パイプライン開発に Genie Code を使用する
プレビュー
この機能は パブリック プレビュー段階です。
Genie Codeのエージェントモードは、LakeFlow Pipelines Editorのデベロッパー向けのAIデータエンジニアリングパートナーです。データを探索し、パイプラインコードを生成してランし、単一のプロンプトからエラーを修正します。
このページでは、Genie Codeを使用して、Lakeflow (SDP) パイプラインでSpark宣言型パイプラインを開発および移行する方法について説明します。T-SQL、Snowflake、Oracleなどの他のダイアレクトからレガシーSQLをANSI SQLに変換するには、代わりにLakebridge Agentic Converterを使用します。「Lakebridge Agentic ConverterでSQLを変換します」を参照してください。
パイプライン開発における Genie Code とは何ですか?
エージェントモードのGenie Codeは、Lakeflow Pipelines Editor で複数ステップのデータエンジニアリングワークフロー全体を自動化できる自律的なパートナーです。
Genie Code のチャット モードと比較して、エージェント モードには、ソリューションの計画、関連アセットの取得、コードの実行、パイプライン出力を使用した結果の改善、エラーの自動修正などの機能が拡張されています。
エージェント モードのGenie Codeは、パイプライン全体を最初からエンドツーエンドで計画および生成したり、既存のパイプラインでの作業を加速したりできます。 エージェントはお客様と協力して計画を承認し、次のステップを確認してから続行します。承認されると、Genie Code はツールを使用して、テーブルの検索、SQL または Python ソース ファイルの編集、パイプラインの更新の実行、パイプライン データセットの読み取りなどのタスクを実行できます。
Genie Code のアクセスとアクションは、ユーザーの権限によって制御されます。アクセス権のあるデータにのみアクセスでき、権限のある操作のみを実行できます。
Genie Code でエージェント モードをオンにすると、Genie Code は Databricks で現在使用している機能に基づいて機能を調整します。たとえば、 LakeFlow Pipelines Editor では、 Genie Code はパイプライン編集とデータエンジニアリングタスクに重点を置いています。 ノートブックと SQL エディターでは、Genie Code がデータの探索と分析をサポートします。詳細については、「データ サイエンスにGenie Codeを使用する」を参照してください。
要件
データエンジニアリングにGenie Code を使用するには、ワークスペースに次のものが必要です。
- パートナーが提供する AI 機能がアカウントとワークスペースの両方で有効になっていること。パートナーが提供する AI 機能をご覧ください。
- ワークスペースは、サポートされているリージョン内に配置する必要があります。Genie Codeは、Geosを使用してデータ所在地の管理を行う指定サービスです。Genie Code機能のGeo別利用可能状況については、こちらをご覧ください。
パイプライン開発に Genie Code を使用する
パイプライン開発に Genie Code のエージェント機能を使用するには:
-
LakeFlow Pipelines エディターから、ワークスペースの右上隅にある
 Genie Code をクリックして、Genie Code サイドパネルを開きます。
Genie Code をクリックして、Genie Code サイドパネルを開きます。 -
右下隅に Agent を選択します。これにより、Genie Codeのエージェントモードが有効になり、そのエージェント型データエンジニアリング機能を使用できるようになります。
-
Genie Code のプロンプトを入力します。たとえば、「このパイプラインについて説明してください」など、パイプラインに関する質問をすることができます。また、「bronze_sales_data から読み取り、データをクリーンアップし、有用な品質期待値を追加する新しいファイルに silver_sales_data を作成する」など、新しいデータセットを追加するように要求することもできます。
Genie Code はユーザーのUnity Catalog権限を尊重するため、ユーザーがアクセスできるデータとパイプライン ソースにのみアクセスできます。
-
Genie Code が応答を生成すると、入力の取得が停止することがよくあります。
-
より複雑なタスクの場合、Genie Code は段階的な計画を作成し、明確にするための質問をすることがあります。明確な質問に答えて、計画を洗練させましょう。
-
Genie Code がコードを実行したり、パイプラインを更新する必要がある場合、続行する前に、承認を求めます。その要求を 許可 または 拒否 します。 このスレッドで許可する (Genie Codeの会話スレッドを参照)または 常に許可する を選択することもできます。
-
エージェント モードの Genie Code は、パイプラインでコードを生成して実行できます。危険な行為を防ぐためのガードレールはありますが、それでもリスクは残ります。信頼できるデータにのみ使用し、実行する前にコードを確認する必要があります。
-
Genie Code が作業を続行すると、 [続行] または [拒否] を選択するように求められる場合があります。 既存の作業を確認し、次のステップに進む場合は 「続行」 を選択し、別の作業を試す場合は 「拒否」を 選択します。
-
Genie Codeの動作中に停止するには、赤い
 。
。
Genie Code は、新しいファイルを作成したり、テキスト、クエリ、コードを生成したり、ファイルまたはパイプラインを実行したり、出力データセットにアクセスして結果を解釈したりできます。
Genie Code が作業を続行して次のステップに進むためには、現在作業中のタブに留まる必要があります。
Genie Codeがほとんどの回答で利用する指示を追加できます。例えば、使用したいコード規約や推奨ライブラリがある場合は、これらのガイドラインをGenie Codeへの指示として追加できます。Genie Code の機能を拡張するために、ドメイン固有のタスクに特化した機能を持つスキルを作成することもできます。詳細やその他のヒントについては、「Genie Code の応答を改善するためのヒント」を参照してください。
エージェントモードの機能
エージェント モードでは、Genie Code がほとんどのパイプライン開発タスクを支援します。主な機能は次のとおりです。
- データ割り当て : Genie Code は、ワークスペース内のテーブルを検索して、タスクに必要なデータを見つけるのに役立ちます。
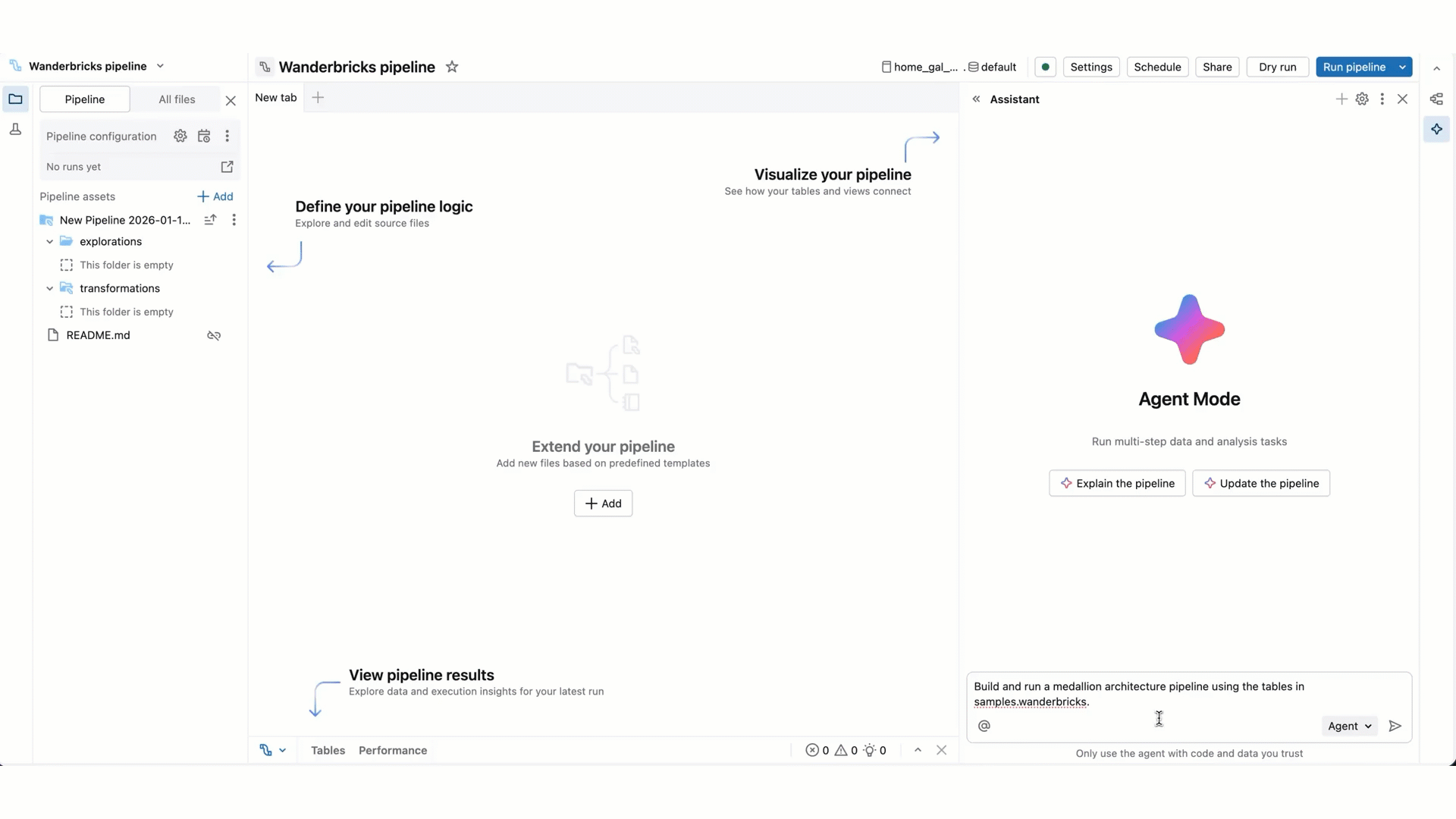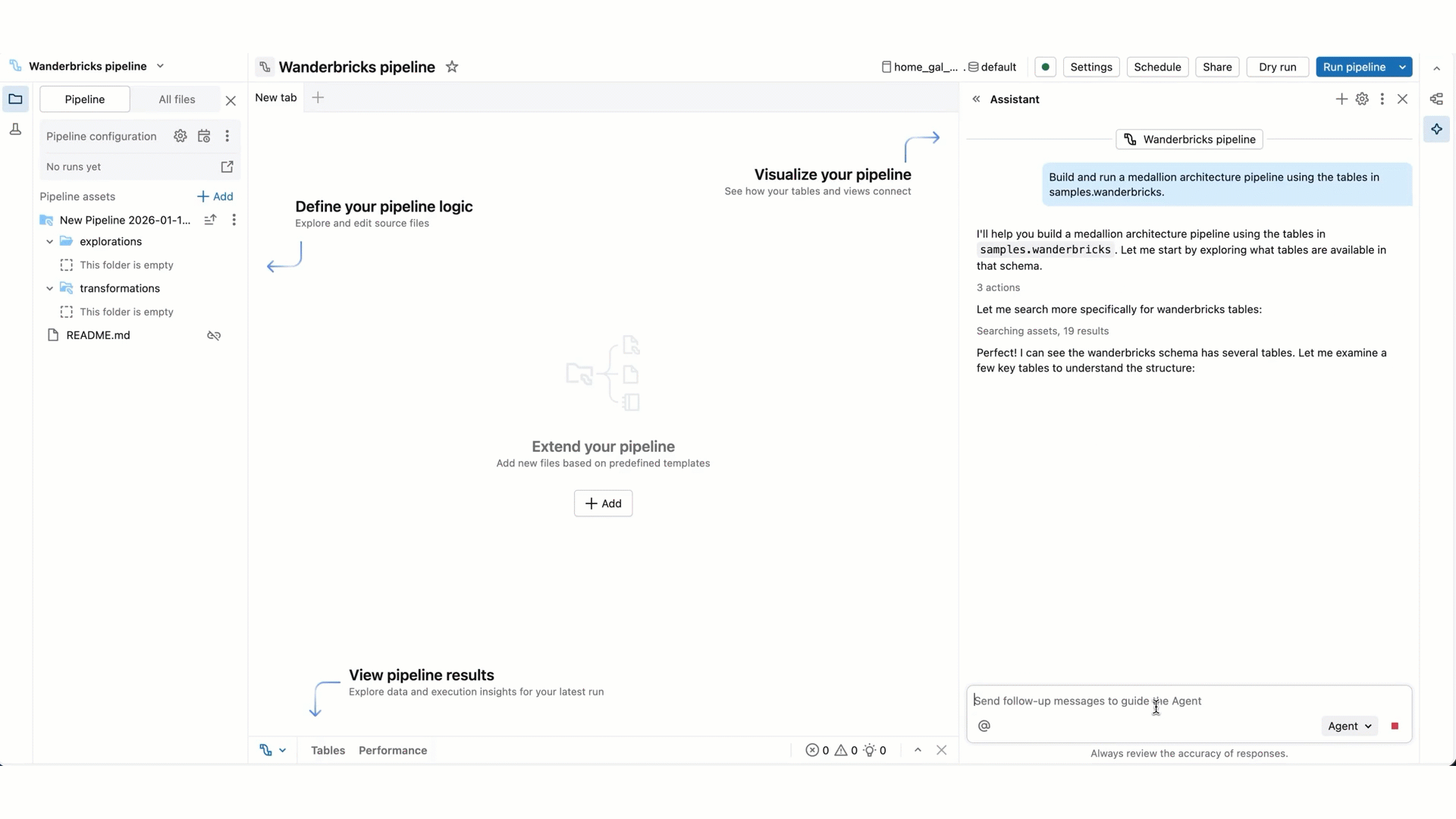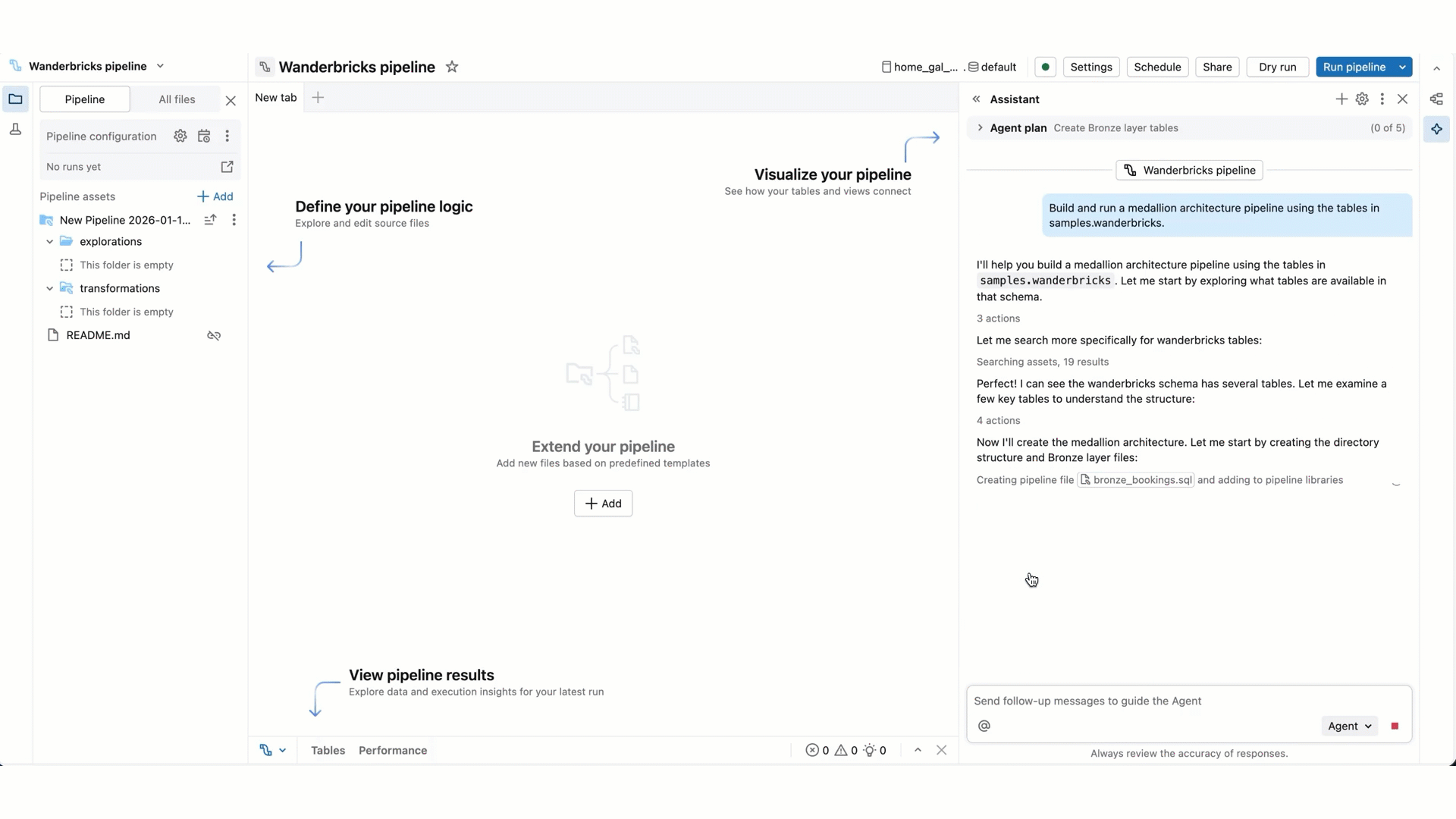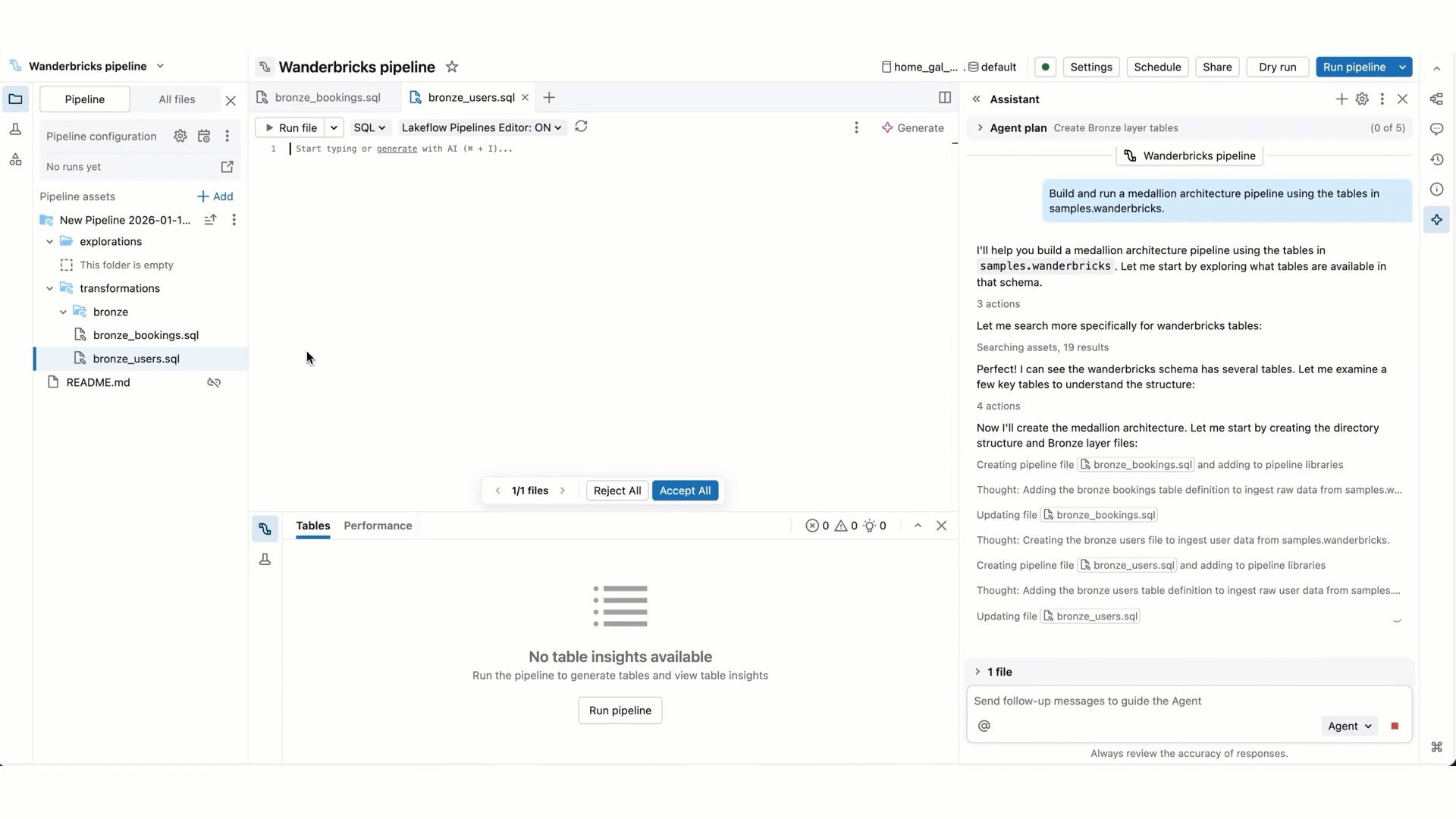
- パイプライン コード編集 : Genie Code では、一度に複数のファイルを作成および編集できます。どのファイルが変更されているかを通知し、各ファイルのコード差分を表示するので、変更を個別に確認したり、最後にまとめて確認したりできます。
- パイプラインの実行 : Genie Code は、個々のファイルを実行したり、パイプラインをドライ実行/実行したり、完全な更新を実行したりできます。 Genie Code が処理を続行しようとする場合、処理を実行する前に確認を求められます。
- パイプラインの動作の理解と改善 : Genie Code はデータセットとパイプラインの出力を検査して、パイプラインがエンドツーエンドで何を実行しているのか、またその理由を理解するのに役立ちます。たとえば、変換を要約したり、データが下流のテーブルにどのように流れるかを追跡したり、行数やスキーマの予期しない変更を強調表示したりできます。潜在的なデータ品質の問題が明らかになった場合、Genie Code は、その原因を推論し、パイプラインのどこでどのように対処するかを提案するのに役立ちます。
これらの機能は、次のような一般的なユースケースをサポートします。
- 新しいパイプラインの作成 : Genie Code は、データの取り込みから、データの標準化とクリーニング、データの変換と分析まで、新しいメダリオンアーキテクチャ パイプラインの作成のすべてのステップに役立ちます。
- パイプラインの説明 : Genie Code は既存のパイプラインを分析して説明し、迅速な立ち上げを支援します。
- 問題の修正 : エラーが発生した場合、Genie Code は、問題が解決されるまで複数のファイルを反復処理して、問題の診断と修正を支援します。
他のETLフレームワークからLakeFlow Pipelinesへの移行
ベータ版
この機能はベータ版です。
Genie Code は、既存のデータ変換プロジェクトを LakeFlow Pipelines に移行できます。You point it at your upload project, and it plans and runs the migration end-to-end.この移行機能はLakebridgeの一部であり、Lakebridge Switchトランスパイラからも利用できます。
移行は現在、dbtおよびInformaticaプロジェクトのみをサポートしています。追加のソースのサポートが計画されています。
プロジェクトを移行する
-
プロジェクトをDatabricksにアップロードします。 以下のいずれかを使用します。
- カタログ :ボリュームを開き、次に このボリュームにアップロード します。
- ワークスペース : ディレクトリを開き、
 > インポート をクリックします。
> インポート をクリックします。
-
空のLakeflow パイプラインを作成します。 ジョブとパイプライン に移動し、 ETL パイプライン を作成します。
-
Genie Codeにそれを移行するよう依頼します。 Genie Codeを開き、アップロードしたプロジェクトのパスでプロンプトを表示します。例:
/Volumes/my_catalog/my_schema/my_volume/my_projectにあるプロジェクトを移行する
移行の仕組み
移行を開始すると、Genie Codeがプランを生成し、それを実行します:
- ソースを読み取ります。 ソースプロジェクトを読み取り、そのモデル、変換、および依存関係を理解します。
- 入力を収集します。 SQLまたはPythonパイプラインソースを生成するかどうかなど、必要な入力を求めます。
- 中間表現(IR)を調査して生成します。 プロジェクトを分析し、ソースツールに依存しないパイプラインのロジックをキャプチャする中間表現を構築します。
- 変換、検証、および修復。 IRをパイプラインソースに変換し、結果を検証し、パイプラインが正しくなるまで修復ループで反復処理します。
移行されたパイプラインソースを確認し、パイプラインを実行して、本番運用で信頼する前に結果が元のプロジェクトと一致することを確認してください。
例
開始するには、次のプロンプトを試してください。
- 「my_catalog.my_schema のテーブル トランザクションとカスタマーを使用して、不正検出のためのメダリオンアーキテクチャ パイプラインを構築して実行します。」
- 「このパイプラインのすべてのステップを説明してください。」
- 「このパイプラインの障害を修正してください。」
その他のリソース
- Databricks AI 支援機能の詳細
- Genie Codeの応答を改善するためのヒントを入手する
- データ発見、探索にGenie Code for data scienceを使用する
- ダッシュボードの作成にGenie Codeを使用する
- LakeFlow Pipelinesエディターを探索する