Databricks の相互運用性と使いやすさ
相互運用性とユーザビリティ の柱は、Databricks がユーザーや他のシステムとどのように連携するかを扱います。Databricks の中心となる考え方は、Databricks を利用するすべてのペルソナに優れたエクスペリエンスを提供し、同時に、外部システムの幅広いエコシステムと統合することです。
- 相互運用性とは 、システムが他のシステムと連携し、他のシステムと統合する能力です。 これは、異なるコンポーネントと製品間 (場合によっては複数のベンダーから)、および同じ製品の過去と将来のバージョン間の相互作用を意味します。
- ユーザビリティとは 、システムがユーザーがタスクを安全、効果的、効率的に実行できるかどうかの尺度です。
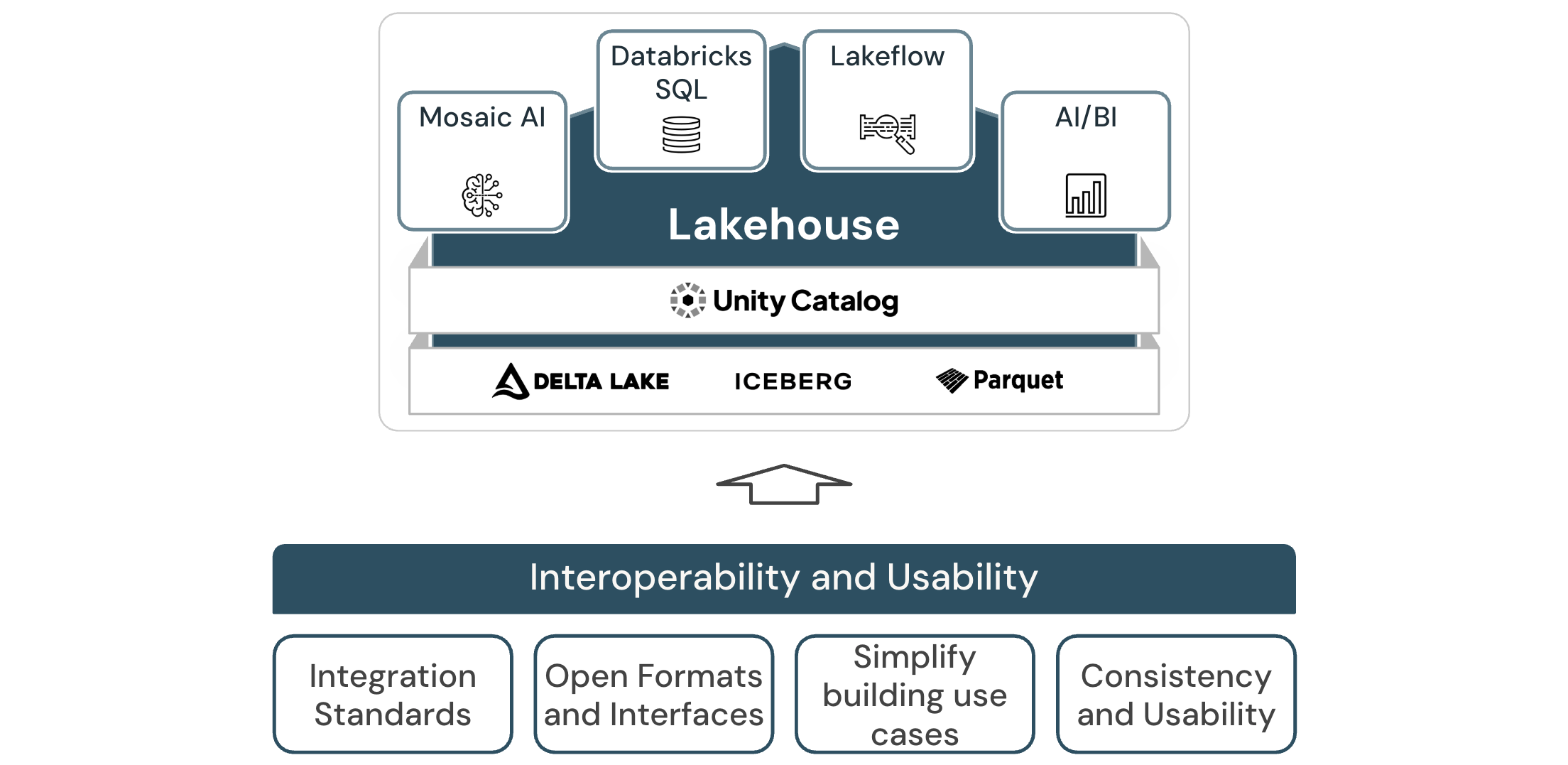
この柱の原則に従うと、次のことに役立ちます。
- 一貫性のある協調的なユーザーエクスペリエンスを実現します。
- クラウド間での相乗効果を活用します。
- Databricksとの統合を簡素化します。
- トレーニングとイネーブルメントのコストを削減します。
そして最終的には、価値実現までの時間を短縮することにつながります。
相互運用性とユーザビリティの原則
-
統合の標準を定義する
統合にはさまざまな側面があり、さまざまな方法で行うことができます。 ツールとアプローチの急増を回避するには、ベスト プラクティスを定義し、十分にサポートされ、推奨されるツールとコネクタのリストを提供する必要があります。
主要なアーキテクチャ原則の 1 つは、緊密な統合ではなく、モジュール性と疎結合です。 これにより、コンポーネントとワークロード間の依存関係が減り、副作用が排除され、さまざまな時間スケールでの独立した開発が可能になります。 データセットとそのスキーマをコントラクトとして使用します。 データ ラングリング ジョブ (データの読み込みやデータ レイクへの変換など) などのワークロードを、付加価値ジョブ (レポート、ダッシュボード、データ サイエンス フィーチャ エンジニアリングなど) から分離します。 データ形式、データ品質、およびデータライフサイクルに関するガイドラインを含む中央データカタログを定義します。
-
オープンインターフェースとオープンデータ形式を使用
多くの場合、データが特定のシステムを介してのみアクセスできるソリューションが開発されます。これはベンダーロックインにつながる可能性がありますが、そのシステムを介したデータアクセスがライセンス料の対象となる場合、大きなコスト要因にもなり得ます。オープンデータフォーマットとインターフェースを使用することで、これを回避できます。これにより、既存のシステムとの統合も簡素化され、ツールをすでにDatabricksと統合しているパートナーのエコシステムも開かれます。
データサイエンスにPythonやR、データアクセスとアクセス権制御にSparkやANSI SQLなどのオープンソースエコシステムを使用すると、プロジェクトの人員を簡単に見つけることができます。 また、プラットフォームとの間の潜在的な移行も簡素化されます。
-
新しいユースケースの実装を簡素化
データレイク内のデータを最大限に活用するには、ユーザーがプラットフォーム上でユースケースを簡単にデプロイできる必要があります。 これは、プラットフォームへのアクセスとデータマネジメントに関するリーンなプロセスから始まります。 たとえば、プラットフォームへのセルフサービス アクセスは、中央チームがボトルネックになるのを防ぐのに役立ちます。 共有環境と新しい環境をデプロイするための事前定義されたブループリントにより、どのビジネス・ユーザーでもプラットフォームを迅速に利用できるようになります。
-
データの一貫性と有用性を確保
データプラットフォーム上での2つの重要な活動は、 データの公開 と データ消費 です。 パブリッシングの観点からは、データは製品として提供されるべきです。 パブリッシャーは、消費者を念頭に置いて定義されたライフサイクルに従う必要があり、データは管理されたスキーマや説明などで明確に定義する必要があります。
また、消費者がさまざまなデータセットを簡単に理解し、正しく組み合わせることができるように、意味的に一貫性のあるデータを提供することも重要です。 さらに、すべてのデータは、適切にキュレーションされたメタデータとデータリネージを備えた中央カタログを通じて、消費者が簡単に検出およびアクセスできる必要があります。
次へ: 相互運用性とユーザビリティに関するおすすめの方法
相互運用性と使いやすさのベスト プラクティスを参照してください。