チュートリアル:異なるパラメーターで複数のフローを作成する
パイプラインには、ほぼ同一の複数のフローが含まれている場合がありますが、異なるのはわずかなパラメーターだけです。これらのフローを明示的に定義することは、エラーが発生しやすく、冗長で、保守が困難です。Pythonの内部関数によるメタプログラミングは、各呼び出しで異なるパラメーターセットを供給し、反復的なフローを動的に生成します。
メタプログラミングの概要
Lakeflow Pipelinesにおけるメタプログラミングでは、Pythonの内部関数を使用します。これらの関数はパイプラインランタイムによって遅延評価されるため、@dp.tableデコレータをファクトリ関数内にラップし、そのファクトリを異なる引数で複数回呼び出すことができます。各呼び出しは、コードを複製せずに新しいフローを登録します。
LakeFlow Pipelinesで for ループを使用する方法の詳細については、for ループでテーブルを作成するを参照してください。
例:消防署の出動時間
次の例では、組み込みの消防署データセットを使用して、通報の種類ごとに緊急対応時間が最も速い地域を特定します。メタプログラミングを使用しない場合、各コールタイプ(警報、建物火災、医療事案)ごとにほぼ同じテーブル定義を作成する必要があります。メタプログラミングでは、単一のファクトリ関数でそれらすべてを生成します。
ステップ 1: 生の取り込みテーブルを定義する
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
ステップ 2: フローファクトリー関数を定義する
generate_tablesファクトリ関数登録は、各呼び出しタイプごとに2つのテーブル(フィルタリングされた呼び出しテーブルとランク付けされた応答時間テーブル)を使用します。 どちらも@dp.tableで装飾された内部関数として作成されます。
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
ステップ 3: ファクトリを呼び出して概要テーブルを定義する
各呼び出しタイプごとにファクトリを一度呼び出し、その後、結果を統合して、すべてのカテゴリで最も頻繁に出現する地域を見つけるサマリーテーブルを定義します。
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
このパイプラインを実行すると、このグラフに示すような類似のテーブルのセットが作成されます。
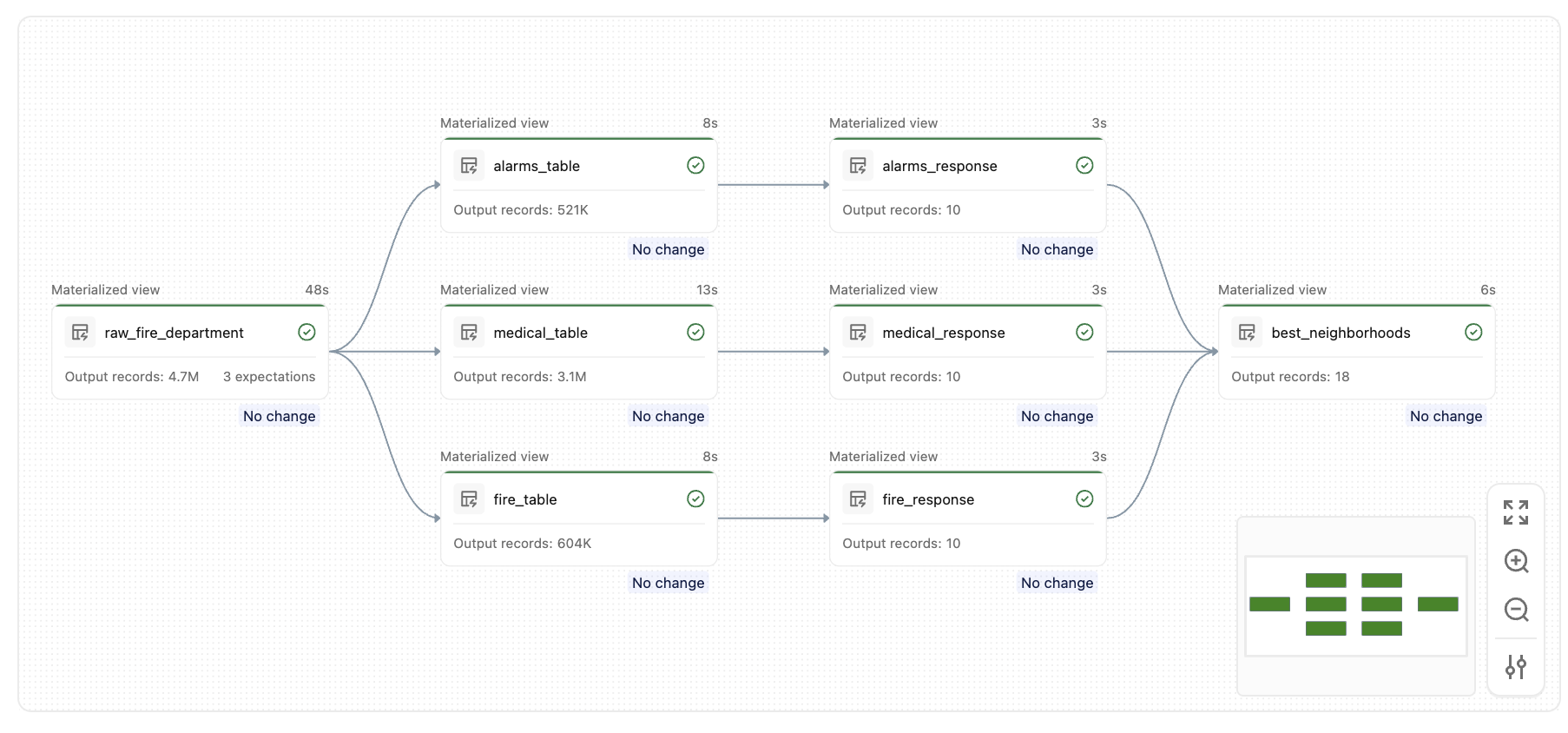
主要概念
- 内部関数は遅延登録されます 。
@dp.tableデコレータは関数をすぐには実行しません。パイプライン ランタイムを使用して関数を登録します。これは、実行が開始される前に完全なデータフロー グラフを解決します。 - クロージャのキャプチャ : 各内部関数はファクトリ (
call_table、response_table、filter) に渡された問題を超えてクローズされるため、登録された各フローは独自の分離された値のセットを使用します。 - 動的なテーブルリスト : プログラムで生成されたテーブル名を追跡するために
all_tablesのようなリストを使用すると、後でそれらを簡単に参照できます (たとえば、ユニオンやジョイン内)。