パイプラインによるヒストリカルデータの埋め戻し
データエンジニアリングでは、 バックフィルと は、現在のデータまたはストリーミング データを処理するために設計されたパイプ データラインを通じて履歴データを遡及的に処理するプロセスを指します。
通常、これは既存のテーブルにデータを送信する別のフローです。次の図は、パイプライン内のブロンズ テーブルにヒストリカル データを送信するバックフィル フローを示しています。
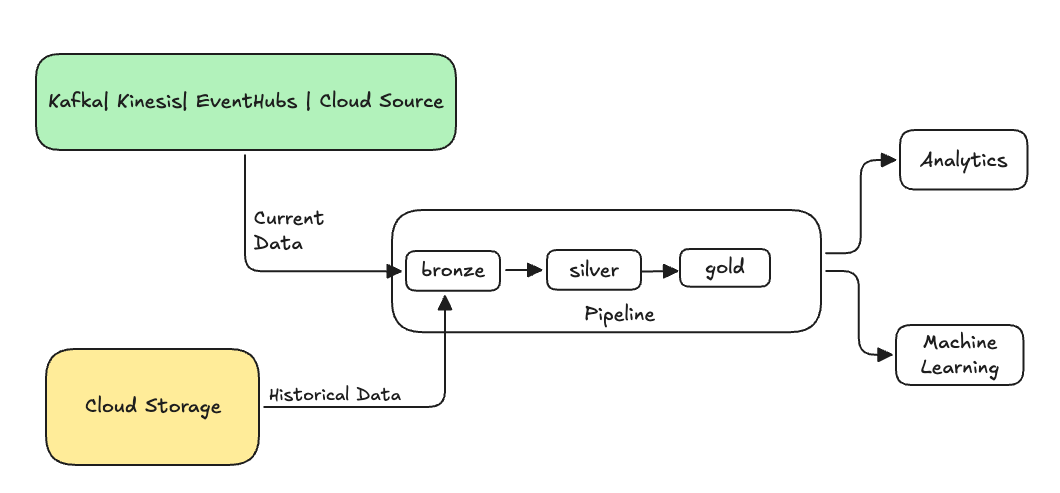
バックフィルが必要になる可能性があるシナリオ:
- レガシー システムからの履歴データを処理して機械学習 ( ML ) モデルをトレーニングしたり、履歴傾向分析ダッシュボードを構築したりできます。
- アップストリーム データ ソースのデータ品質の問題のため、データのサブセットを再処理します。
- ビジネス要件が変更されたため、最初のパイプラインでカバーされていなかった別の期間のデータをバックフィルする必要があります。
- ビジネス ロジックが変更されたため、履歴データと現在のデータの両方を再処理する必要があります。
LakeFlow Pipelinesでのバックフィルは、ONCEオプションを使用する特殊な追加フローでサポートされています。ONCEオプションに関する詳細情報については、append_flowまたはCREATE FLOW (パイプライン)を参照してください。
履歴データをストリーミング テーブルにバックフィルする際の考慮事項
- 通常は、Bronze ストリーミング テーブルにデータを追加します。 下流のシルバーとゴールドレイヤーは、ブロンズレイヤーから新しいデータを取得します。
- 同じデータが複数回追加された場合に、パイプラインが重複データを適切に処理できることを確認します。
- 履歴データ スキーマが現在のデータ スキーマと互換性があることを確認してください。
- データ ボリュームのサイズと必要な処理時間の SLA を考慮し、それに応じてクラスターとバッチ サイズを構成します。
例: 既存のパイプラインにバックフィルを追加する
この例では、2025 年 1 月 1 日からクラウド ストレージ ソースから生のイベント登録データを取り込むパイプラインがあるとします。後で、下流のレポート作成と分析のユースケースのために、過去 3 年間の履歴データをバックフィルしたいことに気づきました。 すべてのデータは 1 つの場所に保存され、JSON 形式で年、月、日ごとに分割されます。
初期パイプライン
以下は、クラウド ストレージから生のイベント登録データを段階的に取り込む開始パイプライン コードです。
- Python
- SQL
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
ここでは、 modifiedAfter Auto Loader オプションを使用して、クラウド ストレージ パスからのすべてのデータを処理していないことを確認します。増分処理はその境界で中断されます。
Kafka 、 Kinesis 、 Azure Event Hubs などの他のデータソースには、同じ動作を実現するための同等のリーダー オプションがあります。
過去3年間のデータのバックフィル
ここで、以前のデータをバックフィルするために 1 つ以上のフローを追加します。この例では、次のステップを取り上げます。
append onceフローを使用します。これにより、最初のバックフィル後に実行を継続せずに、1 回限りのバックフィルが実行されます。コードはパイプライン内に残り、パイプラインが完全に更新されると、バックフィルが再実行されます。- 各年に 1 つずつ、合計 3 つのバックフィル フローを作成します (この場合、データはパス内で年ごとに分割されます)。Python ではフローの作成をパラメーター化しますが、SQL ではフローごとに 1 回ずつ、コードを 3 回繰り返します。
独自のプロジェクトに取り組んでいて、サーバレス コンピュートを使用していない場合は、パイプラインの最大ワーカーを更新するとよいでしょう。 最大ワーカーを増やすと、予想されるSLA内で現在のストリーミング データの処理を継続しながら、履歴データを処理するためのリソースが確保されます。
強化されたオートスケール (デフォルト) を備えたサーバレス コンピュートを使用すると、負荷が増加するとクラスターのサイズが自動的に増加します。
- Python
- SQL
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
この実装では、いくつかの重要なパターンが強調されています。
関心の分離
- 増分処理はバックフィル操作とは独立しています。
- 各フローには独自の構成と最適化設定があります。
- 増分操作とバックフィル操作には明確な違いがあります。
制御された実行
ONCEオプションを使用すると、各バックフィルが 1 回だけ実行されるようになります。- バックフィル フローはパイプライン グラフ内に残りますが、完了するとアイドル状態になります。完全に更新されると自動的に使用できるようになります。
- パイプライン定義には、バックフィル操作の明確な監査証跡があります。
処理の最適化
- 処理を高速化するため、または処理を制御するために、大きなバックフィルを複数の小さなバックフィルに分割できます。
- 拡張オートスケールを使用すると、現在のクラスター負荷に基づいてクラスター サイズが動的にスケーリングされます。
スキーマの展開
schemaEvolutionMode="addNewColumns"使用すると、スキーマの変更が適切に処理されます。- 履歴データと現在のデータにわたって一貫したスキーマ推論が行われます。
- 新しいデータ内の新しい列は安全に処理されます。