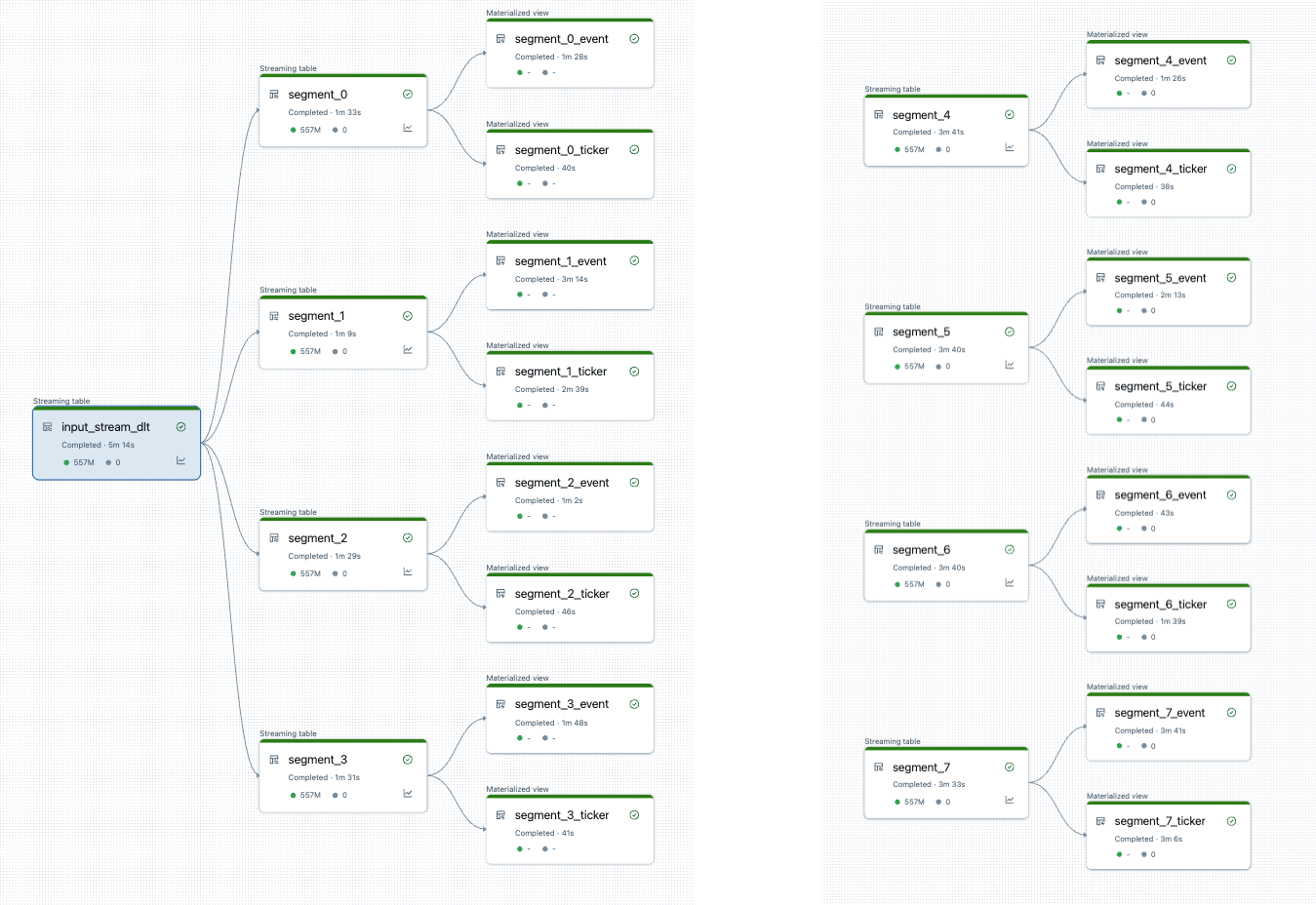
開始する前にパイプラインの分割を視覚化できます。以下は、25 個のテーブルを処理するソース パイプラインのグラフです。単一のルート データ ソースは 8 つのセグメントに分割され、各セグメントには 2 つのビューがあります。
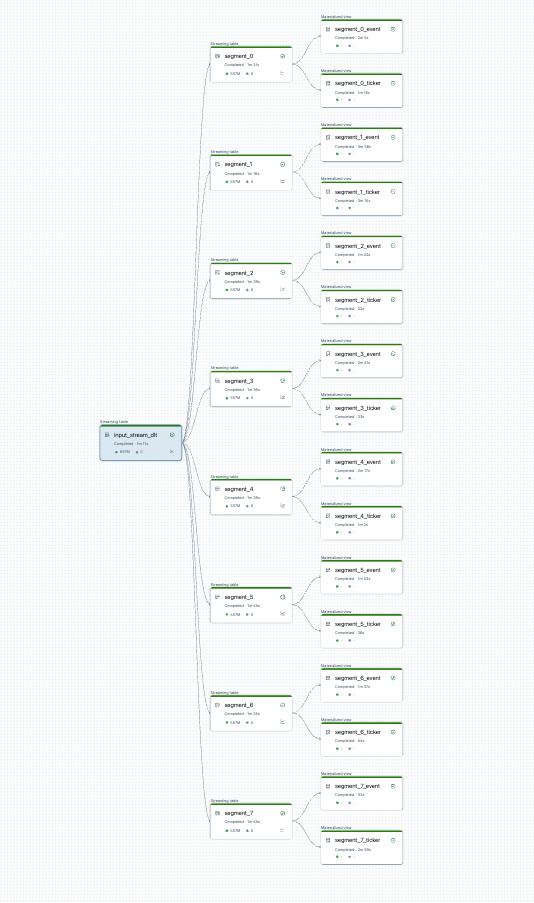
パイプラインを分割するとパイプラインは2本になります。 1 つは単一のルート データ ソースと、4 つのセグメントおよび関連ビューを処理します。2 番目のパイプラインは、他の 4 つのセグメントとそれに関連付けられたビューを処理します。2 番目のパイプラインは、最初のパイプラインを利用してルート データ ソースを更新します。
完全に更新せずにパイプラインを分割する
パイプラインの分割を計画した後、必要な新しいパイプラインを作成し、パイプライン間でテーブルを移動してパイプラインの負荷分散を行います。 完全な更新を行わずにテーブルを移動できます。
詳細については、 「パイプライン間でのテーブルの移動」を参照してください。
このアプローチにはいくつかの制限があります。
- パイプラインはUnity Catalogに存在する必要があります。
- ソース パイプラインと宛先パイプラインは同じワークスペース内にある必要があります。ワークスペース間の移動はサポートされていません。
- 移動前に、宛先パイプラインを作成して 1 回実行する必要があります (失敗した場合でも)。
- デフォルトの公開モードを使用するパイプラインから従来の公開モードを使用するパイプラインにテーブルを移動することはできません。詳細については、 「LIVE スキーマ (レガシー)」を参照してください。