高レベルのアーキテクチャ
この記事では、エンタープライズ アーキテクチャを含む Databricks アーキテクチャの概要を Google クラウドと組み合わせて説明します。
Databricksオブジェクト
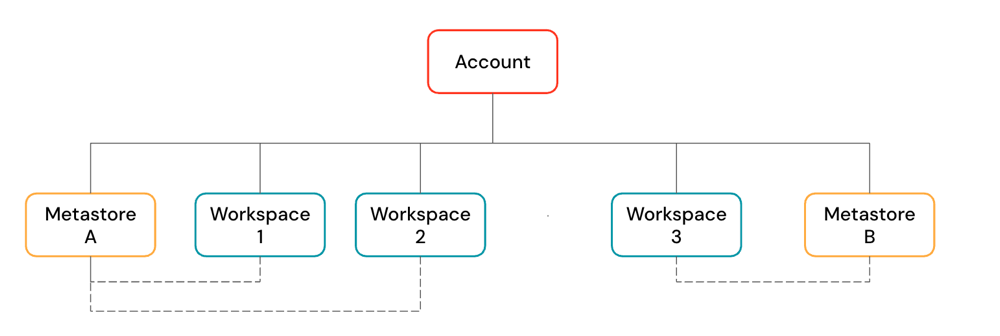
Databricks アカウントは 、組織全体で Databricks を管理するために使用する最上位レベルの構成要素です。アカウント レベルでは、次のものを管理します。
-
ID とアクセス: ユーザー、グループ、サービスプリンシパル、 SCIMプロビジョニング、およびSSO構成。
-
ワークスペース管理: 複数のリージョンにわたるワークスペースを作成、更新、削除します。
-
Unity Catalogメタストア管理: メタストアを作成してワークスペースにアタッチします。
-
使用状況管理: 課金、コンプライアンス、ポリシー。
アカウントには複数のワークスペースと Unity Catalog メタストアを含めることができます。
-
ワークスペース は、ユーザーが取り込み、インタラクティブな探索、スケジュールされたジョブ、 MLトレーニングなどのワークロードを実行できるコラボレーション環境です。
-
Unity Catalog メタストアは、 テーブルや ML モデルなどのデータ資産の中心的なガバナンス システムです。メタストア内のデータは、次の 3 レベルの名前空間で整理されます。
<catalog-name>.<schema-name>.<object-name>
メタストアはワークスペースにアタッチされます。1 つのメタストアを同じリージョン内の複数のDatabricksワークスペースにリンクし、各ワークスペースに同じデータ ビューを与えることができます。 データ アクセス制御は、リンクされたすべてのワークスペースにわたって管理できます。
ワークスペースアーキテクチャ
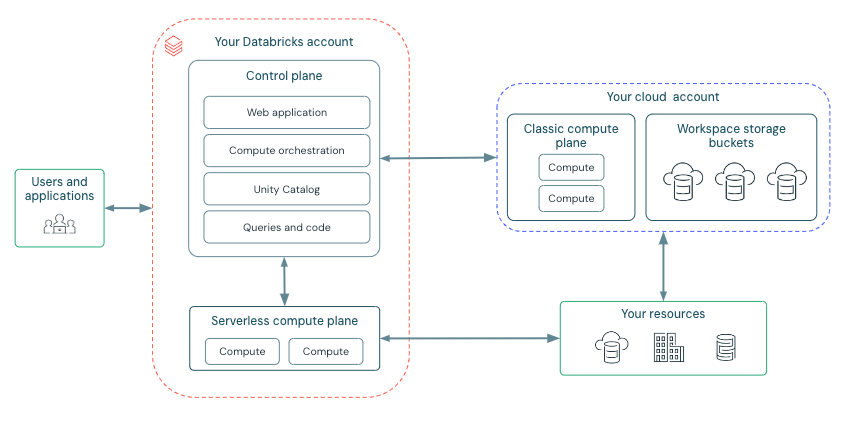
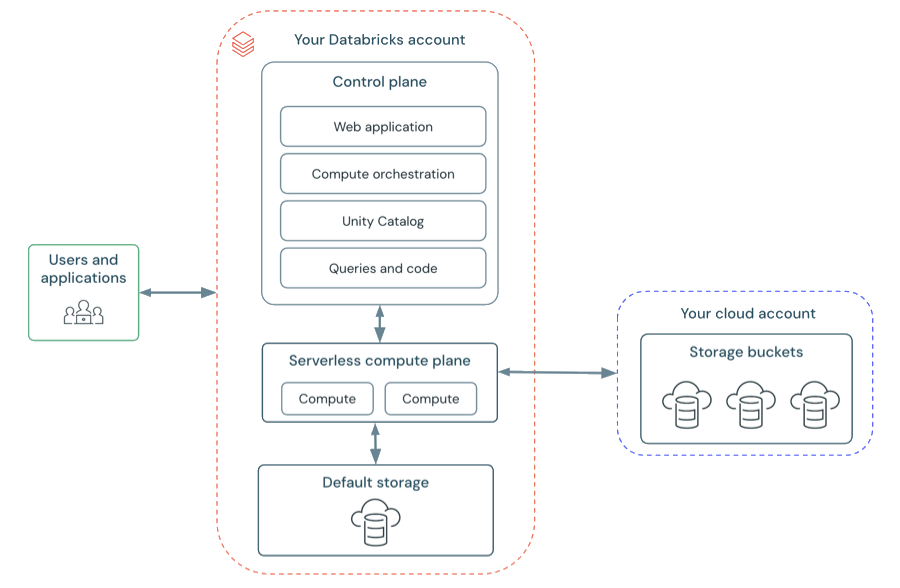
Databricks は、 コントロールプレーン と コンピュートプレーン から動作します。
-
コントロール プレーンに は、Databricks アカウントで Databricks が管理するバックエンド サービスが含まれます。コントロール プレーンは、クラウド アカウントではなく、Databricks アカウントにあります。Web アプリケーションはコントロール プレーンにあります。
-
コンピュートプレーン は、データが処理される場所です。 使用するコンピュートに応じた2 種類のコンピュートプレーンが存在します。
- サーバレスコンピュートの場合、サーバレスコンピュートリソースはDatabricksアカウントの サーバレスコンピュートプレーン で実行されます。
- クラシック Databricks コンピュートの場合、コンピュート リソースは Google Cloud リソース内の クラシック コンピュートプレーン 内にあります。 これは、Google Cloud リソースとそのリソース内のネットワークを指します。
classic コンピュートとサーバレス コンピュートの詳細については、「 コンピュート」を参照してください。
クラシックなワークスペースアーキテクチャ
Classic Databricksワークスペースには 、ワークスペース ストレージ バケット と呼ばれる 3 つの関連ストレージ バケットがあります。 ワークスペース ストレージ バケットは、Google クラウド アカウント内にあります。
次の図は、クラシック ワークスペースの一般的な Databricks アーキテクチャを示しています。
サーバレスワークスペースアーキテクチャ
サーバレスワークスペースのワークスペースストレージは、ワークスペースのデフォルトストレージに保存されます。 クラウド ストレージ アカウントに接続してデータにアクセスすることもできます。次の図は、サーバレス ワークスペースの一般的なアーキテクチャを示しています。
サーバレス コンピュート プレーン
サーバレス コンピュート プレーンで、Databricks アカウント内のコンピュート レイヤーでコンピュート リソースDatabricks実行します。Databricks は、ワークスペースの従来のコンピュートプレーンと同じ Google Cloud リージョンにサーバレス コンピュートプレーンを作成します。 このリージョンは、ワークスペースの作成時に選択します。
サーバーレスコンピュートプレーン内の顧客データを保護するために、サーバーレスコンピュートはワークスペースのネットワーク境界内で実行され、さまざまなセキュリティレイヤーを使用して、同じ顧客のクラスター間で異なるDatabricksワークスペースと追加のネットワーク制御を分離します。
サーバレス コンピュート プレーンでのネットワークの詳細については、 サーバレス コンピュート プレーン ネットワークを参照してください。
クラシックコンピュートプレーン
従来のコンピュートプレーンでは、Google Cloud アカウントでDatabricksコンピュート リソースを実行 します。 新しいコンピュート リソースは、各ワークスペースの仮想ネットワーク内の顧客の Google Cloud アカウント内に作成されます。
従来のコンピュートプレーンは、各顧客自身のGoogle Cloudアカウントで実行されるため、自然に分離されています。 クラシック コンピュート プレーンでのネットワークの詳細については、「 クラシック コンピュート プレーン ネットワーク」を参照してください。
リージョンのサポートについては、「 Databricks のクラウドとリージョン」を参照してください。
ワークスペースストレージ
ワークスペースのストレージは、ワークスペースのタイプに応じて処理されます。 ワークスペースの種類の詳細については、 「ワークスペースの作成」を参照してください。
ワークスペース ストレージには、ワークスペース ファイル システム データとワークスペース システム データの 2 つのカテゴリのデータが含まれています。 どちらも、独自のデータ オブジェクト (Unity Catalog テーブルやボリュームなど) とは別です。
ワークスペースファイルシステムデータ
ワークスペース ファイル システムには、ユーザーが Databricks UI を通じて作成および管理する資産が格納されます。これらには次のものが含まれます。
- ノートブック
- SQLクエリとダッシュボード
- アラート
- Repos ( Gitに添付されたフォルダー)
- ライブラリ (
.whl、.jar) - Pythonファイル、YAML設定ファイル、その他の小さなファイル
ワークスペース ファイルの詳細については、 「ワークスペース ファイルとは何ですか?」を参照してください。 。 ワークスペース アセットの完全なリストについては、 「ワークスペース オブジェクトの概要」を参照してください。
ワークスペースシステムデータ
すべての Databricks ワークスペースには、Databricks 機能によって内部的に生成されたシステム データも保存されます。このデータはメモリやデータベースに保存するには大きすぎるか、単一のコンピュート リソースの有効期間を超えて保持する必要があります。 ワークスペース システム データの例には次のようなものがあります。
- SQLクエリ結果とキャッシュされたクエリ結果
- ジョブ実行結果
- ノートブックの改訂
- 可観測性に使用されるSQLクエリプラン
- クラスターログ
各ワークスペース タイプに対するワークスペース ストレージの構成方法の詳細については、以下のセクションを参照してください。
サーバレスワークスペース
サーバーレス ワークスペースは、内部ワークスペース システム データおよびUnity Catalogデータ資産のフルマネージド ストレージ場所である、デフォルトストレージを使用します。 サーバーレス ワークスペースは、独自のカタログ、テーブル、その他のデータ資産を保存するクラウド ストレージの場所に接続する機能もサポートしています。 Databricks のデフォルト ストレージを参照してください。
クラシックワークスペース
クラウド アカウント内のワークスペース ストレージを削除または変更しないでください。Databricks ワークスペースが正しく動作するには、コントロール プレーン データベースとワークスペース ストレージの両方に依存します。ワークスペース ストレージを削除すると、ワークスペースを復元することはできません。
従来のワークスペースでは、ワークスペース システム データはDBFSとは異なります。 。 どちらもクラシック ワークスペースの同じクラウド ストレージ バケットに存在する可能性がありますが、目的は異なります。DBFSルートはユーザーがアクセスできるファイル システムですが、ワークスペース システム データはDatabricks機能によって内部的に使用されます。
クラシック ワークスペースを作成すると、 Databricksワークスペース ストレージ バケットとして使用する 3 つのバケットを Google クラウド アカウントに作成します。
- 1 つのワークスペース ストレージ バケットには、Databricks 機能によって生成される内部データである ワークスペース システム データ が格納されます。
- もう 1 つのワークスペース ストレージ バケットは、ワークスペースの DBFS のルート ストレージです。これはレガシーであり、ワークスペースで無効になっている可能性があります。DBFS (Databricks ファイル システム) は、
dbfs:/名前空間でアクセスできる Databricks 環境の分散ファイル システムです。DBFSルートとDBFSマウントは両方ともdbfs:/名前空間にあります。 DBFSルートまたはDBFSマウントを使用してデータを保存およびアクセスすることは非推奨のパターンであり、 Databricksでは推奨されていません。 詳細については、 DBFSとは何ですか?」を参照してください。 。 - ワークスペースが自動的にUnity Catalogを有効にしている場合、3 番目のワークスペース ストレージ バケットには、デフォルト Unity Catalog ワークスペース カタログ が含まれます。ワークスペース内のすべてのユーザーは、このカタログのデフォルトスキーマでアセットを作成できます。「 Unity Catalog の概要」を参照してください。
ワークスペース ストレージ バケットへのアクセスを制限するには、「 プロジェクト内のワークスペースの GCS バケットを保護する」を参照してください。