チュートリアル: 取得エージェントをビルド、評価、デプロイする
このチュートリアルでは、取得とツールを併用する AI エージェントを構築する手順を説明します。
これは、エージェントの構築の基本にある程度精通していることを示す中級レベルのチュートリアルです。 Databricks。 エージェントの構築に不慣れな場合は、「 AI エージェントの使用を開始する」を参照してください。
サンプル ノートブックには、チュートリアルで使用されるすべてのコードが含まれています。
このチュートリアルでは、生成AI アプリケーションの構築に関する主要な課題について説明します。
-
ツールの作成やエージェント実行のデバッグなどの一般的なタスクの開発エクスペリエンスを効率化します。
-
次のような運用上の課題:
- 追跡エージェントの構成
- 予測可能な方法で入力と出力を定義する
- 依存関係のバージョンの管理
- バージョン管理とデプロイ
-
エージェントの品質と信頼性を測定し、改善します。
わかりやすくするために、このチュートリアルではチャンキングされたDatabricksドキュンメントを含むデータセットに対するキーワード検索を可能にするために、インメモリのアプローチを採用します。
ノートブックの例
このスタンドアロンノートブックは、サンプルドキュメントコーパスを使用してMosaic AIエージェントをすばやく操作できるように設計されています。セットアップやデータを必要とせずに実行する準備ができています。
Mosaic AIエージェントのデモ
エージェントとツールの作成
Mosaic AI Agent Framework は、さまざまなオーサリング フレームワークをサポートしています。この例では、LangGraph を使用して概念を示していますが、これは LangGraph のチュートリアルではありません。
サポートされている他のフレームワークの例については、 「 AIエージェントを作成してDatabricks Appsにデプロイする」を参照してください。
最初のステップは、エージェントを作成することです。LLM クライアントとツールのリストを指定する必要があります。databricks-langchain Python パッケージには、DatabricksのLLMとUnity Catalogに登録されたツールの両方に対応する LangChain および LangGraph 互換クライアントが含まれています。
エンドポイントは、関数を呼び出す基盤モデル API または AI Gateway を使用する外部モデルである必要があります。 サポートされているモデルを参照してください。
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
次のコードは、モデルといくつかのツールからエージェントを作成する関数を定義していますが、このエージェント コードの内部については、このページの範囲外です。詳細については 情報 LangGraph エージェントを構築する方法については、 LangGraph のドキュメントを参照してください。
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
エージェントツールの定義
ツールは、エージェントを構築するための基本的な概念です。これらは、LLMを人間が定義したコードと統合する機能を提供します。プロンプトとツールの一覧が提供されると、ツールを呼び出す LLM はツールを呼び出すための引数を生成します。ツールと Mosaic AI エージェントでの使用の詳細については、「AIエージェント ツール」を参照してください。
最初のステップは、 TF-IDFに基づくキーワード抽出ツールを作成することです。この例では、scikit-learn と Unity Catalog ツールを使用します。
databricks-langchain パッケージは、Unity Catalog ツールを操作するための便利な方法を提供します。次のコードは、キーワード抽出ツールを実装して登録する方法を示しています。
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(uc_client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function's metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
上記のコードの説明を次に示します。
- Databricks ワークスペース内の Unity Catalog を "レジストリ" として使用して、ツールを作成および検出するクライアントを作成します。
- TF-IDF キーワード抽出を実行する Python 関数を定義します。
- Python関数をUnity Catalog関数として登録する
このワークフローは、いくつかの一般的な問題を解決します。これで、Unity Catalog の他のオブジェクトと同様に管理できるツールの中央レジストリができました。たとえば、企業が内部収益率を計算する標準的な方法を持っている場合、それを Unity Catalog の関数として定義し、 FinancialAnalyst ロールを持つすべてのユーザーまたはエージェントにアクセス権を付与できます。
このツールをLangChainエージェントで使用できるようにするには、 UCFunctionToolkit を使用して、LLMに選択用に渡すツールのコレクションを作成します。
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
次のコードは、ツールをテストする方法を示しています。
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
次のコードは、キーワード抽出ツールを使用するエージェントを作成します。
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
結果のトレースでは、LLM がツールを選択したことがわかります。
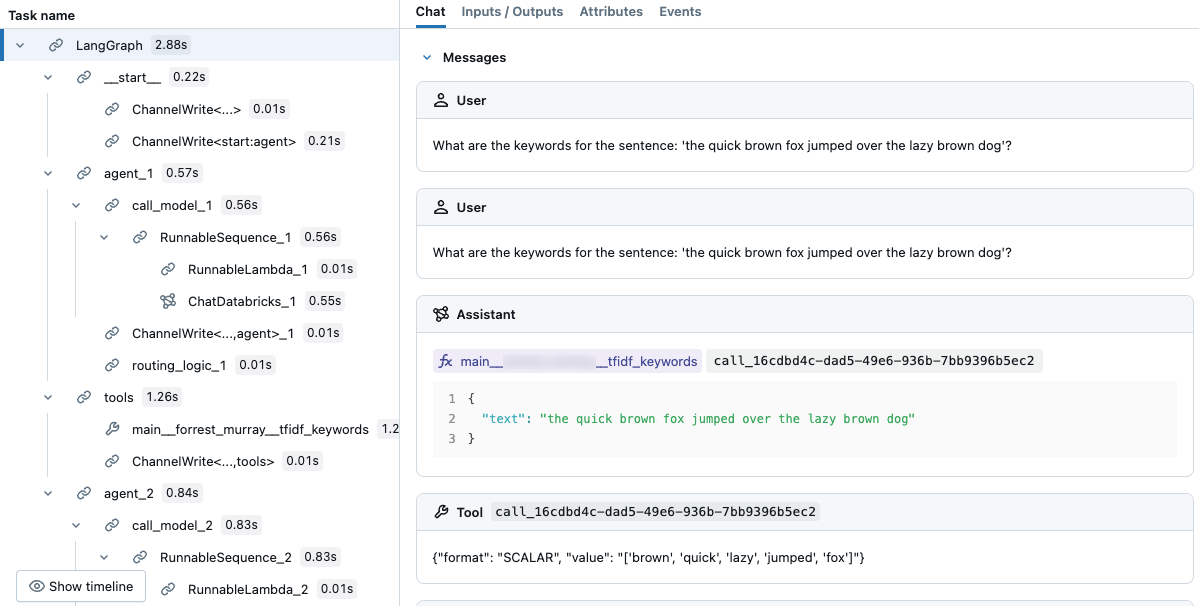
トレースを使用してエージェントをデバッグする
MLflow Tracing は、 デバッグ エージェントを含むアプリケーションAI 生成を観察します。 特定のコードセグメントをカプセル化し、入力、出力、タイミングデータを記録するスパンを通じて詳細な操作情報をキャプチャします。
LangChain などの一般的なライブラリの場合は、 mlflow.langchain.autolog().mlflow.start_span() を使用してトレースをカスタマイズすることもできます。たとえば、カスタムデータ値フィールドや可観測性のためのラベル付けを追加できます。そのスパンのコンテキストで実行されるコードは、定義したフィールドに関連付けられます。このインメモリ TF-IDF の例では、名前とスパン タイプを指定します。
トレースの詳細については、 MLflow Tracing - GenAI の可観測性」を参照してください。
次の例では、単純なインメモリ TF-IDF インデックスを使用して取得ツールを作成します。これは、ツール実行の自動ロギングと、追加の可観測性のためのカスタムスパントレースの両方を示しています。
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
このコードでは、取得ツール用に予約されている特殊な span タイプ RETRIEVERを使用します。その他の Mosaic AI エージェント機能 ( AI Playground、レビュー UI、評価など) では、RETRIEVER スパン タイプを使用して取得結果を表示します。
Retriever ツールでは、ダウンストリームの Databricks 機能との互換性を確保するためにスキーマを指定する必要があります。mlflow.models.set_retriever_schemaの詳細については、 「カスタム取得スキーマ」を参照してください。
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
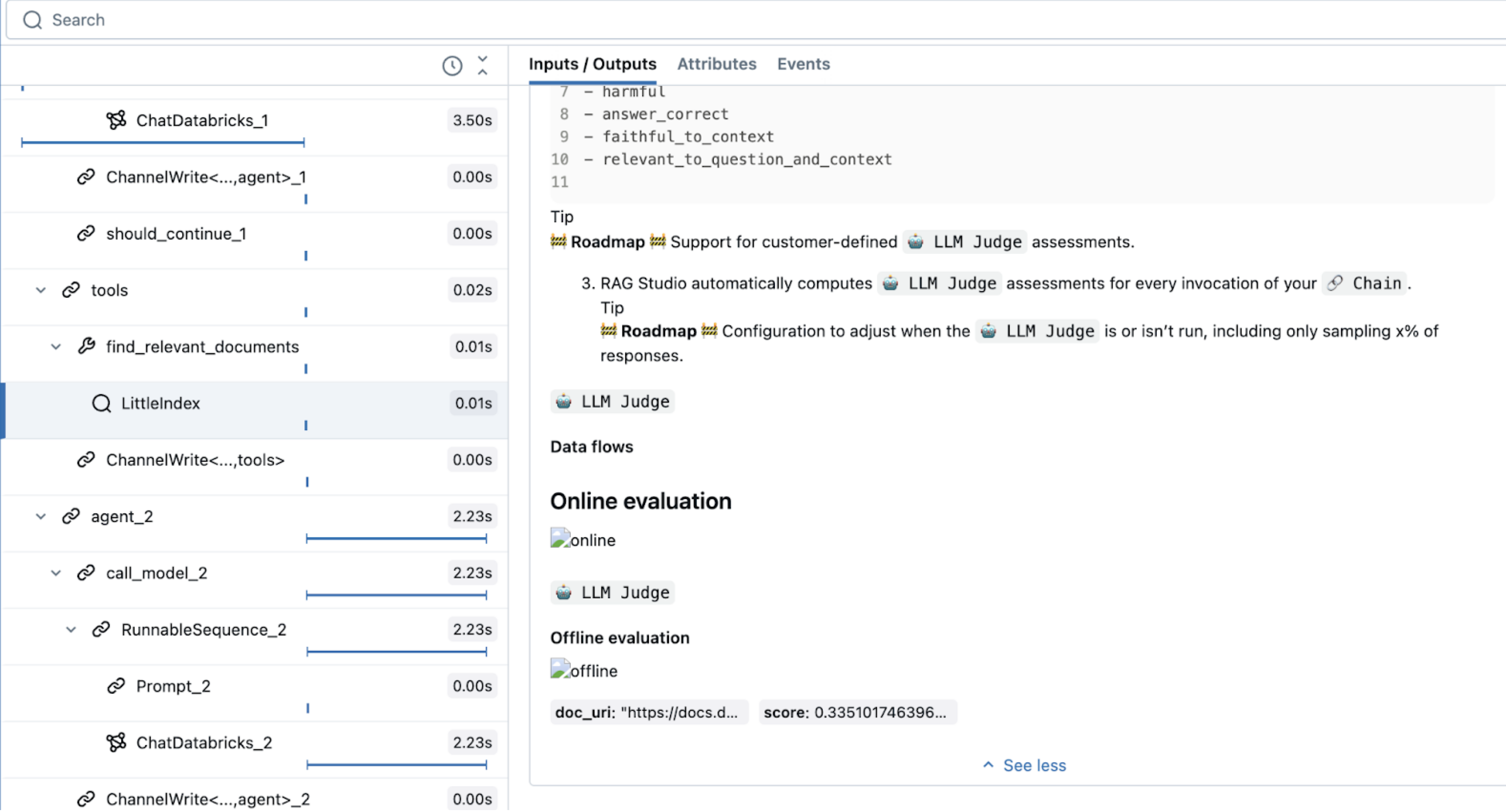
エージェントの定義
次の手順では、エージェントを評価し、デプロイの準備をします。大まかに言うと、これには次のものが含まれます。
- 署名を使用して、エージェントの予測可能な API を定義します。
- モデル構成を追加すると、パラメーターの構成が容易になります。
- モデルに再現可能な環境を提供する依存関係をログに記録し、他のサービスに対する認証を構成できるようにします。
MLflow ChatAgent インターフェイスを使用すると、エージェントの入力と出力の定義が簡略化されます。これを使用するには、エージェントを ChatAgentのサブクラスとして定義し、 predict 関数を使用して非ストリーミング推論を実装し、 predict_stream 関数を使用してストリーミング推論を実装します。
ChatAgent は、エージェントオーサリングフレームワークの選択にとらわれず、さまざまなフレームワークやエージェントの実装を簡単にテストして使用できます。唯一の要件は、 predict インターフェイスと predict_stream インターフェイスを実装することです。
ChatAgentを使用してエージェントを作成すると、次のような多くの利点があります。
- ストリーミング出力のサポート
- 包括的なツール呼び出しメッセージ履歴 : 中間ツール呼び出しメッセージを含む複数のメッセージを返し、品質と会話管理を向上させます。
- マルチエージェントシステムのサポート
- Databricks機能の統合: AI Playground、Agent Evaluation、および Agent モニタリングとの簡単に利用できる互換性があります。
- 型付きオーサリングインターフェイス :型付きPythonクラスを使用してエージェントコードを記述し、IDEとノートブックのオートコンプリートの恩恵を受けます。
ChatAgent作成に関する詳細については、「レガシー入力および出力エージェント スキーマ (モデルサービング)」を参照してください。
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
次のコードは、 ChatAgent.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What are Pipelines in Databricks?"},
]
}
)
パラメーターを使用したエージェントの構成
Agent Framework では、パラメーターを使用してエージェントの実行を制御できます。つまり、LLMエンドポイントの切り替えや、基盤となるコードを変更することなく別のツールを試すなど、さまざまなエージェント構成をすばやくテストできます。
次のコードは、モデルの初期化時にエージェント パラメーターを設定する構成ディクショナリを作成します。
エージェントのパラメーター化の詳細については、「 環境間でデプロイするためのコードのパラメーター化」を参照してください。
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-3-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
エージェントのログを記録する
エージェントを定義したら、ログに記録する準備が整いました。MLflow では、エージェントのログ記録とは、評価とデプロイに使用できるように、エージェントの構成 (依存関係を含む) を保存することを意味します。
ノートブックでエージェントを開発する場合、MLflow はノートブック環境からエージェントの依存関係を推測します。
ノートブックからエージェントをログに記録するには、モデルを定義するすべてのコードを 1 つのセルに記述し、 %%writefile マジック コマンドを使用してエージェントの定義をファイルに保存します。
%%writefile agent.py
...
<Code that defines the agent>
エージェントがキーワード抽出ツールを実行するために Unity Catalog などの外部リソースにアクセスする必要がある場合は、エージェントがデプロイされたときにリソースにアクセスできるように、エージェントの認証を構成する必要があります。
Databricks リソースの認証を簡略化するには、 自動認証パススルーを有効にします。
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
ログエージェントの詳細については、「 コードベースのログ記録」を参照してください。
エージェントの評価
次のステップは、エージェントを評価して、そのパフォーマンスを確認することです。エージェント評価は困難であり、次のような多くの疑問が提起されます。
-
品質を評価するための適切なメトリクスは何ですか? これらのメトリクスの出力を信頼するにはどうすればよいですか?
-
多くのアイデアを評価する必要があります - どうすればいいですか...
- 評価を迅速に実行して、ほとんどの時間を待ち時間に費やさないようにしますか?
- これらの異なるバージョンのエージェントを、品質、コスト、レイテンシーについてすばやく比較しますか?
-
品質問題の根本原因を迅速に特定するにはどうすればよいですか?
データサイエンティストや開発者として、あなたは実際の対象分野の専門家ではないかもしれません。 このセクションの残りの部分では、適切な出力を定義するのに役立つエージェント評価ツールについて説明します。
評価セットの作成
エージェントにとっての品質の意味を定義するには、メトリクスを使用して、評価セットでのエージェントのパフォーマンスを測定します。「品質」の定義: 評価セットを参照してください。
エージェント評価では、合成評価セットを作成し、評価を実行して品質を測定できます。アイデアは、一連の文書のように事実から始めて、それらの事実を使用して一連の質問を生成することで「逆算」することです。生成される質問は、いくつかのガイドラインを指定することで条件付けできます。
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
生成される評価には、次のものが含まれます。
-
前述の
ChatAgentRequestのような要求フィールド:Python{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]} -
"取得される予定のコンテンツ" のリスト。レトリーバースキーマは、
contentフィールドとdoc_uriフィールドで定義されました。Python[{"content":"If your workspace's [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}] -
予想される事実のリスト。2つの回答を比較すると、小さな違いを見つけるのが難しい場合があります。期待される事実は、正解と部分的に正解、そして不正解を分けるものを抽出し、AIジャッジの質とエージェントで働く人々の経験の両方を向上させます。
Python["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."] -
ここで
SYNTHETIC_FROM_DOCであるソース フィールド。 より完全な評価セットを構築すると、サンプルはさまざまなソースから取得されるため、このフィールドによって区別されます。
評価セットの作成の詳細については、「 評価セットの合成」を参照してください。
LLMジャッジを使用したエージェントの評価
非常に多くの生成された例でエージェントのパフォーマンスを手動で評価することは、うまく拡張できません。大規模には、LLM をジャッジとして使用することがはるかに合理的なソリューションです。 エージェント評価の使用時に使用できる組み込みのジャッジを使用するには、次のコードを使用します。
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
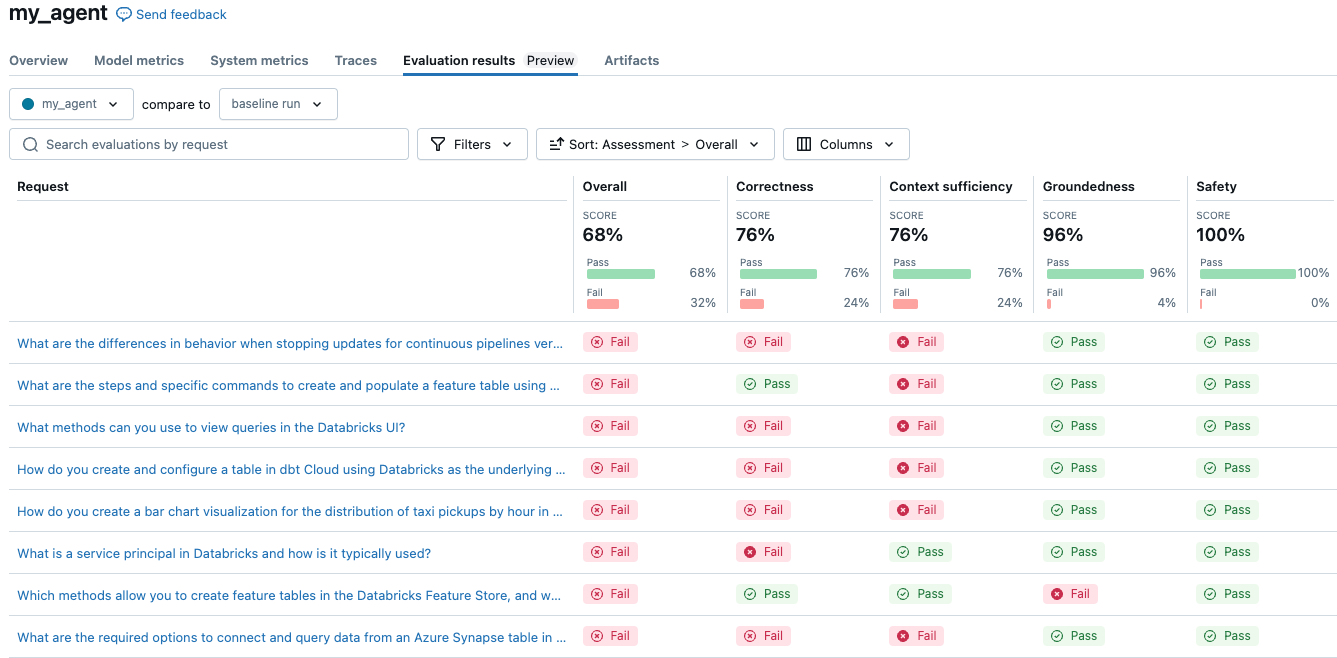
シンプルなエージェントのスコアは全体で68%でした。ここでの結果は、使用する構成によって異なる場合があります。エクスペリメントを実行して、3つの異なるLLMのコストと品質を比較するのは、構成を変更して再評価するのと同じくらい簡単です。
モデル構成を変更して、別の LLM、システム プロンプト、または温度設定を使用することを検討してください。
これらのジャッジは、人間の専門家が応答を評価するために使用するのと同じガイドラインに従うようにカスタマイズできます。LLMjudgesに関する詳細情報については、組み込みAIjudges(MLflow 2)を参照してください。
エージェント評価では、 カスタムメトリクスを使用して特定のエージェントの品質を測定する方法をカスタマイズできます。評価は統合テストのように考え、個々のメトリクスは単体テストと考えることができます。次の例では、 Boolean メトリクスを使用して、エージェントが特定のリクエストに対してキーワード抽出と取得者の両方を使用したかどうかを確認します。
from databricks.agents.evals import metric
@metric
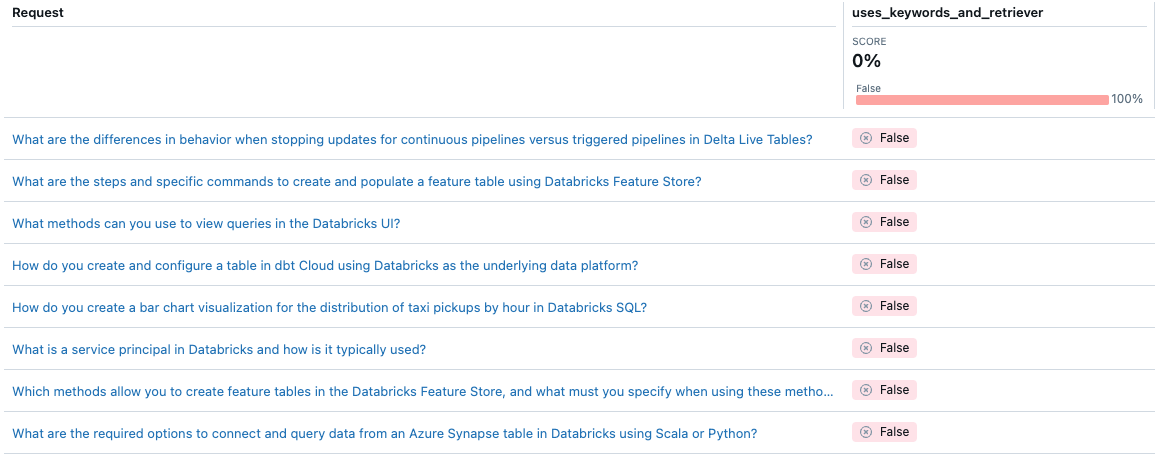
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
エージェントはキーワード抽出を使用しないことに注意してください。この問題を解決するにはどうすればよいですか?
エージェントのデプロイと監視
実際のユーザーでエージェントのテストを開始する準備ができたら、Agent Framework は、 Mosaic AI Model Servingでエージェントにサービスを提供するための本番運用可能なソリューションを提供します。
エージェントをモデルサービングにデプロイすると、次の利点があります。
- モデルサービングは、オートスケール、ロギング、バージョン管理、アクセス制御を管理し、高品質なエージェントの開発に集中することができます。
- 対象分野の専門家は、レビューアプリを使用してエージェントと対話し、モニタリングと評価に組み込むことができるフィードバックを提供できます。
- ライブトラフィックの評価を実行することで、エージェントを監視できます。ユーザートラフィックにはグラウンドトゥルースは含まれませんが、LLM ジャッジ (および作成したカスタムメトリクス) は教師なし評価を実行します。
次のコードは、エージェントをサービスエンドポイントにデプロイします。詳細については、 「生成AIアプリケーション用のエージェントのデプロイ (モデルサービング)」を参照してください。
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)