SQL Server からデータを取り込む
LakeFlow Connectを使用してSQL ServerからDatabricksにデータを取り込む方法を学習します。
SQL Server コネクタは、Azure SQL Database、Azure SQL Managed Instance、Amazon RDS SQL データベースをサポートします。これには、Azure 仮想マシン (VM) および Amazon EC2 上で実行される SQL Server が含まれます。このコネクタは、Azure ExpressRoute および AWS Direct Connect ネットワークを使用したオンプレミスの SQL Server もサポートします。
要件
-
インジェスト ゲートウェイとインジェスト パイプラインを作成するには、まず次の要件を満たす必要があります。
-
ワークスペースが Unity Catalog に対して有効になっています。
-
サーバレス コンピュートがワークスペースで有効になっています。 サーバレス コンピュートの要件を参照してください。
-
接続を作成する場合:メタストアに対する権限は
CREATE CONNECTIONです。Unity Catalogの「権限の管理」を参照してください。コネクタが UI ベースのパイプラインオーサリングをサポートしている場合は、このページの手順を完了することで、接続とパイプラインを同時に作成できます。ただし、API ベースのパイプラインオーサリングを使用する場合は、このページの手順を完了する前に、Catalog Explorer で接続を作成する必要があります。「管理された取り込みソースに接続する」を参照してください。
-
既存の接続を使用する予定の場合: 接続に対する
USE CONNECTION権限またはALL PRIVILEGESがあります。 -
ターゲット・カタログに対する
USE CATALOG権限があります。 -
既存のスキーマに対する
USE SCHEMA、CREATE TABLE、CREATE VOLUME権限、またはターゲットカタログに対するCREATE SCHEMA権限を持っている。 -
プライマリ SQL Server インスタンスにアクセスできる。変更追跡機能とチェンジデータキャプチャ機能は、リードレプリカまたはセカンダリインスタンスではサポートされていません。
-
クラスターを作成するための無制限の権限、またはカスタム ポリシー (API のみ)。ゲートウェイのカスタム ポリシーは、次の要件を満たす必要があります。
-
ファミリー: ジョブ コンピュート
-
ポリシー ファミリを上書きします:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 1,
"isOptional": true
},
"runtime_engine": {
"type": "fixed",
"value": "STANDARD",
"hidden": true
}
}- Databricks では、ゲートウェイのパフォーマンスに影響を与えないため、インジェスト ゲートウェイに可能な限り最小のワーカー ノードを指定することをお勧めします。次のコンピュート ポリシーを使用すると、 Databricks ワークロードのニーズに合わせてインジェスト ゲートウェイをスケーリングできます。 ソース データベースから効率的かつパフォーマンスの高いデータ抽出を可能にするための最小要件は 8 コアです。
Python{
"driver_node_type_id": {
"type": "fixed",
"value": "n2-highmem-64"
},
"node_type_id": {
"type": "fixed",
"value": "n2-standard-4"
}
}詳細については、 情報 クラスターポリシーについては、「 コンピュートポリシーの選択」を参照してください。
-
-
-
SQL Serverから取り込むには、まず「 Databricksへの取り込み用にMicrosoft SQL Server構成する」の手順を完了する必要があります。
ゲートウェイと取り込みパイプラインを作成する
取り込みゲートウェイを手動で停止しないでください。ゲートウェイは、変更ログがファイルデータベース内で切り捨てられる前に変更をキャプチャするために、継続的に実行されなければなりません。 ゲートウェイが停止した場合、ログ保持期間のため変更内容が失われる可能性があり、影響を受けるすべてのテーブルを完全に更新する必要が生じます。ゲートウェイを停止して再起動すると、VMも再プロビジョニングされるため、起動時間が長くなります。ゲートウェイの問題をトラブルシューティングする必要がある場合は、 「SQL Server 取り込みのトラブルシューティング」を参照するか、Databricks サポートにお問い合わせください。
- Databricks UI
- Declarative Automation Bundles
- Databricks notebook
- Terraform
-
Databricksワークスペースのサイドバーで、 データ取り込み をクリックします。
-
[ データの追加 ] ページの [Databricks コネクタ ] で、[ SQL Server ] をクリックします。
-
取り込みウィザードの 接続 ページで、SQL Server アクセス資格情報を格納する接続を選択します。
CREATE CONNECTIONメタストアに対する 権限をお持ちの場合は、SQL Server 接続の作成 にある認証の詳細を使用して、 接続の作成 をクリックして新しい接続を作成できます。
Server 接続の作成 にある認証の詳細を使用して、 接続の作成 をクリックして新しい接続を作成できます。 -
次へ をクリックします。
-
インジェスト設定 ページで、インジェスト パイプラインの一意の名前を入力します。このパイプラインは、ステージング場所から宛先にデータを移動します。
-
イベント ログを書き込むカタログとスキーマを選択します。イベント ログには、監査ログ、データ品質チェック、パイプラインの進行状況、エラーが含まれます。カタログに対して
USE CATALOGとCREATE SCHEMA権限を持っている場合は、クリックできます。 新しいスキーマを作成するには、ドロップダウン メニューでスキーマを作成します。 -
(オプション) すべてのテーブルの自動完全更新を オン に設定します。自動更新がオンになっている場合、パイプラインは、影響を受けるテーブルを完全に更新することによって、ログ クリーンアップ イベントや特定の種類のスキーマ進化などの問題を自動的に修正しようとします。 履歴の追跡が有効になっている場合、完全更新によってその履歴は消去されます。
-
インジェストゲートウェイの一意の名前を入力します。ゲートウェイは、ソースから変更を抽出し、取り込みパイプラインがロードできるようにステージングするパイプラインです。
-
ステージング場所 のカタログとスキーマを選択します。抽出されたデータをステージングするためのボリュームがこの場所に作成されます。カタログに対して
USE CATALOGとCREATE SCHEMA権限を持っている場合は、クリックできます。 新しいスキーマを作成するには、ドロップダウン メニューでスキーマを作成します。 -
パイプラインの作成および続行 をクリックします。
-
[ソース] ページで、取り込むテーブルを選択します。特定のテーブルを選択した場合は、テーブル設定を構成できます。
a. (オプション) [設定] タブで、取り込まれたテーブルごとに 宛先名 を指定します。これは、オブジェクトを同じスキーマに複数回取り込むときに、宛先テーブルを区別するのに役立ちます。「宛先テーブルに名前を付ける」を参照してください。
a. (オプション) デフォルトの 履歴追跡 設定を変更します。「履歴追跡を有効にする (SCD タイプ 2)」を参照してください。
-
「次へ」 をクリックし、 「保存して続行」 をクリックします。
-
[宛先] ページで、データをロードするカタログとスキーマを選択します。カタログに対して
USE CATALOGとCREATE SCHEMA権限を持っている場合は、クリックできます。 新しいスキーマを作成するには、ドロップダウン メニューでスキーマを作成します。 -
保存して続行 をクリックします。
-
データベース設定 ページで、 「検証」 をクリックして、ソースが Databricks 取り込み用に適切に構成されていることを確認します。不足している構成があれば返されます。ステップを解決するには、 「構成を完了する」 をクリックします。 次に 「次へ」 をクリックします。または、 「検証をスキップ」 をクリックします。
-
(オプション) スケジュールと通知 ページで、
スケジュールを作成します 。宛先テーブルを更新する頻度を設定します。 -
(オプション)クリック
通知を追加して パイプライン操作の成功または失敗に関する電子メール通知を設定し、 [保存してパイプラインを実行] をクリックします。
宣言型オートメーションバンドルを使用して取り込みを行う前に、既存の接続にアクセスできる必要があります。手順については、「SQL Server接続の作成」を参照してください。
ステージング カタログとスキーマは、宛先カタログとスキーマと同じにすることができます。ステージング カタログをフォーリンカタログにすることはできません。 バンドル パイプライン YAML ファイルのgateway_definitionセクションでステージング場所を指定します。
インジェスト ゲートウェイは、ソース データベースからスナップショットと変更データを抽出し、それを Unity Catalog ステージング ボリュームに格納します。ゲートウェイは、連続パイプラインとして実行する必要があります。これにより、ソース・データベースにある変更ログの保持ポリシーに対応できます。
取り込み パイプラインは、スナップショットと変更データをステージング ボリュームから宛先ストリーミングテーブルに適用します。
バンドルにはジョブとタスクの YAML 定義を含めることができ、 Databricks CLIを使用して管理でき、さまざまなターゲット ワークスペース (開発、ステージング、本番運用など) で共有して実行できます。 詳細については、 「宣言的オートメーション バンドルとは何ですか?」を参照してください。 。
-
Databricks CLIを使用してバンドルを作成します。
Bashdatabricks bundle init -
パイプラインとジョブ構成をバンドルに追加します。利用可能なすべてのオプションを含む完全な例については、例を参照してください。
-
Databricks CLI を使用してパイプラインをデプロイします。
Bashdatabricks bundle deploy
次のノートブックの Configuration セルを、ソースから取り込むソース接続、ターゲット カタログ、ターゲット スキーマ、およびテーブルで更新します。
Terraform を使用して、SQL Server 取り込みパイプラインをデプロイおよび管理できます。ゲートウェイおよび取り込みパイプラインを作成するためのTerraform構成を含む完全なサンプル フレームワークについては、 GitHubのLakeFlow Connect Terraformリポジトリを参照してください。
データ取り込みが成功したことを確認する
パイプラインの詳細ページのリストビューには、データの取り込み時に処理されたレコードの数が表示されます。これらの番号は自動的に更新されます。
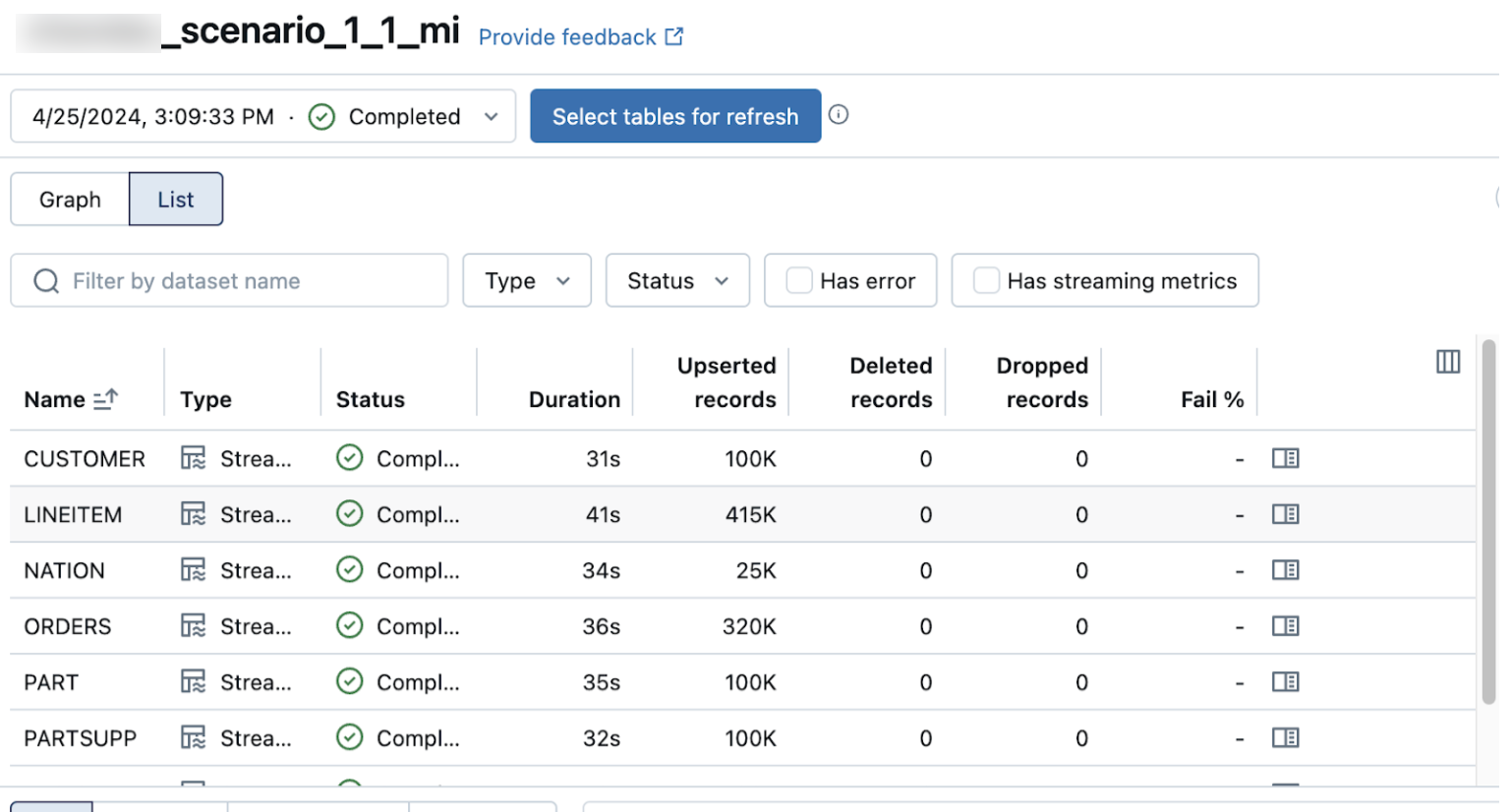
Upserted records列とDeleted records列は、デフォルトでは表示されません。これらを有効にするには、列の設定 ![]() ボタンをクリックして選択します。
ボタンをクリックして選択します。
例
これらの例を使用してパイプラインを構成します。
パイプライン構成
- Declarative Automation Bundles
- Databricks notebook
次のバンドルは、ゲートウェイパイプライン、インジェストパイプライン、およびスケジュールされたジョブを定義します。コメントアウトされたオプションは、利用可能なすべての構成を表示します。variables および targets セクションをソースと宛先の詳細で更新します。
bundle:
name: lakeflow-connect-sqlserver
# Variables parameterize the bundle for different environments and sources.
# Set values here, override per-target, or pass with: databricks bundle deploy -var="key=value"
variables:
# The name of the Unity Catalog connection to your SQL Server instance.
# This connection must already exist and be of type SQLSERVER.
connection_name:
description: 'Unity Catalog connection name for the SQL Server source'
# The SQL Server database name to ingest from.
# In Lakeflow Connect, this maps to source_catalog in the table/schema spec.
source_database:
description: 'SQL Server database name (maps to source_catalog in table specs)'
# The SQL Server schema to ingest from (for example, "dbo", "sales").
source_schema:
description: 'SQL Server schema name to ingest from'
# The Unity Catalog catalog where ingested Delta tables are created.
dest_catalog:
description: 'Destination Unity Catalog catalog for ingested tables'
# The Unity Catalog schema where ingested Delta tables are created.
dest_schema:
description: 'Destination Unity Catalog schema for ingested tables'
# The Unity Catalog catalog for the gateway's internal staging volume.
# Can be the same as dest_catalog. Must not be a foreign catalog.
staging_catalog:
description: 'Catalog for gateway staging volume'
# The Unity Catalog schema for the gateway's internal staging volume.
staging_schema:
description: 'Schema for gateway staging volume'
resources:
pipelines:
# --- Gateway pipeline ---
# Extracts change data from SQL Server and stages it in a Unity Catalog
# volume. Must run continuously to capture changes before change logs are
# truncated in the source database.
gw_pipeline:
name: 'lfc-sqlserver-gateway-${bundle.target}'
# Gateway pipelines must be continuous.
continuous: true
# "CURRENT" (stable) or "PREVIEW" (early access).
channel: 'CURRENT'
# (Optional) Associate with a budget policy for cost tracking.
# budget_policy_id: "<policy-uuid>"
# The gateway runs on classic compute. Cluster settings are managed
# automatically. You can optionally customize the cluster:
# clusters:
# - label: "default"
# autoscale:
# min_workers: 1
# max_workers: 4
# # node_type_id: "i3.xlarge"
# # Restrict the cluster to an approved cluster policy.
# # policy_id: "<cluster-policy-id>"
catalog: ${var.staging_catalog}
schema: ${var.staging_schema}
gateway_definition:
# (Required) Unity Catalog connection name (type SQLSERVER).
connection_name: ${var.connection_name}
# (Required) Catalog and schema for the staging volume.
gateway_storage_catalog: ${var.staging_catalog}
gateway_storage_schema: ${var.staging_schema}
# (Optional) Custom staging volume name. If not set, the system
# auto-generates: __databricks_ingestion_gateway_staging_data-<pipeline_id>
# gateway_storage_name: "my_custom_staging_volume"
# --- Ingestion pipeline ---
# Reads staged data from the gateway and applies it to Delta tables.
mi_pipeline:
name: 'lfc-sqlserver-ingestion-${bundle.target}'
# Continuous mode is not supported for the ingestion pipeline.
# Use a scheduled job to trigger runs.
continuous: false
channel: 'CURRENT'
# (Optional) Associate with a budget policy for cost tracking.
# budget_policy_id: "<policy-uuid>"
# The ingestion pipeline runs on serverless compute only.
serverless: true
# (Optional) Development mode for faster iteration (no retries).
# development: true
catalog: ${var.dest_catalog}
schema: ${var.dest_schema}
# (Optional) Email notifications for pipeline events.
# notifications:
# - email_recipients:
# - "team@example.com"
# alerts:
# - "on-update-failure"
# - "on-update-fatal-failure"
# - "on-flow-failure"
# (Optional) Run as a service principal for production.
# run_as:
# service_principal_name: "my-service-principal"
ingestion_definition:
# (Required) References the gateway pipeline. The connection is
# inherited from the gateway. Do not specify connection_name here.
ingestion_gateway_id: ${resources.pipelines.gw_pipeline.id}
# Pipeline-level table configuration defaults. These apply to all
# tables unless overridden at the schema or table level.
table_configuration:
# SCD Type: How changes are applied to destination tables.
# SCD_TYPE_1: Overwrites rows with latest values (default).
# SCD_TYPE_2: Preserves history with __START_AT/__END_AT columns.
# Requires CDC on source. CT does not support SCD_TYPE_2.
# APPEND_ONLY: Inserts only. Updates and deletes are ignored.
scd_type: 'SCD_TYPE_1'
# (Optional) Auto full refresh policy. Triggers a snapshot when the
# pipeline detects issues resolvable by re-reading all source data
# (for example, CT/CDC retention window expired).
# auto_full_refresh_policy:
# enabled: true
# min_interval_hours: 24
# (Optional) Schedule automatic full refreshes.
# full_refresh_window:
# start_hour: 2
# days_of_week:
# - "SUNDAY"
# time_zone_id: "America/Los_Angeles"
objects:
# Option 1: Schema-level ingestion. Ingests all tables from a source
# schema. New tables added to the schema are picked up automatically.
- schema:
source_catalog: ${var.source_database}
source_schema: ${var.source_schema}
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
# (Optional) Override table_configuration for this schema.
# table_configuration:
# scd_type: "SCD_TYPE_2"
# Option 2: Table-level ingestion. Provides granular control.
# Replace or combine with the schema-level spec.
# - table:
# source_catalog: ${var.source_database}
# source_schema: ${var.source_schema}
# source_table: "customers"
# destination_catalog: ${var.dest_catalog}
# destination_schema: ${var.dest_schema}
# # (Optional) Rename the table at the destination.
# # destination_table: "customers_v2"
# table_configuration:
# scd_type: "SCD_TYPE_1"
# # Include only specific columns (mutually exclusive with exclude_columns).
# # include_columns:
# # - "customer_id"
# # - "first_name"
# # - "email"
# # Exclude specific columns. All other columns are included.
# # exclude_columns:
# # - "internal_notes"
# # Override the primary key used for change detection.
# # primary_keys:
# # - "customer_id"
# # Logical ordering columns for change resolution.
# # sequence_by:
# # - "updated_at"
# # Auto full refresh for this table.
# # auto_full_refresh_policy:
# # enabled: true
# # min_interval_hours: 48
# (Optional) Grant additional users or groups access.
# permissions:
# - user_name: "analyst@example.com"
# level: "CAN_VIEW"
# - group_name: "data-engineers"
# level: "CAN_RUN"
# --- Scheduled job ---
# Triggers the ingestion pipeline on a schedule.
jobs:
mi_schedule:
name: 'lfc-sqlserver-ingestion-schedule-${bundle.target}'
# Quartz cron syntax: "seconds minutes hours day month day-of-week"
# Examples: "0 0 * * * ?" (hourly), "0 0 */4 * * ?" (every 4 hours)
schedule:
quartz_cron_expression: '0 */30 * * * ?'
timezone_id: 'UTC'
tasks:
- task_key: 'run_ingestion'
pipeline_task:
pipeline_id: ${resources.pipelines.mi_pipeline.id}
# email_notifications:
# on_failure:
# - "team@example.com"
# Deploy to different workspaces with: databricks bundle deploy -t <target>
targets:
dev:
default: true
workspace:
host: https://<workspace-url>.cloud.databricks.com
variables:
connection_name: '<sqlserver-connection>'
source_database: '<database-name>'
source_schema: 'dbo'
dest_catalog: '<dest-catalog>'
dest_schema: '<dest-schema>'
staging_catalog: '<staging-catalog>'
staging_schema: '<staging-schema>'
以下はパイプライン仕様のConfigurationセクションの例です。
# The name of the UC connection with the credentials to access the source database
connection_name = "my_connection"
# The name of the UC catalog and schema to store the replicated tables
target_catalog_name = "main"
target_schema_name = "lakeflow_sqlserver_connector_cdc"
# The name of the UC catalog and schema to store the staging volume with intermediate
# CDC and snapshot data. Use the destination catalog/schema by default.
stg_catalog_name = target_catalog_name
stg_schema_name = target_schema_name
# The name of the Gateway pipeline to create
gateway_pipeline_name = "cdc_gateway"
# The name of the Ingestion pipeline to create
ingestion_pipeline_name = "cdc_ingestion"
# Construct the full list of tables to replicate.
# IMPORTANT: The letter case of catalog, schema, and table names must match exactly
# the case used in the source database system tables.
tables_to_replicate = replicate_full_db_schema("MY_DB", ["MY_DB_SCHEMA"])
# Append tables from additional schemas as needed:
# + replicate_tables_from_db_schema("MY_DB", "MY_SCHEMA_2", ["table3", "table4"])
一般的なパターン
高度なパイプライン構成については、 「管理された取り込みパイプラインの一般的なパターン」を参照してください。
次のステップ
パイプラインを開始、スケジュールし、アラートを設定します。一般的なパイプラインメンテナンスタスクを参照してください。