変更データキャプチャとスナップショット
データ エンジニアは、アナリティクス、レポート、機械学習のために、 Databricksの上流のソース (リレーショナル データベース (Oracle、Postgres、 SQL Server ) など) からDatabricksにデータをレプリケートする必要がよくあります。 運用システムが変更されると、分析テーブルもそれらの変更と同期された状態を維持する必要があります。
チームによっては、レポート作成と分析のために運用データベースの現在の状態を反映する必要があります。 監査可能性、規制要件、顧客分析のために、変更の完全な履歴を保存する必要がある企業もいます。
変更データキャプチャ ( CDC ) は、データベースを完全な静的データベースとしてではなく、一連の変更として扱います。 次の図は、従業員データを含むソース テーブルの行が更新されると、変更 のみ を含む CDC フィードに新しい行セットが生成されることを示しています。CDC フィード の各行には通常、 UPDATEなどの操作や、順序どおりでない更新を処理できるように CDC フィード内の各行を確定的に順序付けるために使用できる列などの追加のメタデータが含まれます。たとえば、次の図のsequenceNum列は CDC フィード内の行の順序を決定します。
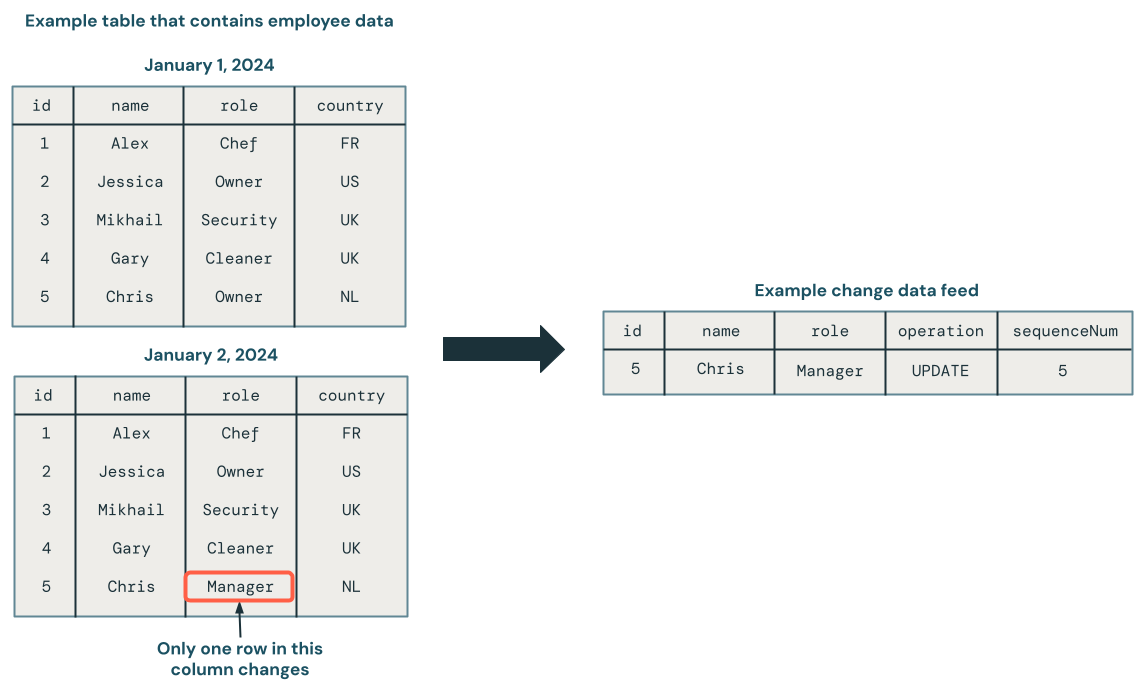
CDC を使用すると、下流のシステムでデータベースを更新するときに、より単純なトランザクションのデータの変更のみを表示できます。必要に応じて、データベースの履歴を確認することもできます。
課題は、ソース システムが異なる形式でデータを提供することです。一部は、個々の変更 (挿入、更新、削除) をキャプチャする変更フィードを発行します。その他は、テーブル全体の定期的なスナップショットのみを提供します。ダウンストリーム テーブルを正確かつ最新の状態に保つには、形式ごとに異なる処理方法が必要です。
これまで、チームは変更フィードから、またはスナップショットの比較によって、これらの変更を適用するためにカスタムMERGE INTOロジックに依存してきました。このアプローチは複雑でエラーが発生しやすく、ステージング テーブル、ウィンドウ関数、およびシーケンスの想定が必要となり、パイプラインが進化するにつれて、それらを判断して維持することが困難になります。
このページでは、2 つの CDC 形式 (SCD タイプ 1 とタイプ 2)、CDC の詳細、ソース データが CDC をサポートしていない場合でもスナップショットを使用して CDC の利点を活用する方法について説明します。
CDC の利点は何ですか?
変更データ キャプチャは、ワークロードにいくつかの利点をもたらします。
- 変更データは通常、完全なデータ セットよりも小さく、変更は下流のクエリによってデータの増分更新として処理できます。
- 変更データは、特定の時点のレコードを再構築できるような方法で保存できるため、監査、ポイントインタイムレポート、傾向分析のための完全な履歴が得られます。
- データを変更すると、時間の経過とともに安定した代理キーが可能になります。
変更の適用方法: 現在の状態または変更の完全な履歴
緩やかに変化するディメンション ( SCD ) は、上流の変更が分析テーブルに反映された後に、どのように適用され、モデル化されるかを定義します。 組織はデータのニーズに応じてさまざまなアプローチを使用する場合があります。SCD タイプ 1 では、データセットの現在の状態のみを保存できます。SCD タイプ 2 は、データセットへの変更の完全な履歴を保存します。このセクションではこれらについて詳しく説明します。
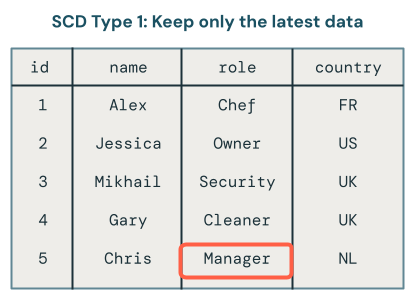
SCD タイプ 1: 現在の状態のみ
SCD タイプ 1 は、変更が発生するたびに古いデータを新しいデータで上書きし、各レコードの最新バージョンのみを保持します。履歴は保持されません。
SCD タイプ 1 は次の場合に使用します。
- 必要なのはデータの現在の状態だけです。
- ダウンストリームのマテリアライズドビューを完全に再計算するのではなく、段階的に更新したいとします。
- 結合には安定した代理キーが必要です。
SCD1 では最新バージョンのデータのみが利用可能です。これは、最終的なテーブルのみを保存すると考えることができる簡単なアプローチです。レコードがOwnerからManager,に変更された場合、テーブルにはManagerのみが残ります。
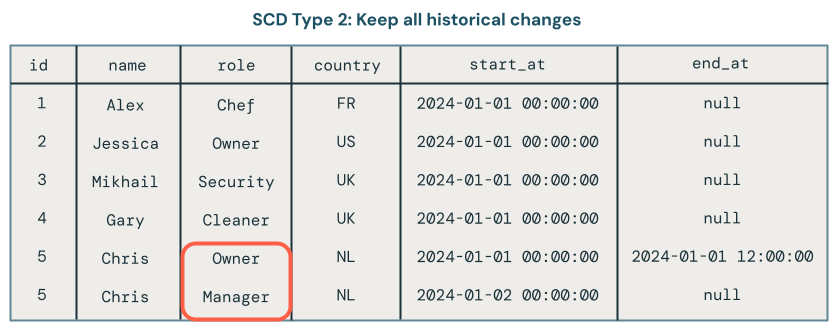
SCDタイプ2: 履歴追跡
SCD タイプ 2 は、時間の経過とともに複数のデータ バージョンを作成し、各バージョンにメタデータのタイムスタンプを付けることで、完全な履歴記録を維持します。__START_AT列と__END_AT列は、レコードの各バージョンの有効期間を定義します。アクティブレコードは__END_AT = NULLです。いつでもデータセットの状態を表示できます。
SCD タイプ 2 は次の場合に使用します。
- 監査または規制の要件により、履歴の追跡が必要になります。
- 顧客分析では、エンティティが時間の経過とともにどのように進化したかを理解する必要があります。
- ビジネス ロジックでは、ポイントインタイム レポートが必要です。
- 傾向を分析したり、過去の状態を比較したりする必要があります。
SCD タイプ 2 処理では、データ変更の履歴記録が保持されます。たとえば、現在レコードのロール フィールドがManagerに設定されている場合、そのロールが以前はOwnerに設定されていたことも確認できます。次の画像では、まさにそれがChrisレコードに起こったことです。現在のレコードは、 end_atフィールドにnull値があるためわかります。
CDC フィードとは何ですか?
変更データキャプチャ ( CDC ) は、ソース システム内のデータに加えられた変更 (挿入、更新、削除) をキャプチャするデータ統合パターンです。 CDC はデータセット全体を処理するのではなく、変更されたレコードのみを含むフィードを生成します。
たとえば、Oracle に 50 行の従業員テーブルがあり、1 人の従業員の ジョブ タイトルが変更された場合、 CDCフィードにはその従業員の 1 つのUPDATEレコードが含まれます。 これにより、Databricks は実行のたびにソース テーブル全体を読み取るのではなく、変更されたレコードのみを処理できるようになります。
ソース データベースの各 CDC レコードには次の内容が含まれます。
- 操作タイプ (
INSERT、UPDATE、DELETE) - レコードのデータ値
- 決定論的な順序付けのためのシーケンス番号またはタイムスタンプ
シーケンス番号により、遅れた到着や順序どおりに届かない到着が正しく適用されることが保証されます。SQL Server、MySQL、Oracle などのトランザクション データベースは、CDC フィードをネイティブに生成します。Deltaテーブルは、変更データフィード (CDF) と呼ばれる独自のCDCフィードも生成するため、 Deltaソースからの変更も簡単に処理できます。
スナップショットとは何ですか?
スナップショットは、特定の時点におけるテーブルの完全な状態を表します。変更のみをキャプチャする CDC フィードとは異なり、スナップショットにはソース テーブルのすべての行が含まれます。
チームはさまざまな理由から、運用データベースで CDC フィードを常に有効にするとは限りません。
- コスト ( CDC本番運用データベースの負荷が増加する可能性があります)
- ソースデータベースのパフォーマンスに関する懸念
- CDCをサポートしていないレガシーシステム
- 組織的な制約(取り込みを管理するチームは上流のデータベースを所有していない)
変更フィードが利用できない場合は、スナップショットベースの取り込みが唯一のオプションとなります。スナップショットは次の場所から取得されます:
- リレーショナル データベース (Oracle、Postgres、SQL Server) からの定期的なエクスポート
- 上流システムからのクラウドストレージファイルダンプ
- Deltaテーブル (各テーブルバージョンは実質的にスナップショットです)
- 上流テナントからのDelta Sharing
スナップショットではレコード レベルの変更がキャプチャされないため、何が変更されたかを識別するには、スナップショット間でレコードを比較して、挿入、更新、削除を推測する必要があります。
CDCフィードを自動処理
Databricks 、 LakeFlow Spark宣言型パイプライン内のAUTO CDC APIを通じてCDC処理を簡素化します。 このAPI 、変更データフィードが有効になっているソース データベースまたはDeltaテーブル上のCDCフィードからの変更を処理するように設計されています。
次のいずれかに該当する場合はAUTO CDC使用します。
- ソース システムは変更データフィード (CDF) を生成します
- データチェンジフィードが有効になっているDeltaテーブルから読み取りを行っています
- リレーショナル データベースからの CDC フィードがある (Debezium や Oracle GoldenGate などのツール経由)
AUTO CDC シーケンス列で定義された順序でイベントを処理することにより、順序どおりに実行されないレコードを自動的に処理します。シーケンス列は、正しいイベント順序の単調に増加する表現である必要があり、各シーケンス値のキーごとに 1 つの異なる更新が必要です。NULLシーケンス値はサポートされていません。SCDタイプ 2 の場合、 LakeFlow Spark宣言型パイプラインは、シーケンス値をターゲット テーブルの__START_AT列と__END_AT列に伝播します。
初期ハイドレーション: 既存の運用データベース テーブルをDatabricksにレプリケートする場合、進行中の変更を処理する前に、まずすべての履歴データをロードする必要があります。 AUTO CDC 、利用可能なすべてのデータを 1 回処理して停止するモードで ある 1 回限りのフロー を通じてこれをサポートします。初期ロードが完了したら、進行中の CDC 処理にトリガー モードまたは連続モードのフローを使用します。これにより、一括ロードと増分ロードの両方で一貫したロジックが保証されます。
スナップショットを自動処理する
CDC フィードが利用できない場合、Databricks はAUTO CDC FROM SNAPSHOT API を提供します。このAPIはスナップショットベースの取り込み用に設計されています。 連続するスナップショット を比較し、合成変更フィードを生成し、 SCDタイプ 1 またはタイプ 2 ロジックをターゲット テーブルに適用します。 ターゲット テーブルは、ダウンストリーム クエリに対してSCDタイプ 1 またはタイプ 2 のCDCフィード ( Deltaテーブルでは 変更データフィード (CDF) と呼ばれる) を提供できます。
AUTO CDC FROM SNAPSHOT Python パイプライン インターフェースでのみサポートされます。スナップショットはバージョンごとに昇順で処理する必要があります。順序が乱れたスナップショットが検出された場合、それは無視されます。 AUTO CDC FROM SNAPSHOTデータセットの出力をクエリするマテリアライズドビューなどのダウンストリーム処理では、増分化機能や安定した代理キーなどのCDCの利点が得られます。
AUTO CDC FROM SNAPSHOT 初期ロードだけのものではありません。スナップショットが唯一使用可能な形式である場合の継続的な処理用に設計されています。新しいスナップショットが到着するたびに、 APIそれを前のスナップショットと比較して、変更と変更データフィードを導出します。
次の場合にAUTO CDC FROM SNAPSHOTを使用します:
- ソースデータベースでCDCが有効になっていません
- 定期的なスナップショット(完全なテーブルダンプ)にのみアクセスできます。
- 増分処理に CDC の利点を活用したい場合、または変更の完全な履歴を保持したい場合。
AUTO CDC FROM SNAPSHOT 次のことを自動的に処理します。
- 連続するスナップショットを比較して、挿入、更新、および削除されたレコードを識別します。
- スナップショット間の相違に基づいて合成変更フィードを生成します。
AUTO CDCと同じSCDロジックをコンピュートSCD Type 1 または Type 2 に適用します。
AUTO CDC FROM SNAPSHOT あるスナップショットから次のスナップショットへの変更のみを認識し、中間の変更は取得しません。たとえば、毎日スナップショットを取得し、ユーザーが 1 日のうちに住所を 2 回変更した場合 ( AからBへ、次にBからCへ)、その時点のスナップショットのみを受信したため、変更フィードはAからCに直接送信される可能性があります。
スナップショット処理パターン
AUTO CDC FROM SNAPSHOT スナップショットのバージョンを決定するための 2 つのパターンをサポートします。
パイプライン取り込み時間を使用したスナップショット処理
スナップショットはパイプラインの実行時に読み取られ、取り込み時間がスナップショットのバージョンとして使用されます。パイプラインが更新されるたびに、新しいスナップショットが取り込まれます。パイプラインが連続モードで実行されると、フローのトリガー間隔設定に基づいて複数のスナップショットが取り込まれます。
スナップショットが定期的かつ順番に到着し、バージョン管理にパイプライン実行タイムスタンプを利用できる場合は、このパターンを使用します。
バージョン関数を使用したスナップショット処理
パイプラインの実行時に処理するスナップショット バージョンを指定する関数を提供します。関数はタプル(DataFrame, version_number)を返します。API はバージョン番号で定義された順序でスナップショットを処理します。順序が正しくないスナップショットが検出された場合、そのスナップショットは無視されます。
このパターンは次の場合に使用します。
- 複数のスナップショットが同時に到着する可能性があり、順次処理が必要になります。
- スナップショットは順序どおりに到着しない場合があります。
- スナップショットの順序を明示的に制御する必要があります。
CDCの追加機能
AUTO CDCターゲットに対する変更操作
標準のストリーミング テーブルとは異なり、 AUTO CDCターゲットであるUnity Catalogテーブルは、パイプラインの実行中であっても、 INSERT 、 UPDATE 、 DELETE 、およびMERGEステートメントをサポートします。 詳細と制限については、 「ターゲット ストリーミング テーブルのデータの追加、変更、または削除」を参照してください。
AUTO CDCターゲットからの変更データフィードの読み取り
AUTO CDC target ストリーミング テーブルは独自の変更データフィード (CDF) を発行できるため、ダウンストリーム パイプラインがAUTO CDC出力からの変更を消費できるようになります。 詳細については、 「AUTO CDCターゲット テーブルから変更データフィードを読み取る」を参照してください。
メトリクスとモニタリング
AUTO CDC パイプライン実行ごとに、 num_upserted_rowsとnum_deleted_rowsメトリクスを自動的にキャプチャします。 詳細については、 「高度な AUTO CDC トピック」を参照してください。
SCD タイプ 2 の列サブセットの追跡
デフォルトでは、SCD タイプ 2 は列の値が変更されるたびに新しいバージョンを作成します。AUTO CDC使用すると、履歴を追跡する列を指定できるため、追跡されていない列に変更を加えると、新しい履歴レコードが作成されるのではなく、現在のバージョンがそのまま更新されます。これにより、重要な属性の履歴を保持しながら、ストレージ コストとクエリの複雑さが軽減されます。例については、 「SCD タイプ 2 で列のサブセットを追跡する」を参照してください。
推奨事項
たとえば、ダウンストリームのマテリアライズドビューを段階的に更新できるようにするなど、データへの変更のみを操作したい場合は、変更データキャプチャ ( CDC ) を使用します。 また、特定の時点で誰がどのような役割を担っていたかを知るためなど、データの変更履歴を保持する場合にも CDC を使用します。
アップストリーム データをDatabricksに複製し、ソースの変更と同期させる必要がある場合は、AUTO CDC APIs使用します。 適切な API は、ソース システムがどのように変更を公開するかによって異なります。
- ソースが変更フィードを発行する場合には、
AUTO CDC使用します 。たとえば、 CDCが有効になっているリレーショナル データベース (Debezium や Oracle GoldenGate などのツール経由)、変更データフィードが有効になっているDeltaテーブル、またはシーケンス列を使用して挿入、更新、削除のストリームを生成するソースなどです。 - ソースが CDC をサポートしておらず、定期的な完全なテーブル ダンプのみを提供する場合は、
AUTO CDC FROM SNAPSHOTを使用します 。この API は、連続するスナップショットを比較することで変更を推測し、合成変更フィードを生成するため、ネイティブ CDC フィードがなくても同じ SCD 処理の利点が得られます。
どちらの場合も、各レコードの現在の状態のみが必要な場合は SCD タイプ 1 を選択し、監査、ポイントインタイム レポート、または傾向分析のために変更の完全な履歴を保持する必要がある場合は SCD タイプ 2 を選択します。
次のステップ
- AUTO CDC APIs : パイプラインによる変更データ キャプチャの簡素化:
AUTO CDCおよびAUTO CDC FROM SNAPSHOTAPIsを使用してCDC実装する方法を学びます。 - 高度な AUTO CDCトピック: DML 操作の使用、チェンジデータフィードの読み取り、モニタリング メトリクスなどの高度なCDCトピックについて学びます。