PostgreSQLからデータを取り込む
プレビュー
LakeFlow ConnectのPostgreSQLコネクタはパブリック プレビュー段階です。 パブリック プレビューに登録するには、Databricks アカウント チームにお問い合わせください。
このページではLakeFlow Connectを使用してPostgreSQLからデータを取り込み、 Databricksにロードする方法について説明します。 PostgreSQLコネクタは、 Azure ExpressRoute、 AWS Direct Connect、または VPN ネットワークを使用するAWS RDS PostgreSQL 、Aurora PostgreSQL 、 Amazon EC2 、 Azure Database for PostgreSQL 、 Azure仮想マシン、 GCPクラウドSQL for PostgreSQL 、およびPostgreSQLデータベースをサポートします。
始める前に
-
インジェスト ゲートウェイとインジェスト パイプラインを作成するには、次の要件を満たす必要があります。
-
ワークスペースで Unity Catalog が有効になっています。
-
サーバレス コンピュートがワークスペースで有効になっています。 サーバレス コンピュートの要件を参照してください。
-
接続を作成する場合:メタストアに対する権限は
CREATE CONNECTIONです。Unity Catalogの「権限の管理」を参照してください。コネクタが UI ベースのパイプライン オーサリングをサポートしている場合は、このページのステップを完了することで、接続とパイプラインを同時に作成できます。 ただし、API ベースのパイプライン オーサリングを使用する場合は、このページのステップを完了する前に、カタログ エクスプローラーで接続を作成する必要があります。 「管理対象取り込みソースへの接続」を参照してください。
-
既存の接続を使用する予定の場合: 接続に対して
USE CONNECTION権限またはALL PRIVILEGES権限があります。 -
ターゲット カタログに対する
USE CATALOG権限があります。 -
既存のスキーマに対する
USE SCHEMA、CREATE TABLE、およびCREATE VOLUME権限、またはターゲット カタログに対するCREATE SCHEMA権限があります。 -
プライマリ PostgreSQL インスタンスにアクセスできます。論理レプリケーションはプライマリ インスタンスでのみサポートされ、読み取りレプリカではサポートされません。
-
クラスターを作成するための無制限の権限、またはカスタム ポリシー (API のみ)。ゲートウェイのカスタム ポリシーは、次の要件を満たす必要があります。
-
ファミリー: ジョブコンピュート
-
ポリシー ファミリを上書きします:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 1,
"isOptional": true
},
"runtime_engine": {
"type": "fixed",
"value": "STANDARD",
"hidden": true
}
}- Databricks では、ゲートウェイのパフォーマンスに影響を与えないため、インジェスト ゲートウェイには可能な限り小さいワーカー ノードを指定することをお勧めします。次のコンピュート ポリシーにより、 Databricksワークロードのニーズに合わせて取り込みゲートウェイをスケーリングできます。 ソース データベースから効率的かつパフォーマンスの高いデータ抽出を可能にするには、最小要件として 8 コアが必要です。
Python{
"driver_node_type_id": {
"type": "fixed",
"value": "n2-highmem-64"
},
"node_type_id": {
"type": "fixed",
"value": "n2-standard-4"
}
}クラスターポリシーの詳細については、 「コンピュート ポリシーの選択」を参照してください。
-
-
-
PostgreSQL から取り込むには、ソースのセットアップも完了する必要があります。
ゲートウェイと取り込みパイプラインを作成する
Databricks UI
-
Databricksワークスペースのサイドバーで、 データ取り込み をクリックします。
-
[データの追加] ページの [Databricks コネクタ] で、 [PostgreSQL] をクリックします。
-
取り込みウィザードの**接続**ページで、PostgreSQLのアクセス資格情報が保存されている接続を選択してください。メタストアに対する
CREATE CONNECTION特権がある場合は、 接続の作成 をクリックして、PostgreSQL接続の作成で認証の詳細を使用して新しい接続を作成できます。
接続の作成 をクリックして、PostgreSQL接続の作成で認証の詳細を使用して新しい接続を作成できます。 -
次へ をクリックします。
-
インジェスト設定 ページで、インジェスト パイプラインの一意の名前を入力します。このパイプラインは、ステージング場所から宛先にデータを移動します。
-
イベント ログを書き込むカタログとスキーマを選択します。イベント ログには、監査ログ、データ品質チェック、パイプラインの進行状況、エラーが含まれます。カタログに対して
USE CATALOGとCREATE SCHEMA権限を持っている場合は、クリックできます。 新しいスキーマを作成するには、ドロップダウン メニューでスキーマを作成します。 -
(オプション) すべてのテーブルの自動完全更新を オン に設定します。自動更新がオンになっている場合、パイプラインは、影響を受けるテーブルを完全に更新することによって、ログ クリーンアップ イベントや特定の種類のスキーマ進化などの問題を自動的に修正しようとします。 履歴の追跡が有効になっている場合、完全更新によってその履歴は消去されます。
-
インジェストゲートウェイの一意の名前を入力します。ゲートウェイは、ソースから変更を抽出し、取り込みパイプラインがロードできるようにステージングするパイプラインです。
-
ステージング場所 のカタログとスキーマを選択します。抽出されたデータをステージングするためのボリュームがこの場所に作成されます。カタログに対して
USE CATALOGとCREATE SCHEMA権限を持っている場合は、クリックできます。 新しいスキーマを作成するには、ドロップダウン メニューでスキーマを作成します。 -
パイプラインの作成および続行 をクリックします。
-
[ソース] ページで、取り込むテーブルを選択します。特定のテーブルを選択した場合は、テーブル設定を構成できます。
a. (オプション) [設定] タブで、取り込まれたテーブルごとに 宛先名 を指定します。これは、オブジェクトを同じスキーマに複数回取り込むときに、宛先テーブルを区別するのに役立ちます。「宛先テーブルに名前を付ける」を参照してください。
a. (オプション) デフォルトの 履歴追跡 設定を変更します。「履歴追跡を有効にする (SCD タイプ 2)」を参照してください。
-
「次へ」 をクリックし、 「保存して続行」 をクリックします。
-
[宛先] ページで、データをロードするカタログとスキーマを選択します。カタログに対して
USE CATALOGとCREATE SCHEMA権限を持っている場合は、クリックできます。 新しいスキーマを作成するには、ドロップダウン メニューでスキーマを作成します。 -
保存して続行 をクリックします。
-
データベース設定 ページで、取り込み元となる各データベースのレプリケーション スロット名とパブリケーション名を入力します。
-
(オプション) スケジュールと通知 ページで、
スケジュールを作成します 。宛先テーブルを更新する頻度を設定します。 -
(オプション)クリック
通知を追加して パイプライン操作の成功または失敗に関する電子メール通知を設定し、 [保存してパイプラインを実行] をクリックします。
Declarative Automation Bundles、Databricks API、Databricks SDK、Databricks CLI、または Terraform を使用して取り込む前に、既存の Unity Catalog 接続にアクセスできる必要があります。手順については、PostgreSQL接続を作成するを参照してください。
ステージングカタログとスキーマを作成する
ステージング カタログとスキーマは、宛先カタログとスキーマと同じにすることができます。ステージング カタログをフォーリンカタログにすることはできません。
- CLI
export CONNECTION_NAME="my_postgresql_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_postgresql_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="postgresql-instance.example.com"
export DB_PORT="5432"
export DB_DATABASE="your_database"
export DB_USER="databricks_replication"
export DB_PASSWORD="your_secure_password"
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "POSTGRESQL",
"options": {
"host": "'"$DB_HOST"'",
"port": "'"$DB_PORT"'",
"database": "'"$DB_DATABASE"'",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
インジェスチョン ゲートウェイは、ソース データベースからスナップショットと変更データを抽出し、Unity Catalog ステージング ボリュームに保存します。ゲートウェイを継続的なパイプラインとして実行する必要があります。これは、PostgreSQL にとって、Write-Ahead Log (WAL) の肥大化を防ぎ、レプリケーション スロットに未使用の変更が蓄積されないようにするために重要です。
取り込み パイプラインは、スナップショットと変更データをステージング ボリュームから宛先ストリーミングテーブルに適用します。
宣言型自動化バンドル
宣言型自動化バンドルを使用して、データ取り込みパイプラインをデプロイできます。バンドルにはジョブとタスクの YAML 定義を含めることができ、 Databricks CLIを使用して管理でき、さまざまなターゲット ワークスペース (開発、ステージング、本番運用など) で共有して実行できます。 詳細については、 「宣言的オートメーション バンドル」を参照してください。
-
Databricks CLIを使用してバンドルを作成します。
Bashdatabricks bundle init -
バンドルに 2 つの新しいリソース ファイルを追加します。
- パイプライン定義ファイル (例:
resources/postgresql_pipeline.yml)。 - データ取り込みの頻度を制御するジョブ定義ファイル (例:
resources/postgresql_job.yml)。
以下は
resources/postgresql_pipeline.ymlファイルの例です。YAMLvariables:
# Common variables used multiple places in the DAB definition.
gateway_name:
default: postgresql-gateway
dest_catalog:
default: main
dest_schema:
default: ingest-destination-schema
resources:
pipelines:
gateway:
name: ${var.gateway_name}
gateway_definition:
connection_name: <postgresql-connection>
gateway_storage_catalog: main
gateway_storage_schema: ${var.dest_schema}
gateway_storage_name: ${var.gateway_name}
catalog: ${var.dest_catalog}
schema: ${var.dest_schema}
pipeline_postgresql:
name: postgresql-ingestion-pipeline
ingestion_definition:
ingestion_gateway_id: ${resources.pipelines.gateway.id}
source_type: POSTGRESQL
objects:
# Modify this with your tables!
- table:
# Ingest the table public.orders to dest_catalog.dest_schema.orders.
source_catalog: your_database
source_schema: public
source_table: orders
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
- schema:
# Ingest all tables in the public schema to dest_catalog.dest_schema. The destination
# table name will be the same as it is on the source.
source_catalog: your_database
source_schema: public
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
source_configurations:
- catalog:
source_catalog: your_database
postgres:
slot_config:
slot_name: databricks_slot
publication_name: databricks_publication
catalog: ${var.dest_catalog}
schema: ${var.dest_schema}以下は
resources/postgresql_job.ymlファイルの例です。YAMLresources:
jobs:
postgresql_dab_job:
name: postgresql_dab_job
trigger:
# Run this job every day, exactly one day from the last run
# See https://docs.databricks.com/api/workspace/jobs/create#trigger
periodic:
interval: 1
unit: DAYS
email_notifications:
on_failure:
- <email-address>
tasks:
- task_key: refresh_pipeline
pipeline_task:
pipeline_id: ${resources.pipelines.pipeline_postgresql.id} - パイプライン定義ファイル (例:
-
Databricks CLI を使用してパイプラインをデプロイします。
Bashdatabricks bundle deploy
Databricksノートブック
次のノートブックのConfigurationセルを、ソース接続、ターゲット カタログ、ターゲット スキーマ、およびソースから取り込むテーブルで更新します。
Create gateway and ingestion pipeline
Databricks CLI
ゲートウェイを作成するには:
gateway_json=$(cat <<EOF
{
"name": "$GATEWAY_PIPELINE_NAME",
"catalog": "$STAGING_CATALOG",
"schema": "$STAGING_SCHEMA",
"gateway_definition": {
"connection_name": "$CONNECTION_NAME",
"gateway_storage_catalog": "$STAGING_CATALOG",
"gateway_storage_schema": "$STAGING_SCHEMA",
"gateway_storage_name": "$GATEWAY_PIPELINE_NAME"
}
}
EOF
)
output=$(databricks pipelines create --json "$gateway_json")
echo $output
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
取り込みパイプラインを作成するには:
pipeline_json=$(cat <<EOF
{
"name": "$INGESTION_PIPELINE_NAME",
"catalog": "$TARGET_CATALOG",
"schema": "$TARGET_SCHEMA",
"ingestion_definition": {
"ingestion_gateway_id": "$GATEWAY_PIPELINE_ID",
"source_type": "POSTGRESQL",
"objects": [
{
"table": {
"source_catalog": "your_database",
"source_schema": "public",
"source_table": "orders",
"destination_catalog": "$TARGET_CATALOG",
"destination_schema": "$TARGET_SCHEMA",
"destination_table": "orders"
}
},
{
"schema": {
"source_catalog": "your_database",
"source_schema": "public",
"destination_catalog": "$TARGET_CATALOG",
"destination_schema": "$TARGET_SCHEMA"
}
}
],
"source_configurations": [
{
"catalog": {
"source_catalog": "your_database",
"postgres": {
"slot_config": {
"slot_name": "databricks_slot",
"publication_name": "databricks_publication"
}
}
}
}
]
}
}
EOF
)
databricks pipelines create --json "$pipeline_json"
Databricks CLI v0.276.0 以降が必要です。
Terraform
Terraform を使用して、PostgreSQL 取り込みパイプラインをデプロイおよび管理できます。ゲートウェイおよび取り込みパイプラインを作成するためのTerraform構成を含む完全なサンプル フレームワークについては、 GitHubのLakeFlow Connect Terraformリポジトリを参照してください。
パイプラインを開始、スケジュール、アラートを設定する
パイプラインのアラートの開始、スケジュール設定、および設定については、 「一般的なパイプライン メンテナンス タスク」を参照してください。
データ取り込みの成功を確認する
パイプラインの詳細ページのリスト ビューには、データが取り込まれるときに処理されるレコードの数が表示されます。これらの数字は自動的に更新されます。
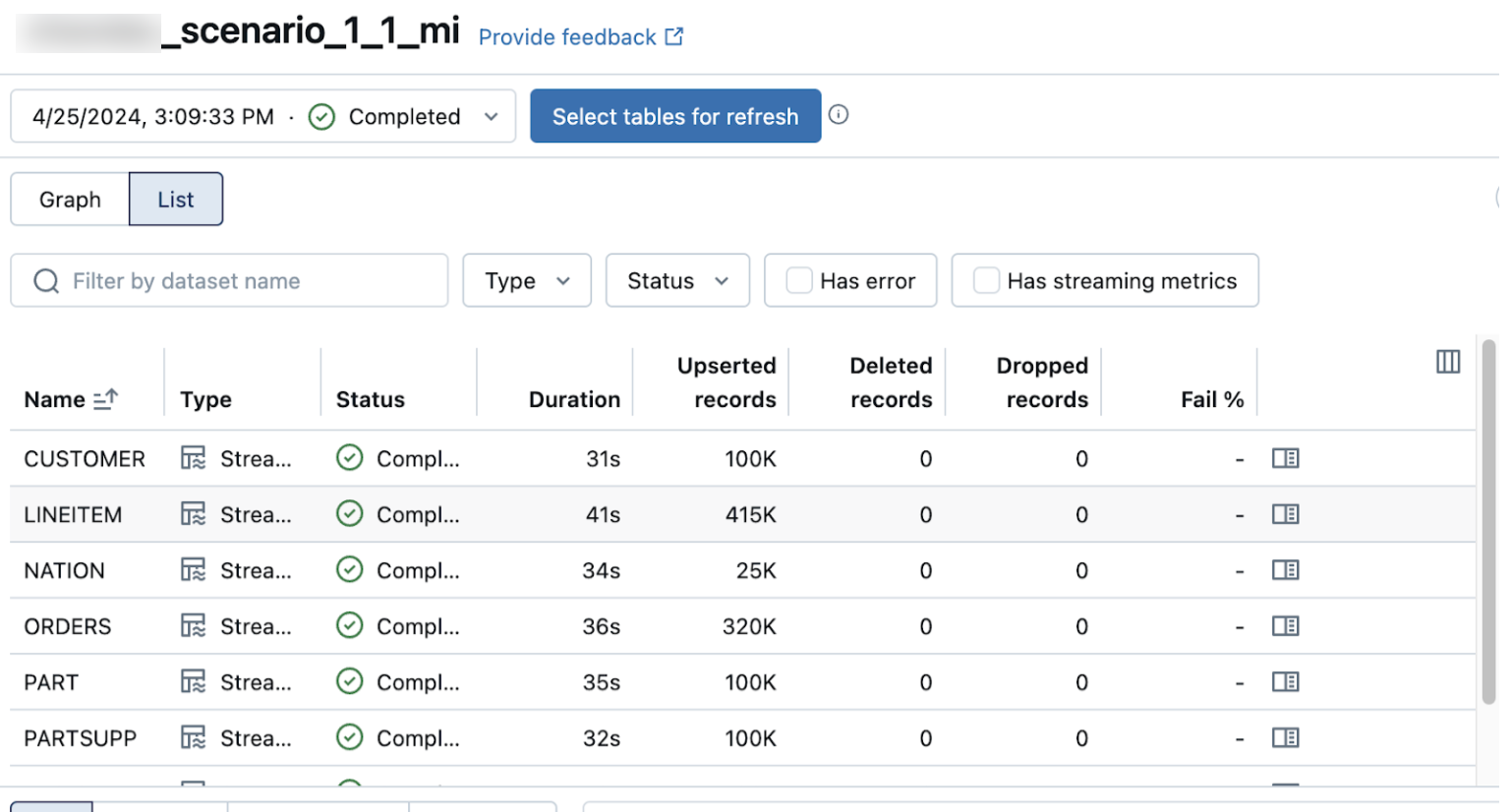
Upserted records列とDeleted records列はデフォルトでは表示されません。列の設定をクリックすると有効になります![]() ボタンをクリックして選択します。
ボタンをクリックして選択します。