For eachタスクを使用して、ループ内の別のタスクを実行する
この記事では、ジョブ UI でのタスクの追加と構成の詳細など、Lakeflow ジョブでの For each タスクの使用について説明します。For each タスクを使用して、ネストされたタスクをループ内で実行し、タスクの各反復に異なるパラメーターのセットを渡します。
For each タスクをジョブに追加するには、For each タスクと ネストされたタスク の 2 つのタスクを定義する必要があります。ネストされたタスクは、 For each タスクの反復ごとに実行するタスクであり、標準の Lakeflow ジョブ タスク タイプの 1 つです。 ネストされたタスクとして別の For each タスクを追加することはできません。
たとえば、 For each タスクを使用して、複数のテーブルに対して共通の変換セットを実行し、テーブル名のリストからタスクの各イテレーションにテーブル名を渡すことができます。
相互に依存関係を持たないネストされたタスクは、同時に実行できます。
For eachタスクをジョブに追加する
For eachタスクは、ジョブを作成するとき、または既存のジョブのタスクを編集するときに追加できます。For eachタスクを設定するには:
-
[ タスクの追加 ] をクリックします。
-
[ タスク名] フィールドに名前を入力します。
-
[タイプ] ドロップダウン メニューで、 [それぞれ] を選択します。
-
「タスク名」 フィールドにタスクの名前を入力します。
-
[入力] テキスト ボックスで、反復処理する
For eachタスクの値を JSON 形式の値の配列として定義します。入れ子になったタスクにパラメーターを渡す方法の詳細については、「For eachタスクで使用できるパラメーターの種類」を参照してください。 -
必要に応じて、並列で実行できるイテレーションの数を設定するには、タスクの 同時実行 値を入力します。 デフォルト値は 1 です。
-
オプションでタスクの開始、成功、または失敗の通知を受け取るには、 [+ 追加] をクリックします。 「ジョブに通知を追加する」を参照してください。
-
For eachタスクの設定を完了し、各イテレーションで実行するネストされたタスクを追加するには、[ ループするタスクを追加 ] をクリックします。 -
ネストされたタスクのタスクタイプと設定オプションを選択します。ネストされたタスクは標準のタスクタイプであり、同じ設定オプションがあります。 「Lakeflowジョブでのタスクの設定と編集」を参照してください。
-
For eachタスクから渡されたパラメーターを参照するには、[ パラメーター ] をクリックします。各イテレーションの配列値に値を設定するために{{input}}参照を使用するか、オブジェクトのリストを反復処理するときに個々のオブジェクト フィールドを参照するために{{input.<key>}}を使用します。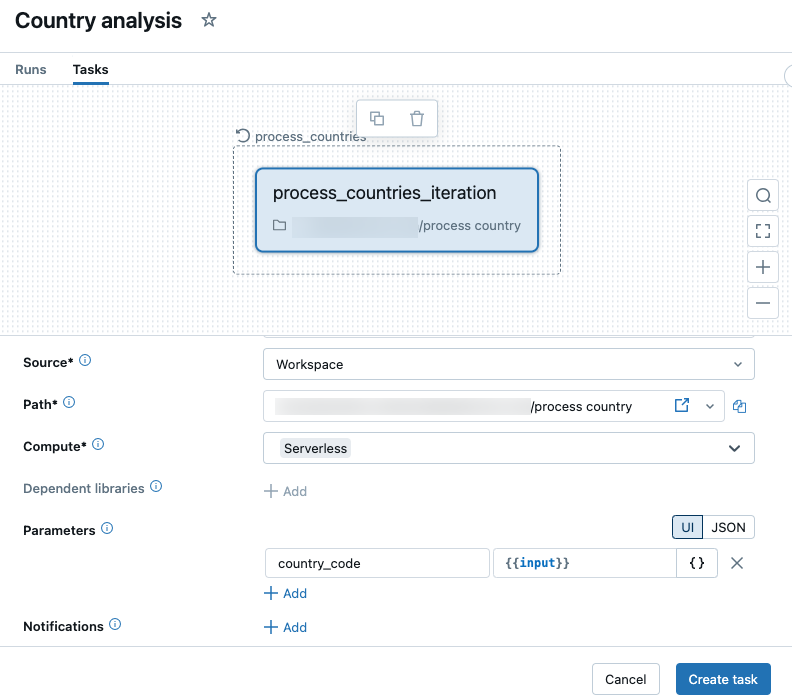
-
「 タスクを作成 」をクリックします。
For eachタスクとネストされたタスクの切り替え
For eachタスクは、ジョブUIにノードとして表示され、ネストされたタスクノードはFor eachノード内に表示されます。For eachタスクとネストされたタスクを切り替えるには、それぞれのノードをクリックします。
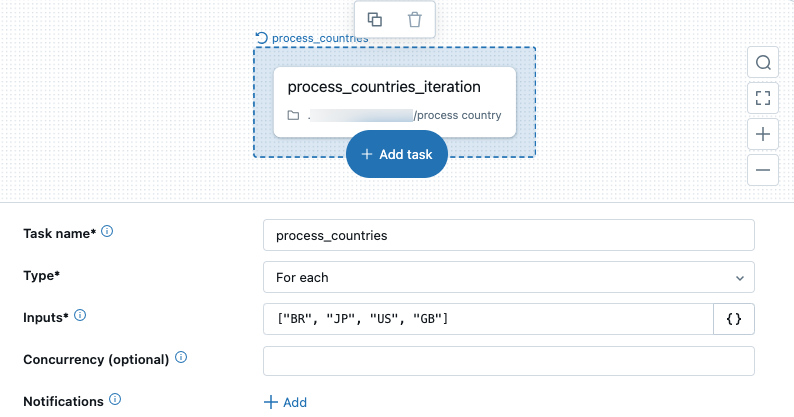
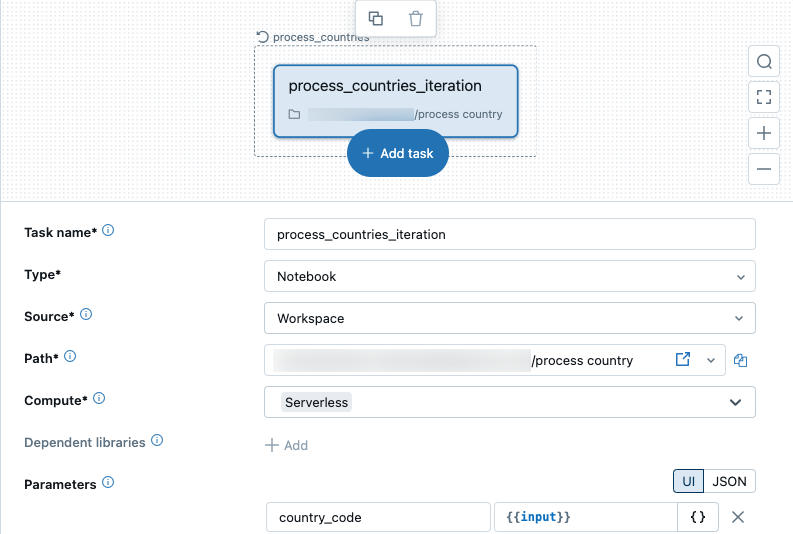
For each タスクで使用できるパラメーターの種類は何ですか?
For each タスクは、ネストされたタスクの各反復にパラメーターを渡します。入力はオブジェクトの配列であり、各オブジェクトはネストされたタスクの反復に渡されます。 タスクが使用する入力を作成するには、 JSON 形式の配列、タスク値、またはジョブ パラメーターなど、複数の方法があります。
パラメーターは、UI で直接 5,000 文字に制限されるか、タスク値参照 (値がそれを説明する文字列のサイズよりもはるかに大きくなる可能性がある) を使用する場合は 48 KB、ジョブ パラメーターの値の場合は 10,000 文字に制限されます。 パラメーターが 48 KB を超える必要がある場合は、より大きな構成ファイルにルックアップを渡すことができます。 「大きなパラメーター配列のルックアップ テーブルの使用」を参照してください。
JSON 形式の値の配列
タスクを作成または編集するときに、 [入力] テキスト ボックスを使用して、ネストされたタスクの値の配列を直接定義できます。 これは、次のデータ型の配列にすることができます。
- キーと値のペア
- 文字列、数値、または Boolean 型
- 任意の複雑なJSONオブジェクト
[入力] テキスト ボックス (したがって、このボックスに直接渡される JSON) は 5,000 文字に制限されています。
タスク値の参照
先行タスクからタスク値を渡すことができます。 渡されたタスクの値を参照するには、 {{tasks.<task_name>.values.<task_value_name>}} 構文を使用して [入力] テキスト ボックスに値を設定します。 たとえば、For each タスクの前にある generate_countries_list という名前のタスクで、次のタスク値を設定するとします。
dbutils.jobs.taskValues.set(key = "countries", value = countries_array)
次に、 For each タスクは、次の構文を使用して [入力] テキスト ボックスのタスク値を参照します。
{{tasks.generate_countries_list.values.countries}}.
[入力 ] テキスト ボックスには最大 5,000 文字を入力できますが、参照が表す値は最大 48 KB です。タスクの値の詳細については、「 タスクの値を使用してタスク間で情報を渡す」を参照してください。
ジョブ パラメーター
ジョブ・パラメーターを入力として使用することもできます。 ジョブ・パラメーターを参照するには、 入力 テキスト・ボックスで {{job.parameters.<name>}}という構文を使用します。 たとえば、 {{job.parameters.countries}}.
「入力 」テキスト・ボックスには、ジョブ・パラメーターを参照するために最大 5,000 文字を入力できます。ジョブ・パラメーター値は 10 KB に制限されています。ジョブ・パラメーターについて詳しくは、 ジョブ・パラメーターの構成を参照してください。
ダウンストリームタスクで For each タスクを参照する
For eachタスクは最上位のタスクであり、ダウンストリーム タスクはそれを依存関係として指定できます。ダウンストリーム タスクは、ネストされたタスクに依存したり、参照したりすることはできません。
入力値を提供する上流タスクが無効になっている場合、 For eachタスクは失敗します。制限事項を参照してください。
For eachタスクを使用したジョブの実行と監視
For eachタスクでジョブを実行する方法は、他のジョブを実行するのと同じです。
ジョブ実行の表示と管理も、タスクの反復のテーブルとして表示される For each タスクのタスク実行履歴を除き、他のジョブと同じです。 「For eachタスクのタスク実行履歴の表示」を参照してください。
チュートリアル
SQL タスクとFor eachタスクを使用してメタデータ駆動型ジョブを構築するには、 「制御テーブルを使用してFor eachジョブを駆動する」を参照してください。