AIエージェントを作成し、 Databricks Appsにデプロイする
AIエージェントを構築し、 Databricks Appsを使用してデプロイします。 Databricks Apps使用すると、エージェント コード、サーバー構成、展開ワークフローを完全に制御できます。 このアプローチは、カスタム サーバー動作、Git ベースのバージョン管理、またはローカル IDE 開発が必要な場合に最適です。
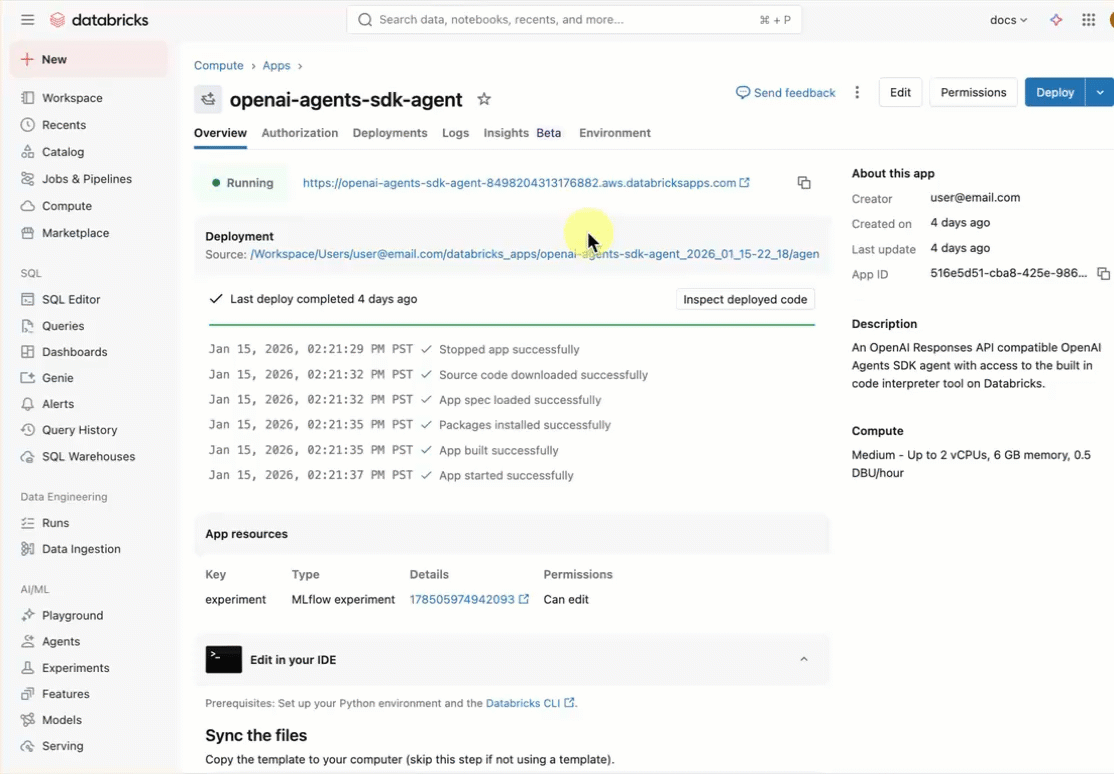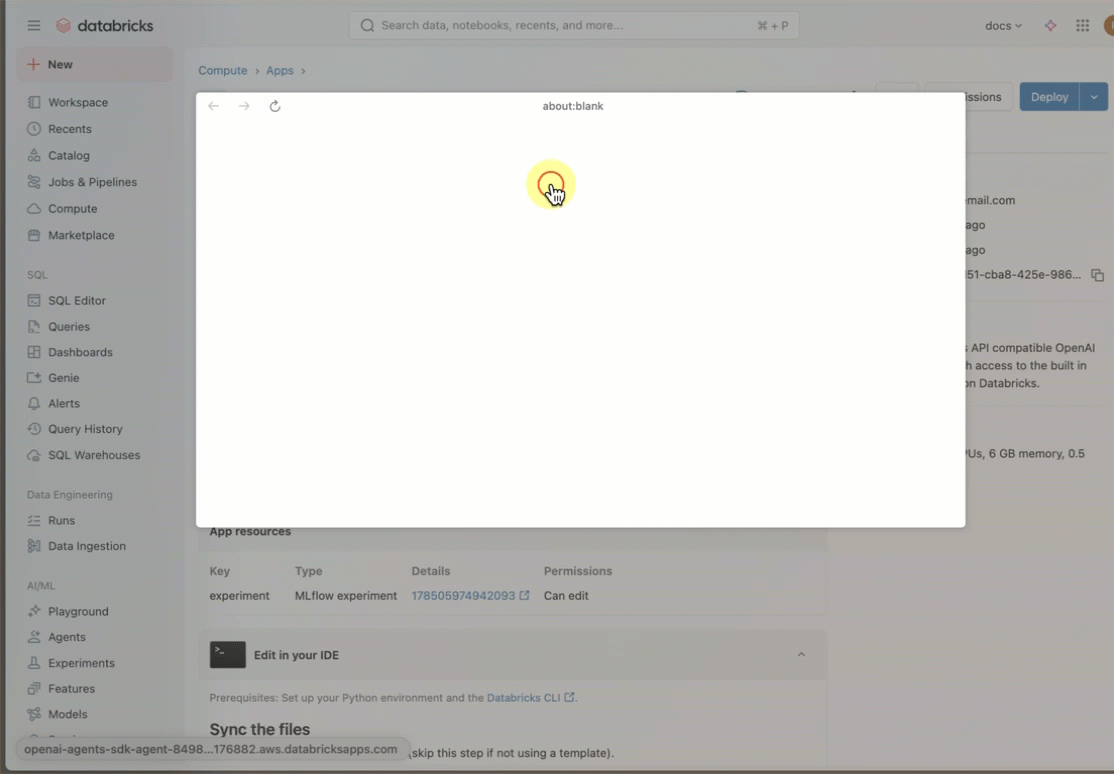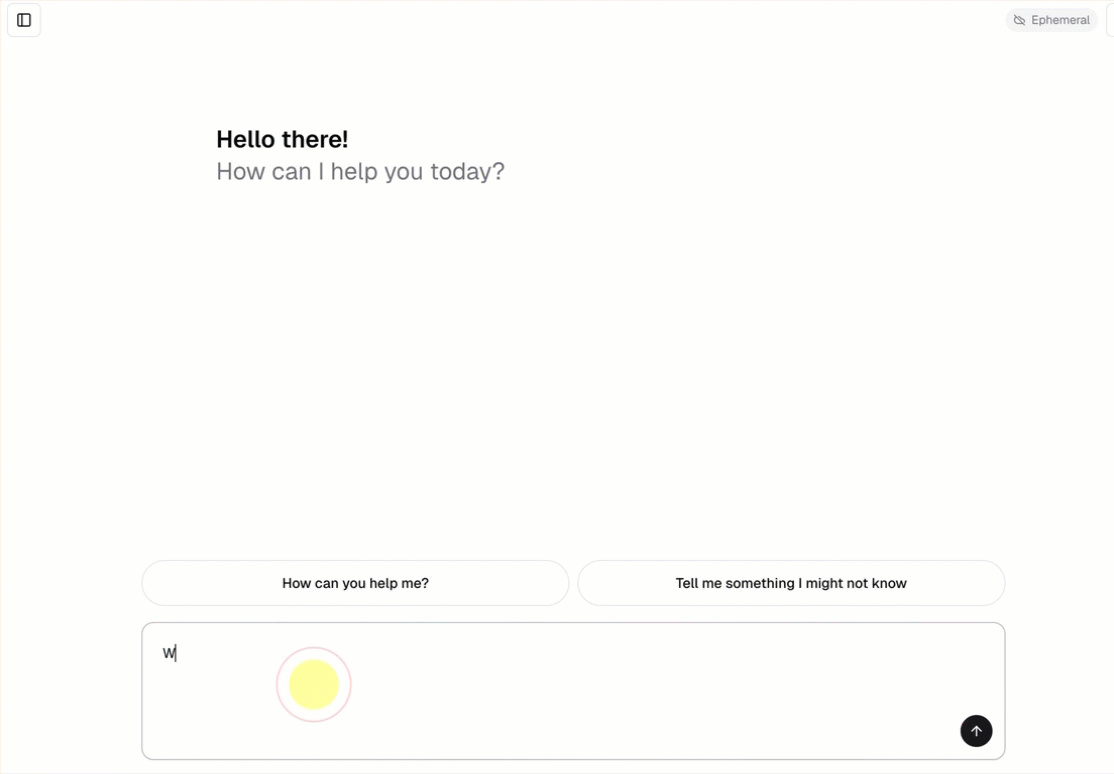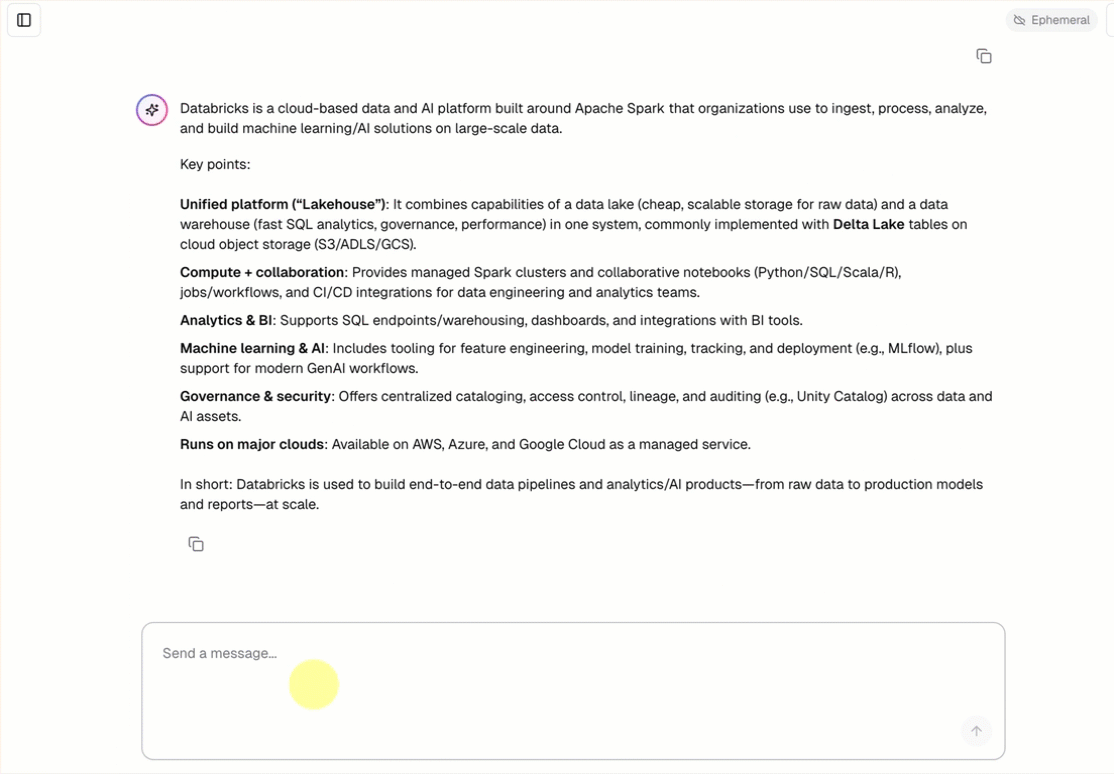
すべての会話エージェント テンプレートには、追加の設定を必要としない組み込みのチャット UI (上記に表示) が含まれています。チャット UI は、ストリーミング応答、マークダウン レンダリング、Databricks 認証、オプションの永続的なチャット履歴をサポートします。
必要条件
ワークスペースでDatabricks Apps有効にします。 Databricks Appsワークスペースと開発環境をセットアップするを参照してください。
ステップ 1. エージェント アプリ テンプレートのクローンを作成します
Databricks アプリ テンプレート リポジトリから事前に構築されたエージェント テンプレートを使用して開始します。
このチュートリアルでは、次の内容を含むagent-openai-agents-sdkテンプレートを使用します。
- OpenAI Agent SDKを使用して作成されたエージェント
- 会話型 REST API と対話型チャット UI を備えたエージェント アプリケーションのスターター コード
- MLflowを使用してエージェントを評価するコード
テンプレートを設定するには、次のいずれかのパスを選択します。
- Workspace UI
- Clone from GitHub
ワークスペース UI を使用してアプリ テンプレートをインストールします。 これにより、アプリがインストールされ、ワークスペース内のコンピュート リソースにデプロイされます。 その後、アプリケーション ファイルをローカル環境に同期して、さらに開発を進めることができます。
-
Databricks ワークスペースで、 [+ 新規] > [アプリ] をクリックします。
-
「エージェント」 > 「カスタムエージェント(OpenAI SDK)」 をクリックします。
-
openai-agents-templateという名前で新しいMLflowエクスペリメントを作成し、残りのセットアップを完了してテンプレートをインストールします。 -
アプリを作成したら、アプリの URL をクリックしてチャット UI を開きます。
アプリを作成したら、ソース コードをローカル マシンにダウンロードしてカスタマイズします。
-
ファイルの同期 の最初のコマンドをコピーします
-
ローカル ターミナルで、コピーしたコマンドを実行します。
ローカル環境から開始するには、エージェント テンプレート リポジトリのクローンを作成し、 agent-openai-agents-sdkディレクトリを開きます。
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
ステップ 2. エージェント アプリケーションを理解する
エージェント テンプレートは、これらの主要なコンポーネントを備えた本番運用対応のアーキテクチャを示しています。 各コンポーネントの詳細については、次のセクションを参照してください。

各コンポーネントの詳細については、次のセクションを参照してください。
 組み込みチャットUI
組み込みチャットUI
エージェント テンプレートは、チャット アプリ テンプレートをフロントエンドとして自動的に取得して実行します。このチャット UI は同じ Databricks Apps デプロイメントにバンドルされ、エージェントと一緒に提供されるため、追加のセットアップは必要ありません。
プロジェクト内でチャット UI を直接カスタマイズできます。永続的なチャット履歴やユーザー フィードバックの収集を有効にする方法など、チャット アプリの機能の詳細については、 Databricks Appsを使用してチャット UI を構築および共有する」を参照してください。
 MLflow エージェントサーバー
MLflow エージェントサーバー
組み込みのトレースと監視機能を使用してエージェント要求を処理する非同期 FastAPI サーバー。AgentServer は、エージェントを照会するための/responsesエンドポイントを提供し、リクエストのルーティング、ログ記録、およびエラー処理を自動的に管理します。

ResponsesAgentインターフェース
ResponsesAgentインターフェースDatabricks では、エージェントの構築に MLflow ResponsesAgentを推奨しています。ResponsesAgent使用すると、任意のサードパーティ フレームワークを使用してエージェントを構築し、それをDatabricks AI機能と統合して、強力なログ記録、トレース、評価、展開、モニタリング機能を実現できます。

ResponsesAgent作成方法については、 MLflowドキュメントの例 (ResponsesAgent for モデルサービング)を参照してください。
ResponsesAgent 次の利点があります。
-
高度なエージェント機能
- マルチエージェントのサポート
- ストリーミング出力 : 出力を小さなチャンクでストリームします。
- 包括的なツール呼び出しメッセージ履歴 : 中間ツール呼び出しメッセージを含む複数のメッセージを返し、品質と会話管理を向上させます。
- ツールコール確認支援
- 長期実行ツールのサポート
-
開発、デプロイ、モニタリングの効率化
- 任意のフレームワークを使用してエージェントを作成する :
ResponsesAgentインターフェイスを使用して既存のエージェントをラップし、 AI Playground、エージェント評価、エージェントモニタリングとのすぐに使用できる互換性を実現します。 - 型付きオーサリングインターフェイス :型付きPythonクラスを使用してエージェントコードを記述し、IDEとノートブックのオートコンプリートの恩恵を受けます。
- 自動トレース : MLflow は、ストリームされた応答をトレースに自動的に集約し、評価と表示を容易にします。
- OpenAI
Responsesスキーマと互換性があります 。OpenAI : Responses vs. ChatCompletion を参照してください。
- 任意のフレームワークを使用してエージェントを作成する :
 OpenAI エージェント SDK
OpenAI エージェント SDK
このテンプレートは、会話管理とツール オーケストレーションのエージェント フレームワークとしてOpenAI Agents SDK を使用します。任意のフレームワークを使用してエージェントを作成できます。重要なのは、エージェントを MLflow ResponsesAgentインターフェースでラップすることです。
 MCP(モデルコンテキストプロトコル)サーバー
MCP(モデルコンテキストプロトコル)サーバー
テンプレートはDatabricks MCP サーバーに接続し、エージェントがツールやデータ ソースにアクセスできるようにします。 Databricks のモデル コンテキスト プロトコル (MCP) を参照してください。
AIコーディングアシスタントを活用したエージェントの開発
Databricks では、エージェントを作成するために、Claude、Cursor、Copilot などの AI コーディング アシスタントの使用を推奨しています。/.claude/skillsとAGENTS.mdファイルで提供されているエージェント スキルを使用して、AI アシスタントがプロジェクト構造、利用可能なツール、ベスト プラクティスを理解できるようにします。エージェントはこれらのファイルを自動的に読み取り、 Databricks Apps開発および展開できます。
ステップ 3. エージェントにツールを追加する
エージェントをMCPサーバーに接続することで、データベースへのクエリ実行、ドキュメント検索、外部APIs呼び出しといった機能をエージェントに付与できます。 エージェントテンプレートには、デフォルトのMCPサーバー接続が含まれています。ツールを追加するには、エージェントコードで追加の MCP サーバーを設定し、 databricks.ymlで必要な権限を付与します。
サポートされているツールタイプとコード例については、 AIエージェントツールを参照してください。
ローカルのPython関数ツールを定義する
外部データソースやAPIs必要としない操作の場合は、エージェント コードでツールを直接定義します。 これらのツールはエージェントと同じプロセスで実行され、データ変換、計算、またはユーティリティ操作に役立ちます。
- OpenAI Agents SDK
- LangGraph
OpenAI Agents SDKの@function_toolデコレータを使用してください。
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
LangChainの@toolデコレータを使用します。
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
ローカル関数ツールは、エージェントプロセス内で実行されるため、 databricks.ymlでのリソース付与を必要としません。
ステップ 4. Unity AI Gateway を使用してDatabricks Apps上のエージェントからのLLM使用を管理する
エージェントのLLMコールをUnity AI Gateway(ベータ版)経由でルーティングすることで、どのプロバイダーが応答しても、すべてのリクエストが同じ制御によって管理されるようになります。リクエストパスにゲートウェイを配置することで、エージェントコードを変更したりプロバイダーの認証情報をローテーションしたりすることなく、権限の一元管理、アプリごとのコスト属性設定、スワップモデルの作成、トラフィックの検査や再生が可能になります。
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。Databricksのプレビューを管理するを参照してください。
-
ワークスペースでUnity AI Gatewayを有効にしてください。Unity AI Gatewayはベータ版期間中はオプトイン方式です。ゲートウェイエンドポイントを作成または照会するには、アカウント管理者がアカウントコンソールの プレビュー ページからこの機能を有効にする必要があります。Databricksのプレビューを管理するを参照してください。
-
エージェントをUnity AI Gatewayのエンドポイントに接続してください。エージェントコードでは、Unity AI Gatewayのエンドポイント名を引数
modelとして渡し、Databricks LLMクライアントでuse_ai_gateway=Trueを設定してください。クライアントはゲートウェイを経由してトラフィックをルーティングし、認証を自動的に処理します。
- OpenAI
- LangGraph
from agents import Agent, set_default_openai_api, set_default_openai_client
from databricks_openai import AsyncDatabricksOpenAI
set_default_openai_client(AsyncDatabricksOpenAI(use_ai_gateway=True))
set_default_openai_api("chat_completions")
agent = Agent(
name="Agent",
instructions="You are a helpful assistant.",
model="<ai-gateway-endpoint>",
)
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(
model="<ai-gateway-endpoint>",
use_ai_gateway=True,
)
その他の API サーフェス (OpenAI Responses API、Anthropic Messages API、Google Gemini) および REST の例については、 「Unity AI Gateway エンドポイントのクエリ」を参照してください。
高度なオーサリングトピック
ストリーミング応答
ストリーミング応答
ストリーミングを使用すると、エージェントは完全な応答を待つ代わりに、リアルタイムのチャンクで応答を送信できます。ResponsesAgentを使用してストリーミングを実装するには、一連のデルタイベントとそれに続く最終完了イベントを発行します。
- デルタイベントを出力する : 同じ
item_idで複数のoutput_text.deltaイベントを送信して、 ストリームテキストチャンク リアルタイム。 - 完了イベントで終了 : 完全な最終出力テキストを含むデルタ イベントと同じ
item_idで最終response.output_item.doneイベントを送信します。
各デルタ イベントは、テキストのチャンクをクライアントにストリームします。 最終的な done イベントには完全な応答テキストが含まれ、Databricks に次の操作を行うように通知します。
- MLflow トレースを使用してエージェントの出力をトレースする
- Unity AI Gatewayの推論テーブルにストリーム応答を集約する
- AI Playground UI で完全な出力を表示する
ストリーミングエラーの伝播
Databricks は、 databricks_output.errorの下の最後のトークンを使用してストリーミング中に発生したエラーを伝播します。このエラーを適切に処理し、表示するのは、呼び出し元のクライアントの責任です。
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
カスタム入力と出力
カスタム入力と出力
一部のシナリオでは、 client_type や session_idなどの追加のエージェント入力や、将来の対話のためにチャット履歴に含めるべきではない取得ソースリンクなどの出力が必要になる場合があります。
これらのシナリオでは、MLflow ResponsesAgentはフィールドcustom_inputsとcustom_outputsをネイティブにサポートします。上記のフレームワークの例では、 request.custom_inputsを介してカスタム入力にアクセスできます。
エージェント評価レビューアプリは、追加の入力フィールドを持つエージェントのレンダリングトレースをサポートしていません。
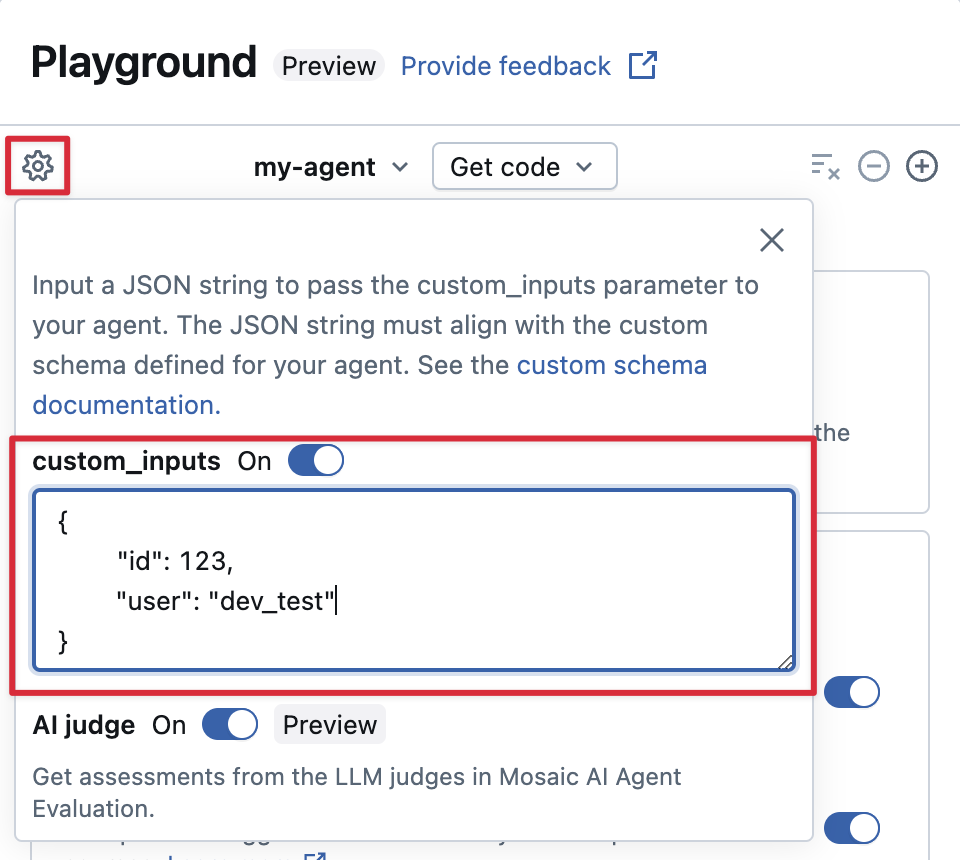
AI Playgroundとレビューアプリでcustom_inputsを提供します
エージェントが custom_inputs フィールドを使用して追加の入力を受け入れる場合は、 AI Playground と レビューアプリの両方でこれらの入力を手動で提供できます。
-
AI Playground または Agent Review App で、歯車アイコン
 を選択します。
を選択します。 -
custom_inputs を有効にします。
-
エージェントの定義済み入力スキーマに一致するJSONオブジェクトを提供します。
ステップ 5. エージェント アプリをローカルで実行する
ローカル環境を設定します。
-
uv(Python パッケージ マネージャー)、nvm(Node バージョン マネージャー)、および Databricks CLI をインストールします。uvインストールnvmインストール- Node 20 LTS を使用するには、以下を実行します。 ```bash
nvm use 20
databricks CLIインストール
-
ディレクトリを
agent-openai-agents-sdkフォルダーに変更します。 -
提供されているクイックスタート スクリプトを実行して依存関係をインストールし、環境をセットアップしてアプリを起動します。
Bashuv run quickstart
uv run start-app
ブラウザでhttp://localhost:8000にアクセスし、組み込みのチャット UI を開いてエージェントとのチャットを開始します。
ステップ 6. 認証を構成する
エージェントがDatabricksリソースにアクセスするには認証が必要です。 Databricks Appsは、アプリ認証(サービスプリンシパル)とユーザー認証(ユーザー代理)の2つの認証方法を提供します。ワークスペースのUIを通して設定することも、宣言型自動化バンドルを使用してdatabricks.ymlで宣言的に設定することもできます。エージェントテンプレートにはdatabricks.ymlが含まれているため、テンプレートから開始する場合、そのパスがデフォルトになります。
サポートされているすべてのリソース タイプ、権限値、エンドツーエンドdatabricks.ymlウォークスルーを含む完全なリファレンスについては、 「AI エージェントの認証」を参照してください。
- App authorization (default)
- User authorization
アプリの承認では、 Databricksアプリ用に自動的に作成するサービスプリンシパルを使用します。 すべてのユーザーは同じ権限を共有します。
databricks.ymlのresources.apps.<app>.resourcesの下に、エージェントが使用するすべてのリソースを宣言します。サービスプリンシパルに宣言された権限を付与するためにバンドルをデプロイします。
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
config:
command: ['uv', 'run', 'start-app']
env:
- name: MLFLOW_TRACKING_URI
value: 'databricks'
- name: MLFLOW_REGISTRY_URI
value: 'databricks-uc'
- name: MLFLOW_EXPERIMENT_ID
value_from: 'experiment'
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
リソースタイプの全リストについては、 「アプリの認証」を参照してください。
ユーザー認証により、エージェントは各ユーザーの個別の権限で動作できるようになります。ユーザーごとのアクセス制御や監査証跡が必要な場合に使用します。
エージェントに次のコードを追加します:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
get_user_workspace_client() 、アプリの起動時ではなく、 @invokeまたは@stream関数内で初期化してください。ユーザー認証情報は、リクエストを処理する際にのみ存在します。
エージェントがユーザーに代わって呼び出すことができるDatabricks APIs設定するには、 databricks.ymlのアプリのuser_api_scopesの下にスコープを追加します。
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
user_api_scopes:
- sql
- dashboards.genie
- serving.serving-endpoints
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
利用可能なスコープの一覧と完全な設定手順については、 「ユーザー認証」を参照してください。
ステップ 7. エージェントを評価する
テンプレートにはエージェント評価コードが含まれています。詳細については、 agent_server/evaluate_agent.pyを参照してください。 ターミナルで次のコマンドを実行して、エージェントの応答の関連性と安全性を評価します。
uv run agent-evaluate
ステップ 8. エージェントをDatabricks Appsにデプロイする
認証設定後、エージェントをDatabricksにデプロイします。エージェントテンプレートは、デプロイメントにDatabricksアセットバンドル(DAB)を使用します。テンプレート内のdatabricks.ymlファイルは、アプリの設定とリソースのアクセス許可を定義します。Databricks CLIがインストールされ、正しく設定されていることを確認してください。
ステップ 1 でワークスペース UI を通じてアプリを作成した場合は、デプロイする前に実行databricks bundle deployment bind agent_openai_agents_sdk <app-name> --auto-approveして、既存のアプリをバンドルにバインドします。 それ以外の場合、 databricks bundle deploy 「同じ名前のアプリが既に存在します」というエラーで失敗します。
-
デプロイ前にバンドル構成を検証してエラーを検出します。
Bashdatabricks bundle validate -
バンドルをデプロイします。これにより、コードがアップロードされ、
databricks.ymlで定義されたリソース ( MLflowエクスペリメント、サービス提供エンドポイントなど) が構成されます。Bashdatabricks bundle deploy -
アプリを起動または再起動する:
Bashdatabricks bundle run agent_openai_agents_sdk
bundle deploy ファイルのアップロードとリソースの設定のみを行います。新しいコードを使用してアプリを起動または再起動するには、 bundle runが必要です。
今後のアップデートについては、 databricks bundle deploy実行してからdatabricks bundle run agent_openai_agents_sdkを実行して再デプロイしてください。
ステップ 9. デプロイされたエージェントをクエリする
次の例では、 OAuthを使用したクイックcurlリクエストを使用しています。 Databricks Appsでは、パーソナル アクセストークン (PAT) はサポートされていません。
Databricks OpenAI Client や REST API を含むクエリ方法の全リストについては、 「Databricks にデプロイされたエージェントをクエリする」を参照してください。
Databricks CLI を使用して OAuth トークンを生成します。
databricks auth login --host <https://host.databricks.com>
databricks auth token
トークンを使用してエージェントにクエリを実行します。
curl -X POST <app-url.databricksapps.com>/responses \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
制限事項
- 中および大のコンピュート サイズのみがサポートされています。 Databricksアプリのコンピュート リソースの構成」を参照してください。
- MLflow Review App Chat UI は現在、 Databricks Appsにデプロイされたエージェントをサポートしていません。 既存のトレースを評価するには、展開方法に関係なく機能するラベル付けセッションを使用します。Databricks は、チャットボット テンプレートにレビューとフィードバックのサポートを直接組み込んでいます。
次のステップ
エージェントが開発に取り組んだら、本番運用に移行します。 推奨される手順については、 「Databricks Appsエージェントを本番環境に導入する」を参照してください。手順は、CI/CD、負荷テスト、そしてUnity AI Gatewayの順です。