ストリーミングテーブル
ストリーミング テーブルは、ストリーミングまたは増分データ処理の追加サポートを備えたDeltaテーブルです。 ストリーミングテーブルは、パイプライン内の1つまたは複数のフローのターゲットとなることができます。
ストリーミング テーブルは、次の理由からデータ取り込みに適しています。
- 各入力行は 1 回だけ処理され、これにより、ほとんどの取り込みワークロード (つまり、テーブルに行を追加またはアップサートする) がモデル化されます。
- 大量の追加専用データを処理できます。
ストリーミングテーブルは、行と時間ウィンドウに基づいて推論でき、大量のデータを処理でき、低遅延処理を提供できるため、低遅延のストリーミング変換にも適しています。
次の図は、フローがストリーミングソースからデータを読み取り、パイプライン内のストリーミングテーブルに増分的に書き込む様子を示しています。
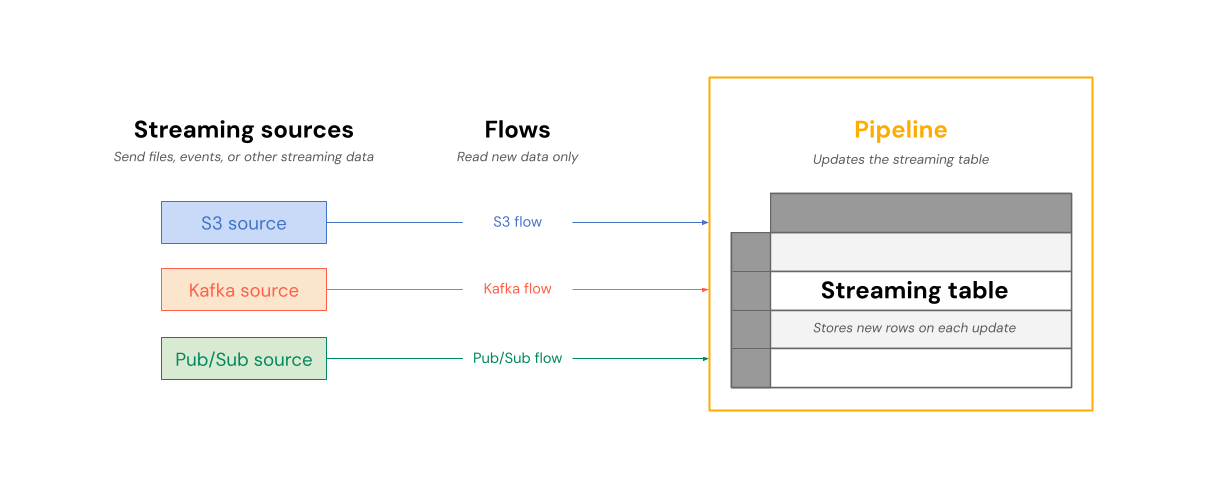
更新のたびに、ストリーミングテーブルに関連付けられたフローは、ストリーミングソース内の変更された情報を読み取り、新しい情報をそのテーブルに追加します。
ストリーミングテーブルは、単一のパイプラインによって所有および更新されます。パイプラインのソースコード内で、ストリーミングテーブルを明示的に定義します。パイプラインによって定義されたテーブルは、他のパイプラインによって変更または更新することはできません。複数のフローを定義して、単一のストリーミングテーブルに追加することができます。
Databricksは、ストリーミングテーブル処理をサポートするために内部テーブルを作成します。これらのテーブルはsystem.information_schema.tablesに表示されますが、カタログ エクスプローラーや他のワークスペース UI ページには表示されません。
Databricks SQLを使用してパイプラインの外でストリーミングテーブルを作成すると、Databricksはテーブルを更新するために使用されるパイプラインを作成します。ワークスペースの左側のナビゲーションから [ジョブとパイプライン] を選択すると、パイプラインを表示できます。 ビューに パイプラインタイプの 列を追加できます。パイプラインで定義されたストリーミングテーブルの型はETLです。Databricks SQLで作成されたストリーミングテーブルのタイプはMV/STです。
フローの詳細については、 「 Lakeflow Spark宣言型パイプライン フローを使用してデータを段階的にロードして処理する」を参照してください。
取り込み用のストリーミングテーブル
ストリーミングテーブルは、追記専用のデータソース向けに設計されており、入力データを一度だけ処理します。このため、データが継続的に到着し、既存のレコードを再処理することなく確実に取得する必要がある取り込みワークロードに最適です。Databricksは、クラウドストレージおよびストリーミングメッセージバスからのデータ取り込みをサポートしています。
クラウドストレージからファイルを取り込む
ストリーミングテーブルを使用すると、クラウドストレージから新しいファイルを取り込むことができます。これらの例では、Auto Loader を使用して、新しいファイルが到着するたびに段階的に処理します。
- Python
- SQL
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
ストリーミングテーブルを作成するには、データセット定義がストリーム型である必要があります。データセット定義でspark.readStream関数を使用すると、ストリーミングデータセットが返されます。
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
ストリーミングテーブルにはストリーミングデータセットが必要です。read_filesの前のSTREAMキーワードは、クエリに対してデータセットをストリームとして扱うように指示します。
Google Cloud Storage (GCS) からファイルを取り込むには、パスを GCS バケットを指すgs:// URI に置き換えてください。
認証を行うには、Unity CatalogでGCSの外部ロケーションを設定してください。Google Cloud Storage (GCS) の外部ロケーションに接続する方法については、こちらをご覧ください。ファイル通知モードを使用する場合は、 Databricks Serviceの認証情報を使用して認証することもできます。 GCPおよびサービス認証情報の作成を参照してください。
ストリーミングメッセージを取り込む
ストリーミングテーブルを使用して、メッセージバスからデータを取り込むこともできます。次の例は、Pub/Subトピックからデータを読み取るストリーミングテーブルを作成する方法を示しています。
- Python
- SQL
@dp.table
def pubsub_raw():
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.option("serviceCredential", "my-service-credential")
.load()
)
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
serviceCredential => 'my-service-credential'
);
Databricksは、Pub/Sub認証にサービス認証情報を使用することを推奨しています。Pub/Sub のサービス認証情報には、Databricks Runtime 16.1 以降が必要です。サービス資格情報の作成を参照してください。
サービス認証情報が利用できない場合は、Google サービス アカウント認証情報を直接渡すことができます。 認証オプションの詳細については、 「Pub/Subへのアクセス設定」を参照してください。
ストリーミング テーブルへのデータのロードの詳細については、 「パイプラインへのデータのロード」を参照してください。
次の図は、追加専用のストリーミング テーブルがどのように機能するかを示しています。
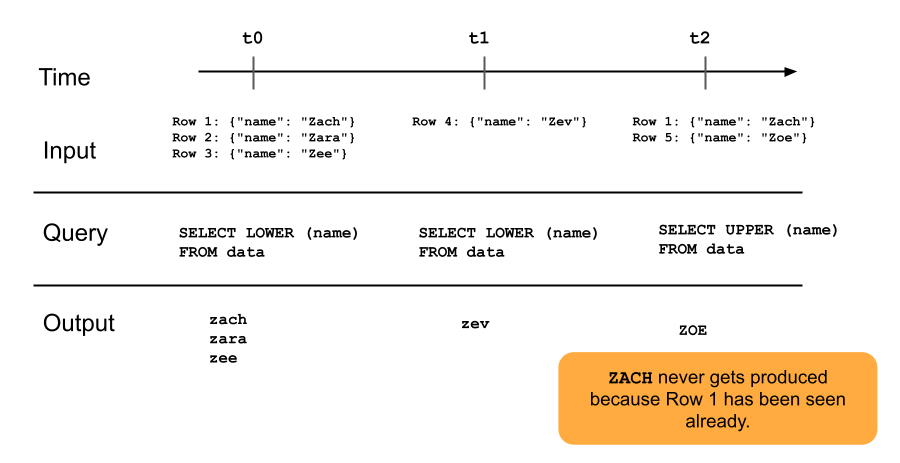
ストリーミングテーブルに既に追加された行は、パイプラインのその後の更新によって再度クエリされることはありません。クエリを変更した場合(例えば、 SELECT LOWER (name)からSELECT UPPER (name)に変更した場合)、既存の行は大文字に更新されませんが、新しい行は大文字になります。ストリーミングテーブルのすべての行を更新するために、ソーステーブルから以前のすべてのデータを再クエリするフルリフレッシュをトリガーできます。
ストリーミングテーブルと低遅延ストリーミング
ストリーミング テーブルは、制限された状態を超えた低遅延のストリーミング用に設計されています。 ストリーミング テーブルはチェックポイント管理を使用するため、低遅延のストリーミングに適しています。 ただし、自然に制限されたストリーム、またはウォーターマークで制限されたストリームが想定されています。
明確に定義された開始点と終了点を持つストリーミングデータソースによって生成されるストリームは、自然に境界が限定されたストリームである。自然に制限されたストリームの例は、ファイルの最初のバッチが配置された後に新しいファイルが追加されていないファイルのディレクトリからデータを読み取ることです。 ファイル数が有限であり、すべてのファイルの処理が完了するとストリームが終了するため、このストリームは有界であると考えられます。
ウォーターマークを使用してストリームをバインドすることもできます。 構造化ストリーミングにおけるウォーターマークは、遅延したイベントをシステムが待機する時間を指定することで、遅延データの処理を支援するメカニズムであり、待機期間が完了したとみなす前に待機すべき時間を指定することで機能します。ウォーターマークのない無制限のストリームは、メモリ負荷によってパイプラインの障害を引き起こす可能性があります。
ステートフル ストリーム処理の詳細については、 「ウォーターマークを使用したステートフル処理の最適化」を参照してください。
ストリームスナップショットの結合
ストリーム - スナップショット結合は、ストリーミング データセットを、ストリームの開始時にスナップショットが作成されるディメンション テーブルに接続します。 その時点ではディメンションテーブルは固定されているとみなされるため、ストリーム開始後にディメンションテーブルに加えられた変更は結合結果に反映されません。これは、小さな差異が問題にならない場合、例えば、取引件数が顧客数よりも桁違いに多い場合などに許容されます。
次のコードサンプルは、 customersという 2 つの行を持つディメンション テーブルと、常に増加するデータセットtransactionsを結合します。これは、 sales_reportと呼ばれるテーブルで、これら 2 つのデータセット間の結合を具体化します。外部プロセスが顧客テーブルに新しい行を追加して更新した場合( customer_id=3, name=Zoya )、ストリームが開始されたときに静的ディメンションテーブルのスナップショットが作成されているため、この新しい行は結合には存在しません。
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
ストリーミングテーブルの制限
ストリーミング テーブルには次の制限があります。
- 限定的な変更: データセット全体を再計算することなく、クエリを変更できます。完全な更新を行わない場合、ストリーミングテーブルは各行を一度しか参照しないため、異なるクエリは異なる行を処理することになります。例えば、クエリ内のフィールドに
UPPER()追加すると、変更後に処理された行のみが大文字になります。つまり、データセット上で実行されているクエリの過去のすべてのバージョンを把握しておく必要があるということです。変更前に処理された既存の行を再処理するには、完全な更新が必要です。 - 状態管理: ストリーミングテーブルは低遅延であり、自然に境界が定められている、またはウォーターマークで境界が定められているストリームを必要とします。詳細については、 「ウォーターマークを使用したステートフル処理の最適化」を参照してください。
- 結合は再計算されません: ストリーミングテーブル内の結合は、ディメンションが変更されても再計算されません。 この特性は、「速いが間違っている」シナリオに適しています。ビューを常に正しく表示する場合は、マテリアライズドビューを使用できます。マテリアライズドビューは、ディメンションが変更されたときに結合を自動的に再計算するため、常に正しいビューです。詳細については、 マテリアライズドビューを参照してください。
CLONEはサポートされていません: ストリーミングテーブルは、ディープクローンまたはシャロークローンのソースまたはターゲットとして使用できません。その他のサポートされていないコマンドについては、制限事項を参照してください。