LakeflowパイプラインエディターによるETLパイプラインの開発とデバッグ
パイプライン開発用に構築された IDE である Lakeflow Pipelines Editor で、ETL (抽出、変換、読み込み) パイプラインを開発およびデバッグします。
Lakeflowパイプラインエディターとは何ですか?
Lakeflow パイプラインエディター は、パイプライン開発用に構築された IDE です。 すべてのパイプライン開発タスクを単一のサーフェスに統合し、コードファースト ワークフロー、フォルダーベースのコード編成、選択的実行、データ プレビュー、パイプライン グラフをサポートします。Databricks プラットフォームと統合されているため、バージョン管理、コード レビュー、スケジュール実行も可能になります。
Lakeflow パイプライン エディタ UI の概要
次の画像はLakeflow パイプラインエディターを示しています。
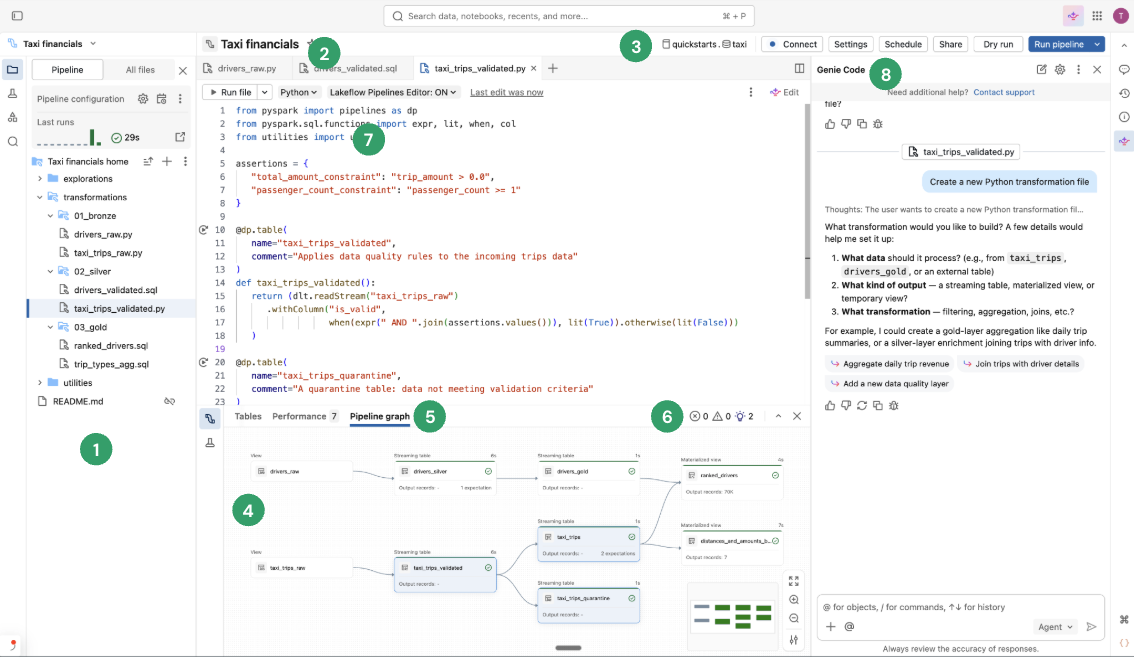
画像には次の機能が表示されます。
- パイプライン アセット ブラウザ: パイプライン アセットを作成、削除、名前変更、整理します。 パイプライン構成へのショートカットも含まれています。
- タブ付きのマルチファイル コード エディター: パイプラインに関連付けられた複数のコード ファイルで作業します。
- パイプライン固有のツールバー: パイプライン構成オプションとパイプラインレベルの実行アクションが含まれています。
- インタラクティブなパイプライングラフ:テーブルの概要を確認したり、データプレビューの下部バーを開いたり、その他のテーブル関連の操作を実行したりできます。
- テーブル レベルの実行に関する情報: パイプライン内のすべてのテーブルまたは単一のテーブルに関する実行に関する情報を取得します。 最新のパイプライン実行の知見を参照してください。
- 問題パネル: この機能は、パイプライン内のすべてのファイルにわたるエラー、警告、および知見を要約し、特定のファイル内のエラーが発生した場所に移動できます。 これは、コードに付加されるエラー表示を補完するものです。
- 選択的実行:コードエディタには、ステップバイステップの開発のための機能が備わっています。たとえば、 [ファイルの実行 ]アクションを使用して現在のファイル内のテーブルのみを更新したり、単一のテーブルを更新したりできます。
 Genie Code : Genie Codeを使用してパイプラインを作成、更新、デバッグします。これは、データ校正およびコード生成からパイプラインの実行とデータ品質の問題の解決に至るまで、複数ステップのワークフローを自動化するエージェント エクスペリエンスです。
Genie Code : Genie Codeを使用してパイプラインを作成、更新、デバッグします。これは、データ校正およびコード生成からパイプラインの実行とデータ品質の問題の解決に至るまで、複数ステップのワークフローを自動化するエージェント エクスペリエンスです。
その他の重要な機能:
- データ プレビュー: ストリーミング テーブルとマテリアライズドビューのデータを検査します。
- デフォルトのパイプライン フォルダー構造: 新しいパイプラインには、パイプラインの開始点として使用できる事前定義されたフォルダー構造とサンプル コードが含まれています。
新しいETLパイプラインを作成する
Lakeflowパイプラインエディタを使用して新しいETL パイプラインを作成するには、次の手順を実行します。
-
サイドバーの上部にある
 新規 を選択し、
新規 を選択し、 ETL パイプライン 。
ETL パイプライン 。パイプラインは、以下のデフォルト設定で自動的に作成されます。
これらの設定はパイプライン ツールバーから調整できます。
-
一番上に、パイプラインに固有の名前を付けてください。
-
名前の横には、デフォルトで選択されているカタログとスキーマが表示されます。
デフォルトのカタログとデフォルトのスキーマは、コード内でカタログまたはスキーマを使用してデータセットを修飾していない場合に、データセットの読み取りまたは書き込みが行われる場所です。詳細については、 Databricksのデータベース オブジェクトを参照してください。
カタログとスキーマをクリックして、パイプラインのデフォルト設定を変更してください。
-
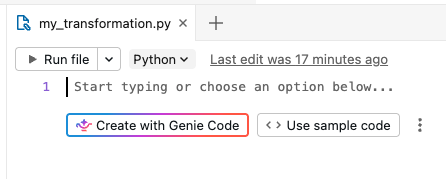
デフォルトでは、パイプラインには空の
my_transformationファイルが含まれています。言語ドロップダウンリストから選択することで、このファイルをPythonとSQLの間で切り替えることができます。このファイルに直接コードを記述するか、以下のいずれかのオプションを選択してすぐに開始してください。- Genie Codeで作成 :自然言語を使ってパイプラインを記述するだけで、Genie Codeがそれを構築します。
- サンプルコードを使用する :現在のファイルと同じ言語で、デフォルトのフォルダ構造とサンプルコードを作成します。
より高度なオプションについては、
 メニュー(右側)
メニュー(右側) サンプルコードボタンを使用して 、次の操作を行います。
サンプルコードボタンを使用して 、次の操作を行います。- 既存のソースコードを追加する :Gitフォルダを含む、ワークスペースに既に存在するコードファイルとパイプラインを関連付けます。
- ソース管理として設定 : ソース管理とCI/CDサポートには、Declarative Automation Bundlesプロジェクトを使用します。ソース管理されたパイプラインを作成するを参照してください。
- Hive metastoreを使用する : 従来の設定でパイプラインを作成します。
あるいは、ワークスペース ブラウザから ETL パイプラインを作成することもできます。
- 左側のパネルで ワークスペース をクリックします。
- Git フォルダーを含む任意のフォルダーを選択します。
- 右上隅の [作成] をクリックし、 [ETL パイプライン] をクリックします。
[ジョブとパイプライン] ページからETLパイプラインを作成することもできます。
- ワークスペースで、サイドバーの
 ジョブ & パイプライン をクリックします。
ジョブ & パイプライン をクリックします。 - [新規] の下で、 [ETL パイプライン] をクリックします。
Databricks CLIは、ターミナルからパイプラインを作成、変更、管理するためのコマンドを提供します。pipelinesコマンド・グループを参照してください。
既存のETLパイプラインを開く
Lakeflow Pipelinesエディターで既存のETLパイプラインを開く方法は複数あります。
-
パイプラインに関連付けられているソース ファイルを開きます。
- サイドパネルの ワークスペース をクリックします。
- パイプラインのソース コード ファイルがあるフォルダーに移動します。
- ソース コード ファイルをクリックすると、エディターでパイプラインが開きます。
-
最近編集したパイプラインを開きます。
- エディターから、アセット ブラウザーの上部にあるパイプラインの名前をクリックし、表示される最近のリストから別のパイプラインを選択することで、最近編集した他のパイプラインに移動できます。
- エディターの外部の左側のサイドバーの 最近 ページから、パイプラインまたはパイプラインのソース コードとして構成されたファイルを開きます。
-
製品全体のパイプラインを表示するときに、パイプラインを編集することを選択できます。
- パイプラインモニタリングページで、 をクリックします。
 パイプラインを編集 をクリックします。
パイプラインを編集 をクリックします。 - 左側のサイドバーの 「ジョブとパイプライン」 ページで、パイプラインを編集します。
- ジョブを編集してパイプライン タスクを追加する場合、
 パイプライン の下でパイプラインを選択するときに、 ボタンをクリックします。
パイプライン の下でパイプラインを選択するときに、 ボタンをクリックします。
- パイプラインモニタリングページで、 をクリックします。
-
アセット ブラウザーで すべてのファイル を参照しているときに、別のパイプラインからソース コード ファイルを開くと、エディターの上部にバナーが表示され、関連付けられているパイプラインを開くように求められます。
パイプライン資産ブラウザ
パイプラインを編集しているときは、左側のワークスペースサイドバーで パイプラインアセットブラウザ と呼ばれる特別なモードが使用されます。デフォルトでは、パイプラインアセットブラウザーはパイプラインのルート、およびそのルート内のフォルダーとファイルに焦点を当てます。また、 「すべてのファイル を表示」を選択すると、パイプラインのルート以外のファイルも表示できます。パイプラインエディタで特定のパイプラインを編集中に開いたタブは記憶され、別のパイプラインに切り替えると、前回そのパイプラインを編集したときに開いていたタブが復元されます。
エディターには、SQL ファイルを編集するためのコンテキスト ( Databricks SQL エディター と呼ばれる) と、SQL ファイルやパイプライン ファイルではないワークスペース ファイルを編集するための一般的なコンテキストもあります。これらの各コンテキストは、そのコンテキストを最後に使用したときに開いていたタブを記憶し、復元します。左サイドバーの上部からコンテキストを切り替えることができます。ヘッダーをクリックして、ワークスペース、SQL エディター、または最近編集したパイプラインのいずれかを選択します。
ワークスペース ブラウザ ページからファイルを開くと、そのファイルに対応するエディターでファイルが開きます。ファイルがパイプラインに関連付けられている場合、それはLakeflow Pipelines Editor です。
パイプラインの一部ではないがパイプラインのコンテキストを保持するファイルを開くには、アセット ブラウザの [すべてのファイル] タブからファイルを開きます。
パイプライン アセット ブラウザには 2 つのタブがあります。
- パイプライン : ここには、パイプラインに関連付けられたすべてのファイルがあります。 フォルダーを作成、削除、名前変更、整理することができます。このタブには、パイプライン構成のショートカットと最近の実行のグラフィカル ビューも含まれています。
- すべてのファイル :その他のワークスペースアセットはすべてこちらから入手できます。これは、パイプラインに追加するファイルを見つけたり、宣言型自動化バンドルを定義するYAMLファイルなど、パイプラインに関連する他のファイルを表示したりするのに役立ちます。
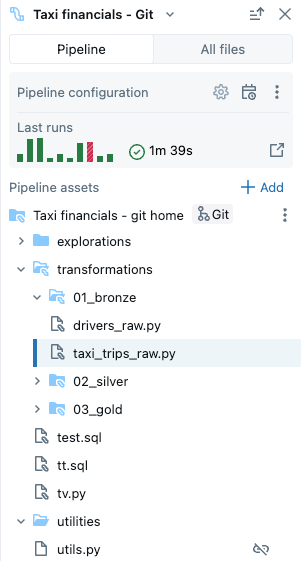
パイプラインには次の種類のファイルを含めることができます。
- ソース コード ファイル: これらのファイルはパイプラインのソース コード定義の一部であり、 [設定] で確認できます。 Databricks では、ソース コード ファイルを常にパイプラインのルート フォルダー内に保存することを推奨しています。そうしないと、ブラウザーの下部にある外部ファイルセクションに表示され、機能セットがあまり充実しなくなります。
- 非ソース コード ファイル: これらのファイルはパイプラインのルート フォルダー内に保存されますが、パイプラインのソース コード定義の一部ではありません。
パイプラインのファイルとフォルダーを管理するには、「パイプライン」 タブの下にあるパイプライン アセット ブラウザーを使用する必要があります。 これにより、パイプラインの設定が正しく更新されます。ワークスペースブラウザーまたは「 すべてのファイル」 タブからファイルやフォルダーを移動または名前変更すると、パイプライン構成が壊れるため、 設定 で手動で解決する必要があります。
ルートフォルダ
パイプラインアセットブラウザは、パイプラインのルートフォルダに配置されます。新しいパイプラインを作成すると、ユーザーのホーム計画にパイプライン ルート フォルダーが作成されます。
パイプラインアセットブラウザでルートフォルダを変更できます。これは、あるフォルダ内にパイプラインを作成し、後でそれを別のフォルダに移動したい場合に便利です。例えば、通常のフォルダにパイプラインを作成し、バージョン管理のためにソースコードをGitフォルダに移動したい場合などです。
- クリックルート フォルダーのオーバーフロー メニュー。
- 新しいルート フォルダーの構成を クリックします。
- パイプライン ルート フォルダ で
 をクリックし、別のフォルダをパイプライン ルート フォルダとして選択します。
をクリックし、別のフォルダをパイプライン ルート フォルダとして選択します。 - 保存 をクリックします。
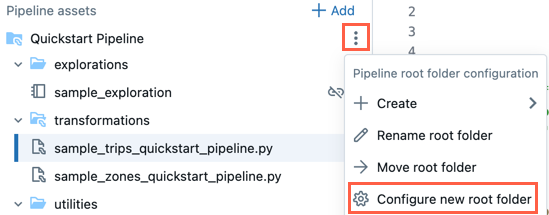
の中で![]() ルート フォルダーの場合は、 [ルート フォルダーの名前を変更] をクリックしてフォルダー名を変更することもできます。ここで、 「ルート フォルダーの移動」 をクリックして、ルート フォルダーを Git フォルダーなどに移動することもできます。
ルート フォルダーの場合は、 [ルート フォルダーの名前を変更] をクリックしてフォルダー名を変更することもできます。ここで、 「ルート フォルダーの移動」 をクリックして、ルート フォルダーを Git フォルダーなどに移動することもできます。
設定でパイプラインのルート フォルダーを変更することもできます。
- 設定 をクリックします。
- コードアセット で、 パスの構成 をクリックします。
- [ ] をクリックして、 パイプライン ルート フォルダー の下のフォルダーを変更します。
- 保存 をクリックします。
パイプラインのルートフォルダを変更すると、パイプラインアセットブラウザに表示されるファイルリストに影響が出ます。これは、以前のルートフォルダ内のファイルが外部ファイルとして表示されるためです。
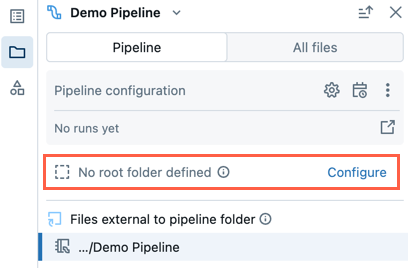
ルートフォルダのない既存のパイプライン
従来のノートブック編集機能を使用して作成された既存のパイプラインには、ルートフォルダが設定されません。ルート フォルダーが構成されていないパイプラインを開いたときに、パイプラインのルート フォルダーを構成したい場合は、次のステップに従います。
- パイプラインアセットブラウザーで、 [設定] をクリックします。
- [ ] をクリックして、 パイプライン ルート フォルダー の下のルート フォルダーを選択します。
- 保存 をクリックします。
デフォルトのフォルダ構造
新しいパイプラインを作成すると、デフォルトのフォルダー構造が作成されます。これは、以下で説明するように、パイプラインのソース コード ファイルと非ソース コード ファイルを整理するための推奨構造です。
このフォルダー構造には、少数のサンプル コード ファイルが作成されます。
フォルダ名 | これらの種類のファイルの推奨場所 |
|---|---|
| パイプラインのすべてのフォルダーとファイルが含まれるルート フォルダー。 |
| テーブル定義を含む Python または SQL コード ファイルなどのソース コード ファイル。 |
| 探索的データ分析に使用されるノートブック、クエリ、コード ファイルなどの非ソース コード ファイル。 |
| 他のコード ファイルからインポートできる Python モジュールを含む非ソース コード ファイル。サンプル コードの言語として SQL を選択した場合、このフォルダーは作成されません。 |
ワークフローに合わせてフォルダー名を変更したり、構造を変更したりできます。新しいソース コード フォルダーを追加するには、次のステップに従います。
- パイプラインアセットブラウザで 「追加」 をクリックします。
- パイプライン ソース コード フォルダの作成 をクリックします。
- フォルダ名を入力し、 作成 をクリックします。
ソースコードファイル
ソース コード ファイルは、パイプラインのソース コード定義の一部です。 パイプラインを実行すると、これらのファイルが評価されます。ソース コード定義の一部であるファイルとフォルダーには、ミニ パイプライン アイコンが重ねて表示された特別なアイコンが表示されます。
新しいソースコードファイルを追加するには:
- クリックルートフォルダの隣。
- 変換 をクリックします。
- ファイルの 名前 を入力し、 言語 として Python または SQL を選択します。
- 作成 をクリックします。
インラインヘルパーを使用して、コードの記述を開始します。![]() Genie Code作成するか、目的のデータセット タイプ (マテリアライズドビューやストリーミング テーブルなど) の短いコード スニペットを生成します。
Genie Code作成するか、目的のデータセット タイプ (マテリアライズドビューやストリーミング テーブルなど) の短いコード スニペットを生成します。
新しいパイプラインを作成すると、ソース コード用のtransformationsフォルダーがデフォルトで作成されます。このフォルダーは、パイプライン テーブル定義を含む Python または SQL コード ファイルなどのパイプライン ソース コードの推奨される場所です。
ソースコード以外のファイル
ソース コード ファイル以外のファイルは、パイプラインのルート フォルダー内に格納されますが、パイプラインのソース コード定義の一部ではありません。これらのファイルは、パイプラインの実行時には評価されません。ソース コード ファイル以外のファイルを 外部ファイルにすることはできません。
ソース コードと一緒に保存したいパイプラインでの作業に関連するファイルにこれを使用できます。例えば:
- パイプラインのライフサイクル外でコンピュート上にて実行される、アドホックな探索に使用するノートブック。
- ソース コード ファイル内にこれらのモジュールを明示的にインポートしない限り、ソース コードでは評価されない Python モジュール。
新しい非ソースコードファイルを追加するには:
- クリックルートフォルダの隣。
- 探索 または ユーティリティ をクリックします。
- ファイルの 名前 を入力します。
- 作成 をクリックします。
新しいパイプラインを作成すると、ソース コード以外のファイル用の次のフォルダーがデフォルトで作成されます。
フォルダ名 | 説明 |
|---|---|
| このフォルダーは、ノートブック、クエリー、ダッシュボード、およびその他のファイルの推奨される場所であり、パイプラインの実行ライフサイクルの外部で通常行うように、コンピュートでそれらを実行します。 |
| このフォルダーは、親フォルダーが階層的にルート フォルダーの下にある限り、 |
ルート フォルダーの外部にある Python モジュールをインポートすることもできますが、その場合は Python コードのsys.pathにフォルダー パスを追加する必要があります。
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
外部ファイル
パイプライン ブラウザーの 外部ファイル セクションには、ルート フォルダーの外部にあるソース コード ファイルが表示されます。
外部ファイルをtransformationsフォルダーなどのルート フォルダーに移動するには、次の手順に従います。
- クリックアセット ブラウザでファイルを選択し、 [移動] をクリックします。
- ファイルの移動先のフォルダを選択し、 移動 をクリックします。
複数のパイプラインに関連付けられたファイル
ファイルが複数のパイプラインに関連付けられている場合は、ファイルのヘッダーにバッジが表示されます。関連付けられているパイプラインの数があり、他のパイプラインに切り替えることができます。
すべてのファイルセクション
パイプライン セクションに加えて、ワークスペース内の任意のファイルを開くことができる すべてのファイル セクションがあります。ここでは次のことができます:
- ルートフォルダの外部にあるファイルをタブ内で開き、 Lakeflow パイプライン エディタを離れることなく開きます。
- 別のパイプラインのソース コード ファイルに移動して開きます。これにより、エディターでファイルが開き、エディターでフォーカスをこの 2 番目のパイプラインに切り替えるオプションを含むバナーが表示されます。
- ファイルをパイプラインのルート フォルダーに移動します。
- パイプラインのソース コード定義にルート フォルダー外のファイルを含めます。
パイプラインのソースファイルを編集する
ワークスペース ブラウザーまたはパイプライン アセット ブラウザーからパイプライン ソース ファイルを開くと、そのファイルはLakeFlow Pipelinesエディターのエディター タブで開きます。 複数のファイルを開くと、それぞれ別のタブが開くため、複数のファイルを同時に編集できます。
ワークスペース ブラウザからパイプラインに関連付けられていないファイルを開くと、別のコンテキストでエディター (一般的な ワークスペース エディター、またはSQLファイルの場合は SQLエディター ) が開きます。
パイプライン アセット ブラウザーの [すべてのファイル] タブからパイプライン以外のファイルを開くと、パイプライン コンテキストの新しいタブで開きます。
パイプラインのソースコードは複数のファイルで構成されています。デフォルトでは、ソースファイルはパイプラインアセットブラウザの transformations フォルダ内にあります。ソースコードファイルは、Pythonファイル( *.py )またはSQLファイル( *.sql )のいずれかです。ソースには、単一のパイプライン内にPythonファイルとSQLファイルを混在させることができ、あるファイル内のコードが別のファイルで定義されたテーブルまたはビューを参照することも可能です。
変換 フォルダーにマークダウン ( *.md )ファイルを含めることもできます。Markdown ファイルはドキュメントやメモに使用できますが、パイプラインの更新を実行するときには無視されます。
以下の機能はLakeflow パイプラインエディターに固有のものです。
-
Connect : サーバレスまたはクラシックコンピュートに接続してパイプラインを実行します。 パイプラインに関連付けられたすべてのファイルは同じコンピュート接続を使用するため、一度接続すると、同じパイプライン内の他のファイルに接続する必要はありません。 コンピュート オプションの詳細については、 「コンピュート構成オプション」を参照してください。
探索的ノートブックなどのパイプライン以外のファイルの場合、接続オプションは使用できますが、その個々のファイルにのみ適用されます。
-
ファイルの実行 :このソースファイルで定義されているテーブルを更新するコードを実行します。次のセクションでは、パイプラインコードを実行するさまざまな方法について説明します。
-
編集 :
Genie Code使用して、ファイル内のコードを編集または追加します。 -
応急処置 :
Genie Code 、コード内のエラーを修正したり、コードに対して何らかの処理を実行したりします。
下部のパネルも現在のタブに基づいて調整されます。下部パネルでパイプライン情報をいつでも表示できます。SQL エディター ファイルなどのパイプラインに関連しないファイルも、別のタブの下部パネルに出力が表示されます。次の画像は、下部のパネルでパイプライン情報の表示と選択したノートブックの情報の表示を切り替える垂直タブ セレクターを示しています。
パイプラインコードを実行する
パイプライン コードを実行するには、次の 4 つのオプションがあります。
-
パイプライン内のすべてのソースコードファイルを実行する
[パイプライン] または [完全なテーブル更新でパイプラインを実行] をクリックして、パイプライン ソース コードとして定義されているすべてのファイル内のすべてのテーブル定義を実行します。 更新タイプの詳細については、 「パイプライン更新セマンティクス」を参照してください。

ドライラン をクリックして、データを更新せずにパイプラインを検証することもできます。
-
コードを1つのファイルで実行する
[ファイル実行] または [完全なテーブル更新でファイルを実行] をクリックして、現在のファイル内のすべてのテーブル定義を実行します。 パイプライン内の他のファイルは評価されません。

このオプションは、ファイルをすばやく編集して反復処理する場合のデバッグに役立ちます。単一のファイル内のコードのみを実行すると副作用が生じます。
- 他のファイルが評価されない場合、それらのファイル内のエラーは見つかりません。
- 他のファイルでマテリアライズされたテーブルでは、より新しいソース データが存在する場合でも、テーブルの最新のマテリアライズが使用されます。
- 参照先のテーブルがまだマテリアライズされていない場合は、エラーが発生する可能性があります。
- パイプライングラフは、まだ具体化されていない他のファイル内のテーブルについては、不正確であったり、不完全であったりする可能性があります。Databricksはグラフの正確性を維持するために最大限の努力を払いますが、そのために他のファイルを評価することはありません。
デバッグとファイルの編集が完了したら、パイプラインを本番運用する前に、パイプライン内のすべてのソース コード ファイルを実行して、パイプラインがエンドツーエンドで動作することを確認することをDatabricksではお勧めします。
-
単一のテーブルに対してコードを実行する
ソース コード ファイル内のテーブル定義の横にある 実行テーブル アイコン をクリックします。
 次に、ドロップダウンから テーブルの更新 または テーブルの完全更新の のいずれかを選択します。 単一のテーブルに対してコードを実行すると、単一のファイルでコードを実行した場合と同様の副作用が発生します。
次に、ドロップダウンから テーブルの更新 または テーブルの完全更新の のいずれかを選択します。 単一のテーブルに対してコードを実行すると、単一のファイルでコードを実行した場合と同様の副作用が発生します。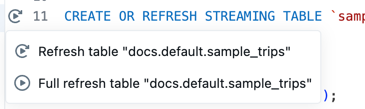
ストリーミングテーブルとマテリアライズドビューでは、単一テーブルのコードを実行できます。 シンクとビューはサポートされていません。
-
テーブルセットのコードを実行する
パイプライングラフからテーブルを選択することで、実行するテーブルのリストを作成できます。パイプライングラフのテーブルにカーソルを合わせ、
、そして 「更新するテーブルを選択」 を選択します。更新するテーブルを選択したら、パイプライングラフの下部にある「 実行」 または 「完全更新で実行」 オプションを選択してください。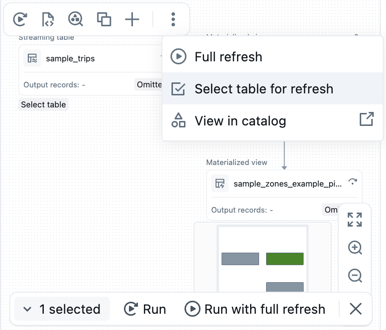
-
選択したコードを実行する
SQLコードを選択し、 「選択したコードを実行」 をクリックすると、データを実際に作成することなく、出力結果をすばやく確認できます。出力結果は、下部パネルの 「クエリ結果」 タブに表示されます。
パイプライングラフ
パイプライン内のすべてのソースコードファイルを実行または検証すると、 パイプライングラフ (有向非巡回グラフ(DAG)とも呼ばれる)が表示されます。このグラフは、テーブルの依存関係グラフを示しています。各ノードは、パイプラインのライフサイクルに沿って、検証済み、実行中、エラーなど、さまざまな状態を持つ。
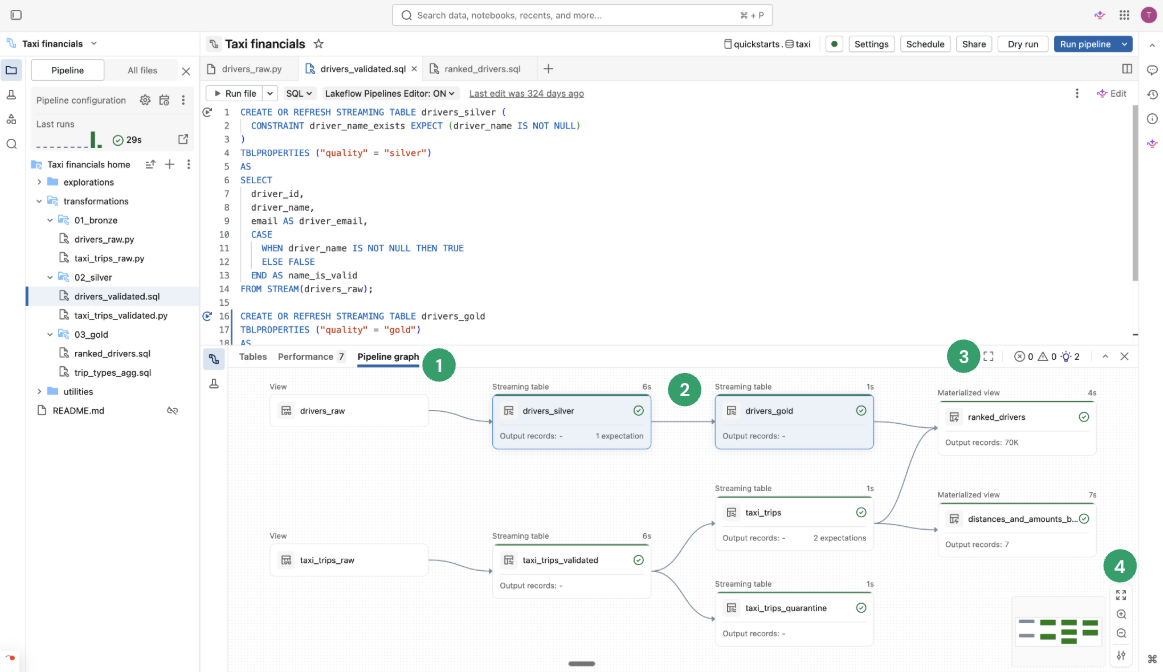
- パイプライングラフ :下部パネルの「 パイプライングラフ」 タブをクリックしてグラフを開きます。
- ノード : パイプラインの一部であるテーブルの依存関係と、それらに関連するメトリクスを表示します。 現在開いているファイルに含まれるノードは、パイプライングラフ上で強調表示されます。ノードにカーソルを合わせると、クエリの更新などのオプションを含むツールバーが表示されます。ノードを右クリックすると、コンテキストメニューに同じオプションが表示されます。ノードをクリックすると、データのプレビューとテーブル定義が表示されます。ファイルを編集すると、そのファイル内で定義されているテーブルがグラフ上で強調表示されます。
- タブで開く :グラフを最大化するには、下部パネルの右上にあるアイコンを選択して、別のタブで開きます。
- その他のオプション :右下には、ズームオプションや、グラフを縦または横のレイアウトで表示する その他のオプション など、追加のオプションがあります。
データプレビュー
データ プレビュー セクションには、選択したテーブルのサンプル データが表示されます。
パイプライングラフ内のノードをクリックすると、テーブルのデータのプレビューが表示されます。下部のパネルで別のテーブルのデータプレビューに直接移動するには、 「グラフに戻る」 を選択するか、パイプライングラフが別のタブで開いている場合は別のノードをクリックします。
または、 [テーブル] セクションに移動して、 [データプレビューを表示] をクリックします。![]() 。テーブルを選択した場合は、 「すべてのテーブル」 をクリックしてすべてのテーブルに戻ります。
。テーブルを選択した場合は、 「すべてのテーブル」 をクリックしてすべてのテーブルに戻ります。
テーブル データをプレビューすると、その場でデータをフィルター処理したり並べ替えたりすることができます。より複雑な分析を行う場合は、 Explorations フォルダー内のノートブックを使用または作成できます (デフォルトのフォルダー構造を維持していると仮定)。デフォルトでは、このフォルダー内のソース コードはパイプラインの更新中に実行されないため、パイプラインの出力に影響を与えずにクエリを作成できます。
処理に対する洞察
エディターの下部にあるパネルで、最新のパイプライン更新に関するテーブル実行の知識を確認できます。
パネル | 説明 |
|---|---|
テーブル | すべてのテーブルをステータスとメトリクスと共に一覧表示します。1つのテーブルを選択すると、そのテーブルのメトリクスとパフォーマンス、およびデータプレビュー用のタブが表示されます。マテリアライズドビューの場合、 インクリメンタル化 列は、テーブルがどのように更新されたかを示し、インクリメンタル化に関する知見を提供します。インクリメンタル化に関する知見をご覧ください。 |
パフォーマンス | このパイプライン内のすべてのフローの履歴とプロファイルをクエリします。実行中および実行後に、実行メトリクスと詳細なクエリ プランにアクセスできます。 詳細については、 「パイプラインのクエリ履歴へのアクセス」を参照してください。 |
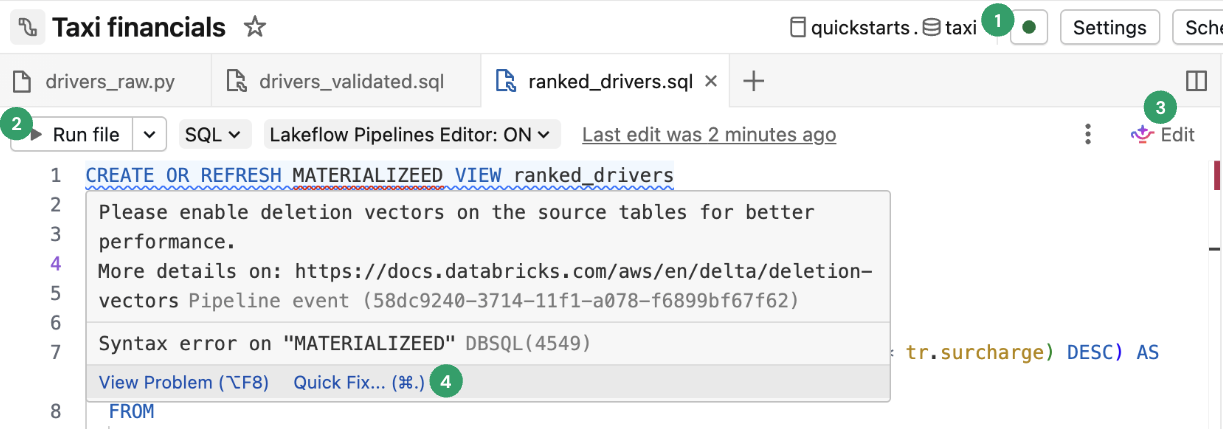
問題パネル | パネルをクリックすると、パイプラインのエラー、警告、および知見が簡略化されて表示されます。 項目をクリックすると詳細が表示されますので、エラーが発生したコード内の箇所に移動してください。エラーが現在表示されているファイル以外のファイルにある場合、エラーが発生しているファイルにリダイレクトされます。 「詳細を表示」をクリックすると、対応するイベント ログ エントリの詳細 が表示されます。完全なイベント ログを表示するには、 [ログの表示] をクリックします。 「エラーの診断」 をクリックして問題をデバッグします。 コードの特定の部分に関連するエラーについては、コードに添付されたエラー インジケーターが表示されます。詳細を表示するには、 エラー アイコンをクリックするか、赤い線の上にマウスを置きます。詳細情報を示すポップアップが表示されます。次に、 「クイック修正」 をクリックすると、エラーをトラブルシューティングするための一連のアクションが表示されます。 |
イベントログ | 最後のパイプライン実行中にトリガーされたすべてのイベント。問題トレイ内の ログまたは任意のエントリの表示 をクリックします。 |
パイプライン構成
パイプライン エディターからパイプラインを構成できます。パイプラインの設定、スケジュール、または権限を変更できます。
これらはそれぞれ、エディターのヘッダーにあるボタン、またはアセット ブラウザー (左側のサイドバー) のアイコンからアクセスできます。
-
設定 (または選択
 アセットブラウザ内):
アセットブラウザ内):設定パネルからパイプラインの設定を編集できます。これには、一般情報、ルート フォルダーとソース コードの構成、コンピュートの構成、通知、詳細設定などが含まれます。
-
スケジュール (または選択)
 アセットブラウザ内):
アセットブラウザ内):スケジュール ダイアログから、パイプラインのスケジュールを 1 つ以上作成できます。たとえば、毎日実行したい場合は、ここで設定できます。選択したスケジュールでパイプラインを実行するジョブを作成します。スケジュール ダイアログから新しいスケジュールを追加したり、既存のスケジュールを削除したりできます。
-
シェア (または、
アセットブラウザのメニューから ):
):パイプライン権限ダイアログから、ユーザーとグループのパイプラインの権限を管理できます。
イベントログ
パイプラインのイベント ログを Unity Catalog に公開できます。デフォルトでは、パイプラインのイベント ログは UI に表示され、所有者がクエリのためにアクセスできます。
- 設定 を開きます。
- クリック
 詳細設定の 横にある矢印。
詳細設定の 横にある矢印。 - 詳細設定の編集を クリックします。
- [イベント ログ] の下で、 [カタログに公開] をクリックします。
- イベント ログの名前、カタログ、スキーマを指定します。
- 保存 をクリックします。
パイプライン イベントは、指定したテーブルに公開されます。
パイプライン イベント ログの使用の詳細については、 「イベント ログのクエリ」を参照してください。
パイプライン環境
設定 で依存関係を追加することで、ソースコード用の環境を作成できます。
- 設定 を開きます。
- パイプライン環境 の下にある 「環境の編集」を クリックします。
- 「依存関係を追加」 をクリックすると、
requirements.txtファイルに依存関係を追加するのと同じように、依存関係を追加できます。依存関係の詳細については、 「ノートブックに依存関係を追加する」を参照してください。
Databricks では、 ==を使用してバージョンをピン留めすることをお勧めします。PyPI パッケージを参照してください。
環境はパイプライン内のすべてのソース コード ファイルに適用されます。
通知
パイプライン設定 を使用して通知を追加できます。
- 設定 を開きます。
- [通知] セクションで、 [通知を追加] をクリックします。
- 1 つ以上の電子メール アドレスと、そのアドレスを送信するイベントを追加します。
- [通知を追加]を クリックします。
Pythonイベント フックを使用して、通知やカスタム処理などのイベントに対するカスタム応答を作成します。
モニタリングパイプライン
Databricks は、実行中のパイプラインを監視する機能も提供します。エディターには、最新の実行に関する結果と実行に関する知識が表示されます。 パイプラインをインタラクティブに開発しながら効率的に反復できるように最適化されています。
パイプライン モニタリング ページでは、実行履歴を表示できます。これは、ジョブを使用してパイプラインがスケジュールに従って実行されている場合に役立ちます。
残りのモニタリング エクスペリエンスと、更新されたプレビュー モニタリング エクスペリエンスがあります。 次のセクションでは、プレビューモニタリングエクスペリエンスを有効または無効にする方法について説明します。 両方のエクスペリエンスに関する情報については、 「UI のパイプラインの監視」を参照してください。
モニタリング体験は、ワークスペースの左側にある ジョブとパイプライン ボタンから利用できます。 パイプラインアセットブラウザの実行結果をクリックすることで、エディタから直接モニタリングページに移動することもできます。
モニタリング ページの詳細については、 「UI のパイプラインの監視」を参照してください。 モニタリング UI には、UI のヘッダーから [パイプラインの編集] を 選択することで、 Lakeflow Pipelinesエディターに戻る機能が含まれています。
パイプライン開発にGenie Codeを使用する
パブリックプレビュー
この機能は パブリック プレビュー段階です。
LakeFlow Pipelines Editor はGenie Codeと統合されており、自然言語から直接、パイプライン全体を生成、変更、デバッグできます。詳細については、 「パイプライン開発にGenie Codeを使用する」を参照してください。
制限事項と既知の問題
ETLパイプラインエディターの次の制限事項と既知の問題を参照してください。
-
explorationsフォルダー内のファイルまたはノートブックを開いて開始した場合、ワークスペース ブラウザのサイドバーはパイプラインにフォーカスしません。これらのファイルまたはノートブックはパイプライン ソース コード定義の一部ではないためです。ワークスペース ブラウザでパイプライン フォーカス モードに入るには、パイプラインに関連付けられているファイルを開きます。
-
通常のビューではデータプレビューはサポートされていません。
-
Python モジュールは、ルート フォルダー内または
sys.path上にある場合でも、UDF 内からは見つかりません。これらのモジュールにアクセスするには、UDF 内からsys.pathにパスを追加します。次に例を示します。sys.path.append(os.path.abspath(“/Workspace/Users/path/to/modules”)) -
%pip installファイル (新しいエディターのデフォルトのアセット タイプ) からはサポートされません。設定で依存関係を追加できます。パイプライン環境を参照してください。あるいは、パイプラインに関連付けられたノートブックの
%pip installソース コード定義で引き続き使用することもできます。
よくある質問
-
ソースコードにノートブックではなくファイルを使用するのはなぜですか?
ノートブックのセルベースの実行はパイプラインと互換性がありません。パイプラインを使用する場合、ノートブックの標準機能が無効になるか変更されるため、ノートブックの動作に慣れているユーザーは混乱します。
Lakeflow Pipelines Editor では、ファイル エディターはパイプライン用の最上級のエディターの基盤として使用されます。 実行テーブル のような機能はパイプラインに明示的にターゲットを絞っています
使い慣れた機能を異なる動作でオーバーロードするのではなく、 -
ノートブックをソースコードとして使用できますか?
はい、できます。ただし、 実行テーブル などの一部の機能は
または 実行ファイル が存在しません。ノートブックを使用した既存のパイプラインがある場合、新しいエディターでも引き続き機能します。ただし、Databricks では、新しいパイプラインではファイルに切り替えることを推奨しています。
-
新しく作成したパイプラインに既存のコードを追加するにはどうすればよいですか?
既存のソース コード ファイルを新しいパイプラインに追加できます。既存のファイルを含むフォルダーを追加するには、次のステップに従います。
- 設定 をクリックします。
- [ソース コード] の下で [パスの構成] をクリックします。
- 「パスの追加」 をクリックし、既存のファイルのフォルダーを選択します。
- 保存 をクリックします。
個々のファイルを追加することもできます。
- パイプラインアセットブラウザで 「すべてのファイル」 をクリックします。
- ファイルに移動してクリックをクリックし、 パイプラインに含めるを クリックします。
これらのファイルをパイプラインのルート フォルダーに移動することを検討してください。パイプラインのルート フォルダーの外側に残されている場合は、 外部ファイル セクションに表示されます。
-
パイプラインのソース コードをGitで管理できますか?
パイプラインを最初に作成するときに Git フォルダーを選択することで、Git でパイプライン ソースを管理できます。
ソースコードをGitフォルダで管理することで、ソースコードのバージョン管理が可能になります。ただし、構成をバージョン管理するために、Databricksは宣言型自動化バンドルを使用してパイプライン構成をバンドル構成ファイルで定義し、それをGit(または他のバージョン管理システム)に保存することを推奨しています。詳細については、 「宣言的オートメーション バンドルとは何ですか?」を参照してください。 。
最初に Git フォルダーにパイプラインを作成しなかった場合は、ソースを Git フォルダーに移動できます。Databricks では、エディター アクションを使用してルート フォルダー全体を Git フォルダーに移動することをお勧めします。これにより、すべての設定がそれに応じて更新されます。ルートフォルダーを参照してください。
パイプライン アセット ブラウザでルート フォルダを Git フォルダに移動するには:
- クリックルート フォルダー用。
- ルートフォルダの移動を クリックします。
- ルート フォルダーの新しい場所を選択し、 [移動] をクリックします。
詳細については、 「ルート フォルダー」セクションを参照してください。
移動後、ルート フォルダーの名前の横に、使い慣れた Git アイコンが表示されます。
パイプライン ルート フォルダーを移動するには、パイプライン アセット ブラウザーと上記のステップを使用します。 他の方法で移動するとパイプライン構成が壊れるため、 設定 で正しいフォルダパスを手動で構成する必要があります。
-
同じルート フォルダーに複数のパイプラインを配置できますか?
可能ですが、Databricks ではルート フォルダーごとに 1 つのパイプラインのみを使用することをお勧めします。
-
ドライ実行はいつ実行すればよいですか?
ドライラン をクリックして、テーブルを更新せずにコードを確認します。
-
コード内で一時ビューをいつ使用する必要がありますか?また、マテリアライズドビューを使用する必要があるのはどのような場合ですか?
データをマテリアライズしたくない場合は、一時ビューを使用します。たとえば、これは、カタログに登録されているストリーミング テーブルやマテリアライズドビューを使用してデータを実体化する準備ができる前に、データを準備するための一連のステップの中のステップです。