PostgreSQL取り込みのトラブルシューティング
プレビュー
LakeFlow ConnectのPostgreSQLコネクタはパブリック プレビュー段階です。 パブリック プレビューに登録するには、Databricks アカウント チームにお問い合わせください。
このページでは、 Databricks LakeFlow ConnectのPostgreSQLコネクタに関する一般的な問題とその解決方法について説明します。
一般的なパイプラインのトラブルシューティング
このセクションのトラブルシューティング手順は、 Lakeflowコネクトのすべてのインジェスト パイプラインに適用されます。
実行中にパイプラインが失敗した場合は、失敗したステップをクリックし、エラー メッセージにエラーの性質に関する十分な情報が提供されているかどうかを確認します。
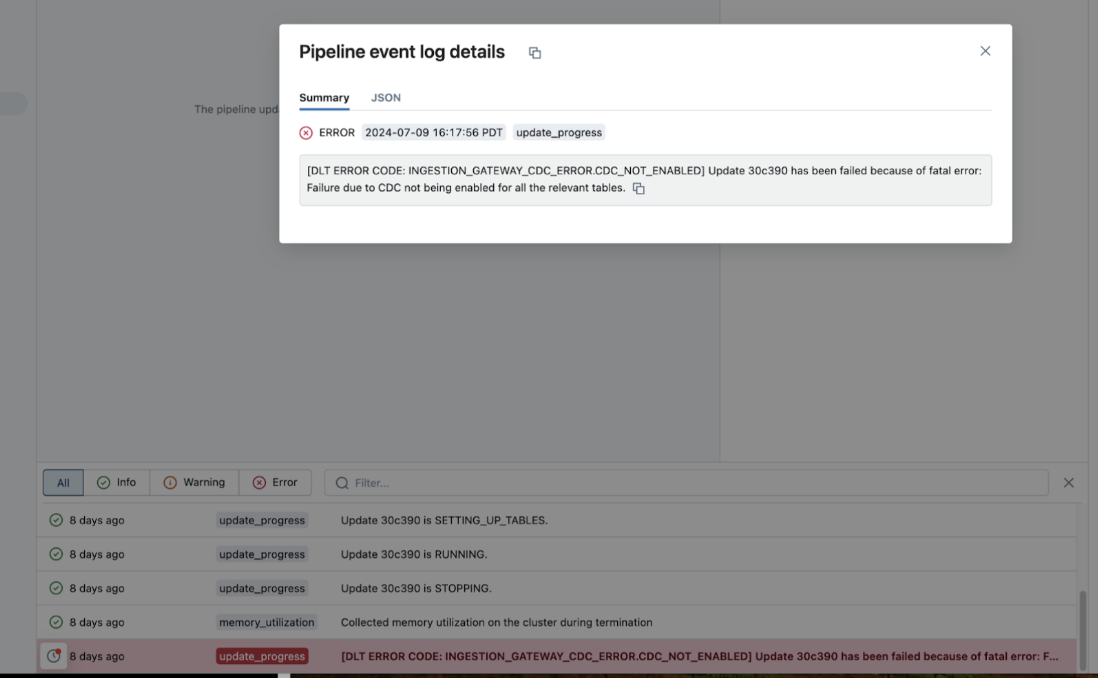
右側のパネルで [詳細の更新] をクリックし、 [ログ] を クリックして、パイプラインの詳細ページからクラスター ログを確認してダウンロードすることもできます。ログをスキャンしてエラーまたは例外がないか確認します。
コネクタ固有のトラブルシューティング
このセクションのトラブルシューティング ステップは、 PostgreSQLコネクタに固有のものです。
権限エラー
権限エラーが発生した場合は、レプリケーション ユーザーに必要な権限があることを確認してください。必要な権限の完全なリストについては、 PostgreSQL データベース ユーザー要件を参照してください。
エラー: テーブルへのアクセス権が拒否されました
このエラーは、レプリケーション ユーザーが指定されたテーブルに対してSELECT権限を持っていないことを示します。必要な権限を付与します。
GRANT SELECT ON TABLE schema_name.table_name TO databricks_replication;
エラー: レプリケーション スロットを使用するには、スーパーユーザーまたはレプリケーション ロールである必要があります
このエラーは、レプリケーション ユーザーにREPLICATION権限がないことを示します。レプリケーション ロールを付与します。
-- For standard PostgreSQL
ALTER USER databricks_replication WITH REPLICATION;
-- For AWS RDS/Aurora
GRANT rds_replication TO databricks_replication;
-- For GCP Cloud SQL
ALTER USER databricks_replication with REPLICATION;
論理レプリケーションが有効になっているかどうかを確認する
論理レプリケーションが有効になっているかどうかを確認するには:
SHOW wal_level;
出力はlogicalになります。そうでない場合は、 wal_level問題を更新し、 PostgreSQLサーバーを再起動します。
クラウド管理型 PostgreSQL の場合:
- AWS RDS/Aurora : 問題グループで
rds.logical_replicationを1に設定します。 - Azure Database for PostgreSQL : サーバー パラメーターで論理レプリケーションを有効にします。
- GCPクラウドSQL :
cloudsql.logical_decodingフラグをonに設定します。
出版物が存在するかどうかを確認する
テーブルのパブリケーションが存在するかどうかを確認するには:
SELECT * FROM pg_publication WHERE pubname = 'databricks_publication';
-- Check which tables are included in the publication
SELECT schemaname, tablename
FROM pg_publication_tables
WHERE pubname = 'databricks_publication';
出版物が存在しない場合は作成します。
CREATE PUBLICATION databricks_publication FOR TABLE schema_name.table_name;
レプリカのIDを確認する
テーブルのレプリカ ID 設定を確認するには:
SELECT schemaname, tablename, relreplident
FROM pg_tables t
JOIN pg_class c ON t.tablename = c.relname
WHERE schemaname = 'your_schema' AND tablename = 'your_table';
relreplident列には次の値が表示されます。
fFULLレプリカIDの場合(主キーまたはTOASTable列のないテーブルに必要)。d安全なレプリカ ID のために (主キーを使用)。
レプリカ ID が正しく設定されていない場合は、更新します。
ALTER TABLE schema_name.table_name REPLICA IDENTITY FULL;
レプリケーションスロットエラー
WALの蓄積とディスク容量の問題
インジェスチョン ゲートウェイが長期間停止すると、レプリケーション スロットによって Write-Ahead Log (WAL) ファイルが蓄積され、ディスク領域がいっぱいになる可能性があります。
WAL ディスク使用量を確認するには:
SELECT pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) AS retained_wal
FROM pg_replication_slots
WHERE slot_name = 'your_slot_name';
WAL の蓄積を防ぐには:
- 取り込みゲートウェイが継続的に実行されることを確認します。
- レプリケーションの遅延とディスク領域を定期的に監視します。
WAL ファイルが蓄積されている場合は、レプリケーション スロットを手動で削除できます。
SELECT pg_drop_replication_slot('your_slot_name');
レプリケーション スロットが削除されたり無効になったりした場合は、そのデータベースの新しいスロットでパイプライン仕様を更新し、完全更新を実行します。
テーブルトークンの待機中にタイムアウトが発生しました
ゲートウェイから情報が提供されるのを待機している間に、取り込みパイプラインがタイムアウトする可能性があります。これには、次のいずれかの理由が考えられます。
- 古いバージョンのゲートウェイを実行しています。
- 必要な情報を生成する際にエラーが発生しました。ゲートウェイ ドライバーのログでエラーを確認します。
- 初期スナップショットに予想よりも時間がかかっています。大きなテーブルの場合は、パイプラインのタイムアウトを増やすか、オフピーク時に初期ロードを実行することを検討してください。
ソーステーブルの名前の競合
Ingestion pipeline error: "org.apache.spark.sql.catalyst.ExtendedAnalysisException: Cannot have multiple queries named `orders_snapshot_load` for `orders`. Additional queries on that table must be named. Note that unnamed queries default to the same name as the table.
これは、同じ取り込みパイプラインによって同じ宛先スキーマに取り込まれている異なるソース スキーマ内のordersという名前の複数のソース テーブルが原因で、名前の競合が発生していることを示します。
これらの競合するテーブルを異なる宛先スキーマに書き込む複数のゲートウェイ パイプライン ペアを作成します。
Incompatible schema changes
互換性のないスキーマの変更により、取り込みパイプラインがINCOMPATIBLE_SCHEMA_CHANGEエラーで失敗します。レプリケーションを続行するには、影響を受けるテーブルの完全更新をトリガーします。
互換性のないスキーマの変更は次のとおりです。
- 列のデータ型の変更
- 列の名前を変更する
- テーブルの主キーの変更
- レプリカIDの一部である列を削除する
互換性のないスキーマ変更が原因で取り込みパイプラインが失敗した場合、Databricks ではスキーマ変更前のすべての行が取り込まれていることを保証できません。
接続タイムアウトエラー
接続タイムアウト エラーが発生した場合は、次のチェックを実行してください。
- ファイアウォール ルールが Databricks ワークスペースからの接続を許可していることを確認します。
- Databricks ネットワークから PostgreSQL サーバーにアクセスできることを確認します。
pg_hba.confファイルで Databricks IP 範囲からの接続が許可されていることを確認します。- 接続資格情報が正しいことを確認します。
SSL/TLS接続エラー
SSL/TLS 接続エラーが発生した場合は、次のチェックを実行してください。
-
PostgreSQL サーバーが SSL 接続をサポートしていることを確認します。
-
PostgreSQL構成の
ssl問題を確認してください。SQLSHOW ssl; -
pg_hba.confファイルでレプリケーション ユーザーに対して SSL 接続が必須または許可されていることを確認します。 -
クラウド管理データベースの場合、サーバー設定で SSL が適用されていることを確認します。
デフォルト認証: デフォルトの資格情報を設定できません
このエラーが発生した場合、現在のユーザー資格情報の検出に問題があります。次のものを置き換えてみてください:
w = WorkspaceClient()
と:
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
Databricks SDK for Python ドキュメントの 認証 を参照してください。
PERMISSION_DENIED: You are not authorized to create clusters. Please contact your administrator.
Databricks アカウント管理者に連絡して、 Unrestricted cluster creation権限を付与してください。
DLT ERROR CODE: INGESTION_GATEWAY_INTERNAL_ERROR
詳細なエラー メッセージについては、ドライバー ログ内のstdoutファイルを確認してください。一般的な原因は次のとおりです。
- レプリケーションスロットエラー
- 出版構成の問題
- ネットワーク接続の問題
- ソースデータベースに対する権限が不十分です
TLSサーバー証明書のエラー
TLSサーバー証明書の検証エラーのトラブルシューティングについては、 「TLS証明書エラーのトラブルシューティング」を参照してください。