Databricks Appsエージェントの負荷テスト
負荷テストでは、パフォーマンスが低下する前にDatabricks Appsエージェントが維持できる1秒あたりの最大クエリー数 (QPS) を特定します。このページでは、次の操作を行う方法を示します。
- インフラストラクチャのスループットをLLMのレイテンシーから分離するために、エージェントのモックバージョンをデプロイします。
- Locustを使用して、ランプトゥサチュレーション負荷テストを実行します。
- インタラクティブダッシュボードで結果を分析します。
AIを活用したパスをClaude Codeスキルを使用してたどることも、各ステップを手動でセットアップすることもできます。
要件
- Databricks Appsが有効化されたDatabricksワークスペース。
- OpenAI Agents SDK、LangGraph、またはカスタムフレームワークを使用してDatabricks Appsにデプロイされている(またはデプロイ準備が整っている)エージェントアプリ。AIエージェントを作成してDatabricks Appsにデプロイするを参照してください。
- Databricks CLI がインストールされ、認証されました。Databricks CLI のインストールまたは更新を参照してください。
uvパッケージマネージャーを搭載したPython 3.10 以降。- (AIアシストパスの場合) Claude Codeがインストールされています。
- (約1時間以上のロードテストの場合)M2M OAuth資格情報(
client_idおよびclient_secret)を持つサービスプリンシパル。「OAuthを使用したDatabricksへのサービスプリンシパル アクセスの承認」を参照してください。- 短いロードテスト (約1時間未満) の場合、
databricks auth loginからの既存のユーザー (U2M) OAuth 認証情報は問題なく機能します。より長いテストの場合は、Databricks サービスプリンシパルで M2M OAuth を使用してください。U2M トークンは長時間の実行中に期限切れになり、テストの中断を引き起こす可能性があります。Databricks サービスプリンシパルを作成するには、ワークスペース管理者アクセスが必要です。
- 短いロードテスト (約1時間未満) の場合、
AIアシストによるセットアップ(推奨)
Claude Code を使用する場合、/load-testing スキルはワークフローを自動化します。エージェントコードを読み込み、モックを生成し、ロードテストスクリプトを作成し、デプロイメントの手順を説明します。
「Claude Code」に実行を指示します。
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
または、以下のステップに従ってください。
ステップ 1: エージェントテンプレートのクローンを作成する
/load-testingスキルは、最上位のagent-load-testingスキルとして、また個々のすべてのエージェントテンプレートに事前に同期された状態で、databricks/app-templatesリポジトリに含まれています。app-templates からプロジェクトを既にお持ちであれば、そのスキルはあります。
ロードテストしたいエージェントのテンプレートディレクトリにリポジトリを複製し、移動します:
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
ステップ 2: ロードテストスキルを実行します。
Claude Codeで実行:
/load-testing
このスキルは、以下のステップをインタラクティブに案内します。実際の(本物の)エージェントをテストするためにモックをスキップできます。また、アプリがすでに実行中の場合はデプロイをスキップできます。
- パラメーターの収集 : デプロイ状況、コンピュートサイズ、ワーカー構成、およびOAuth資格情報について尋ねます。
- **ロードテストスクリプトの作成**:プロジェクトに合わせて調整された
locustfile.py、run_load_test.py、およびdashboard_template.pyを生成します。 - LLM のモック化 : SDK(OpenAI Agents SDK、LangGraph、またはカスタム)に特化したモッククライアントを作成し、実際のLLM呼び出しを構成可能なストリーミング遅延に置き換えます。
- テストアプリのデプロイ :異なるコンピュートサイズとワーカー数で複数のアプリ構成をデプロイする手順を説明します。
- テストの実行 :M2M OAuth認証とランプ・ツー・サチュレーションでロードテストを実行します。
- **結果の生成**: QPS、レイテンシ、失敗メトリクスを含むインタラクティブなHTMLダッシュボードを生成します。
手動セットアップ
AIアシスタンスなしでロードテストをセットアップおよび実行するには、次のステップに従ってください。
ステップ1:エージェントのLLM呼び出しをモックする(任意)
実際の LLM レイテンシーを含むエンドツーエンドの結果が必要な場合は、このステップをスキップします。Databricks Apps インフラストラクチャのスループットを単独で測定するには、LLM をモックして、LLM のリクエストごとのレイテンシー(通常 1~30 秒)がボトルネックにならないようにします。
モックは、構成可能なストリーミング遅延で定型応答を返し、完全なリクエスト/レスポンス パイプライン (SSE ストリーミング、ツール ディスパッチ、SDK ランナー) を維持し、LLM のみ置き換えます。これにより、Databricks Apps プラットフォームが提供できる最大 QPS が明らかになり、負荷テスト中の基盤モデル API トークン コストが回避されます。
モックのタイミングは2つの環境変数によって制御されます。
変数 | デフォルト | 説明 |
|---|---|---|
|
| ストリームされたテキストチャンク間のミリ秒単位の遅延 |
|
| 応答あたりのテキストチャンク数 |
デフォルトでは、各モック応答には約800ミリ秒(10ミリ秒 × 80チャンク)かかり、実際のLLM応答(3~15秒)よりもはるかに高速です。スループットの数値は、モデルではなくプラットフォームを反映します。
実際のLLMクライアントを置き換えるモッククライアントを作成します。エージェントコードの残りの部分は変更されず、アプローチはSDKによって異なります。OpenAIについては、databricks/app-templatesのmock_openai_client.pyのリファレンス実装を参照してください。同じパターンは他のSDKにも適用されます。
- OpenAI Agents SDK
- LangGraph
- Custom agents
agent_server/mock_openai_client.py を作成します — ストリーミングで chat.completions.create() を実装する MockAsyncOpenAI クラスです。ツール呼び出しのチャンクを即座に(LLM がツールを呼び出すことを決定するのをシミュレートして)返し、MOCK_CHUNK_DELAY_MS と MOCK_CHUNK_COUNT の環境変数から設定可能な遅延を伴うテキスト応答チャンクを返します。
エージェントにスワップ:
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
エージェントコードの残りの部分(ハンドラー、ツール、ストリーミングロジック)は変更されません。
ChatDatabricks モデルを、事前構築済みの AIMessage オブジェクトを返すモックに置き換えます。
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
モックは、最初の呼び出しでツール呼び出しを持つ AIMessage オブジェクトを返し、後続の呼び出しでテキストコンテンツを返す必要があります。設定可能なストリーミング遅延があります。
エージェントが行う外部 API 呼び出し(LLM、AI Search、ツール APIs)を、設定可能な遅延を伴う現実的な応答形式を返すモック実装でラップします。
ステップ2:負荷テスト スクリプトを設定する
プロジェクトにload-test-scripts/ディレクトリを作成します。ロードテストフレームワークは、フレームワークに依存せず、あらゆるDatabricks Appsエージェントと連携する3つのスクリプトで構成されています。
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
このフレームワークには、次のファイルが含まれています。
locustfile.py:stream: trueでPOST /invocationsリクエストを送信し、SSEストリームをパースし、最初のトークンまでの時間 (TTFT) をカスタムメトリクスとして追跡し、自動更新を伴うM2M OAuthトークン交換を使用し、各レベルをstep_duration秒間保持しながらユーザーをstep_sizeからmax_usersまで増加させるStepRampShapeを実装するLocust負荷テスト。run_load_test.py:各アプリURLを順次テストし、構成ごとに分離されたメトリクスを持つCLIオーケストレーター。OAuthトークンの更新を処理し、各テストの前にヘルスチェックとウォームアップを実行し、結果をload-test-runs/<run-name>/<label>/に保存します。dashboard_template.py:KPI カード、棒グラフ(QPS、レイテンシ、構成別の TTFT)、QPS ランプ進行折れ線グラフ、および完全な結果テーブルを備えた、Chart.js を使用した自己完結型の HTML ダッシュボードを生成します。スタンドアロンで実行できます:uv run dashboard_template.py ../load-test-runs/<run-name>/。
依存関係をインストールする
負荷テストスクリプトは、エージェントの本番運用の依存関係を汚染しないように、load-test-scripts/ 内で独自の pyproject.toml を使用します。load-test-scripts/pyproject.tomlを作成:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
locustを<2.40にピン留めします。新しいバージョン(>=2.43)には、長時間の負荷テストを中断させる既知のRecursionErrorがあります。
load-test-scripts/ディレクトリ内からインストールします:
cd load-test-scripts/
uv sync
ステップ 3: 異なる構成でテストアプリをデプロイする
複数のDatabricks Appsを異なるコンピュートサイズとワーカー数でデプロイして、ワークロードに最適な構成を見つけてください。
推奨テストマトリックス
以下の構成は、事前のテストから特定された最適な点に焦点を当てています。より広範なカバレッジが必要な場合は、いずれかの側に設定を 1 つ追加します (たとえば、medium-w1 または large-w12) が、通常は以下の 6 つで十分です。
コンピュートサイズ | ワーカー | 提案されたアプリ名 |
|---|---|---|
M | 2 |
|
M | 3 |
|
M | 4 |
|
Large | 6 |
|
Large | 8 |
|
Large | 10 |
|
コンピュート サイズを構成する
アプリの作成時または更新時に、Databricks CLI を使用してコンピュートサイズを設定します。
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
宣言型オートメーションバンドルでワーカー数を構成します。
start-server (AgentServer.run()経由で)--workersフラグを直接受け入れます。DAB 変数を使用して、command 配列でワーカー数を渡します:
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
デプロイして検証します
Databricks CLI を使用して各ターゲットをデプロイします:
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
負荷テストを実行する前に、アプリがアクティブであることを確認してください:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
すべてのアプリが「ACTIVE」ステータスになるまで待機してから、続行してください。まだ起動中のアプリは、誤解を招く結果を生成します。
ステップ 4: ロードテストを実行する
認証を設定する
実行する期間に応じて認証を選択してください:
- 短時間のテスト(約1時間未満) :
databricks auth loginの既存のユーザー認証情報を使用します。追加のセットアップは必要ありません。 - 長時間実行されるテスト(約1時間以上、夜間実行など) :Databricks サービスプリンシパルで M2M OAuth を使用します。U2M トークンは有効期限が切れ、テストの実行中に中断されます。Databricks サービスプリンシパルの作成には、ワークスペース管理者アクセスが必要です。
M2M OAuth の場合、テストを実行する前に Databricks サービスプリンシパルの資格情報をエクスポートしてください。
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
パラメーターリファレンス
パラメーター | 必須 | デフォルト | 説明 |
|---|---|---|---|
| はい | — | テストするアプリURL(繰り返し可能) |
| 長いテストの場合 |
| サービスプリンシパル クライアントID(M2M OAuth) |
| 長いテストの場合 |
| サービスプリンシパルクライアントシークレット (M2M OAuth) |
| No | URLから自動派生 | アプリごとの人間にとってわかりやすいラベル(繰り返し可能) |
| No | 自動検出されたか、 | アプリごとのコンピュートサイズタグ: |
| No |
| 最大並列シミュレートユーザー |
| No |
| ランプステップごとに追加されたユーザー |
| No |
| ランプステップあたりの秒数 |
| No |
| ユーザー生成率(ユーザー/秒) |
| No |
| この実行の名前 — 結果の保存先 |
| No | オフ | テスト完了後にインタラクティブなHTMLダッシュボードを生成します。 |
コマンドの例
クイックシングルアプリテスト(ショート実行 — databricks auth loginセッションを使用):
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
推奨される6つの構成すべてにわたるフルマトリックス(長時間実行―M2Mクレデンシャルを渡します)。--app-urlと同じ順序で--compute-size個のフラグを渡します:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
統計的な一貫性のための複数の実行:
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
実行中に何が起こるか
- **ヘルスチェック**:アプリが正しくストリームされることを確認します(
[DONE]を受信します)。 - ウォームアップ :アプリをウォームアップするためにシーケンシャルリクエストを送信します。
- ランプツーサチュレーション :並列ユーザーを
step_duration秒ごとにステップします。 - **飽和検出**:ユーザーを追加してもQPSが頭打ちになる場合、スループットの上限に達しています。
推定期間
テスト対象の各アプリは独自のランプを実行するため、合計実行時間はマトリックス内の構成数に比例します。以下の数式を使用して、実行ウィンドウを計画してください。
アプリあたりの期間: (max_users / step_size) * step_duration秒。
デフォルトで(--max-users 300 --step-size 20 --step-duration 30)
- 15 ステップ × 30 秒 = アプリあたり約 7.5 分
- 推奨される6構成マトリックスの場合:実行あたり約45分です。
ステップ 5: 結果の表示と解釈
-
ダッシュボードを開く:
Bashopen load-test-runs/<run-name>/dashboard.html -
(オプション) 既存のデータからダッシュボードを再生成します。たとえば、テンプレートを更新した後など。
Bashcd load-test-scripts/
uv run dashboard_template.py ../load-test-runs/<run-name>/
ダッシュボードセクション
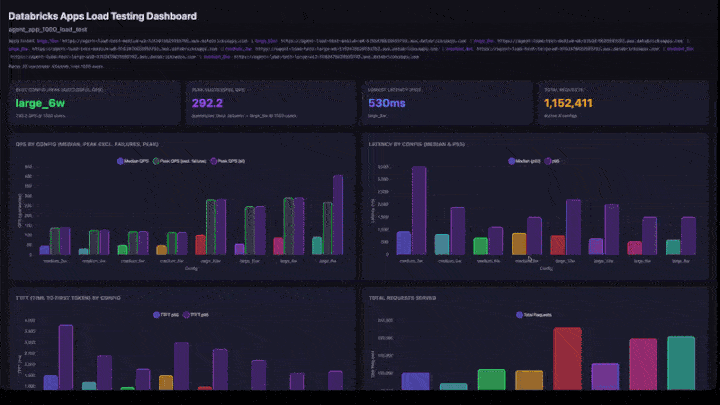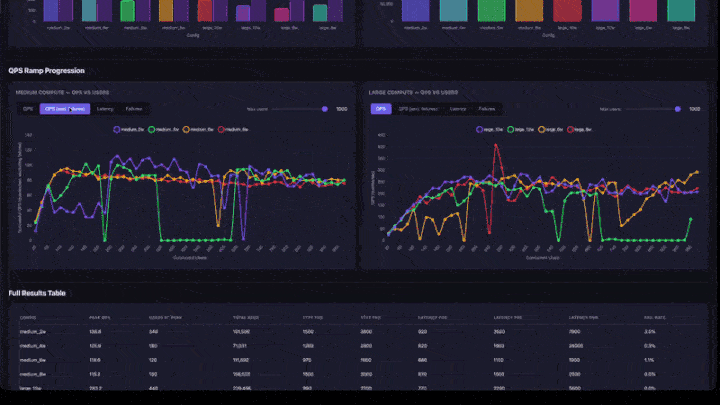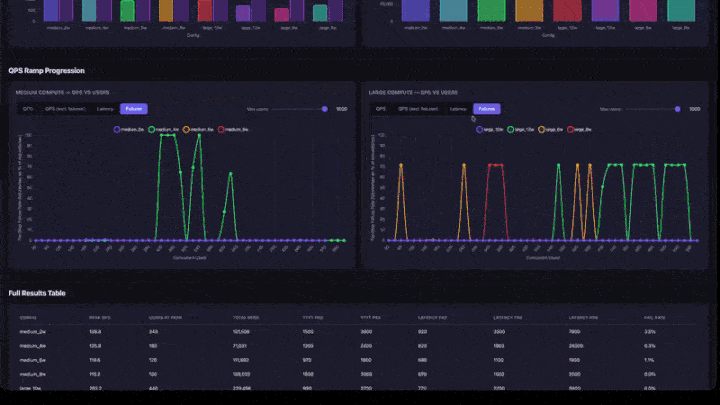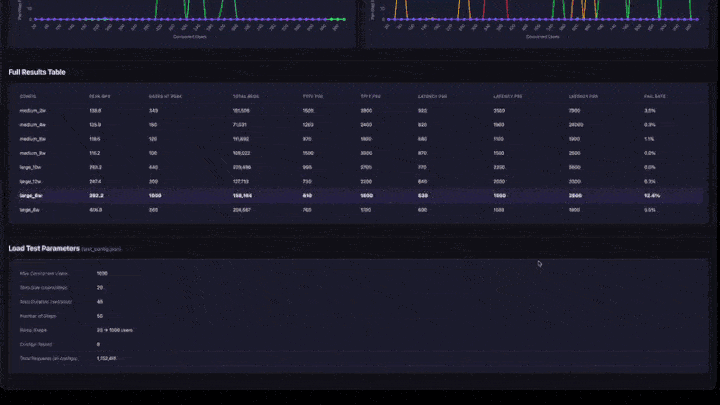
インタラクティブなダッシュボードには、以下が含まれます。
- **KPI カード**: 最適な構成(ピーク時の成功 QPS 別)、全体的なピーク QPS、最低遅延、および処理された合計リクエスト数。
- 構成別のQPS : 各構成の中央値QPS、障害を除くピークQPS、および並列ピークQPSを示すグループ化された棒グラフ。
- 設定別レイテンシー :p50とp95のレイテンシーを示すグループ化されたバー。
- 構成別のTTFT :最初のトークンまでの時間(p50およびp95)。
- **処理された合計リクエスト数**:設定ごとのリクエスト数。
- QPSランプ進行 : QPS、QPS (失敗を除く)、レイテンシー、および失敗のタブがある折れ線グラフ。下位の同時実行範囲にズームインするための最大ユーザー数スライダーが含まれます。チャートはコンピュートサイズ (中および大を並べて) でグループ化されます。
- 完全な結果テーブル :ピーク QPS、ピーク時のユーザー数、レイテンシーのパーセンタイル、および障害率を含むすべての構成。
- テストパラメーター :再現性のための構成の概要。
結果を解釈する方法
- ピーク QPS :任意のランプステップで達成される最大 QPS。これはその構成のスループット上限です。
- ピーク時のユーザー数 :ピークQPSが達成されたときの並列ユーザー数。この時点を超えてユーザーを追加しても、スループットは増加しません。
- 失敗率 : 0%または非常に低い値であるべきです。高い失敗率は、その並行レベルでアプリが過負荷状態であることを意味します。
- QPS ランプチャート :線が平坦になる場所を探します。それが飽和点です。ユーザーを増やしてもスループットは向上しません。
トラブルシューティング
問題 | ソリューション |
|---|---|
テスト中に認証トークンの有効期限が切れました。 | 1時間を超えるテストの場合は、 |
ヘルスチェックが失敗しました。 | アプリがアクティブであることを確認してください: |
0 QPS または結果なし |
|
高いユーザー数にもかかわらず低いQPS | アプリは飽和状態です。より多くのワーカーまたはより大きなコンピュートを試してください。 |
高い失敗率 | アプリが過負荷になっています。 |
ダッシュボードにランプデータはありません。 | 各結果サブディレクトリに |
その他のリソース
- 実際のLLM呼び出しでテストする : モック手順をスキップし、実際のLLM応答時間を含むエンドツーエンドのレイテンシーを測定するために、実際のモデルをデプロイします。
- **ワーカー数を調整する**:テストマトリックスの結果を使用して、コンピュートサイズに最適なワーカー数を見つけます。
- スループットとともに精度、関連性、安全性を測定するためのチュートリアル: 生成AIアプリケーションを評価して改善する。
- AI Gateway を含む完全な本番運用対応シーケンスについては、Databricks Apps エージェントを本番運用化するを参照してください。